在今年的早期时候,我尝鲜了面向个人开发者的ai超级计算机——技嘉ai top atom。要知道,该主机尺寸仅为150mm x 150mm x 50.5mm,这对于需要在办公桌、工作室等环境中使用的开发者来说,这种形态几乎没有什么部署门槛,只需要网络和供电就行,可以说将桌面化做到了极致。
本次分享的技嘉 ai top atom 正是基于上述理念打造的个人 ai 超级电脑,它搭载了 nvidia 与联发科合作设计的 gb10 grace blackwell 超级芯片。专为个人开发者、数据科学家及 ai 研究人员打造,打破了顶级算力必须依赖云端或大型机房的局限,在保持便携性的同时,为本地 ai 推理与微调提供了极具弹性的解决方案。

硬件赏析及配置
▼简单看看这台设备吧,尺寸方面,技嘉 ai top atom 和大部分迷你主机差不多,准确数据为 150 x 150 x 50.5mm,枪灰色的金属机身,表面没有任何装饰,主打沉稳简洁,下图是和 macmini m4 的对比。


▼配件方面包括主机和电源适配器,接口走的 type-c,支持 pd3.1 快充协议,最大输出功耗 240w,理论来说用氮化镓充电器也能推。

▼主机正面没有任何冗余接口,视觉上极为干练,仅点缀以技嘉英文 logo。通体贯穿的 mesh 散热网孔若隐若现,这种“全面透气”的构造显然是为了应对 gb10 超级芯片在高强度算力输出下的散热需求,确保气流能毫无阻碍地带走内部热量。

▼接口配置上,技嘉 ai top atom走的是极致精简且高效的路线。侧边集成了 4 枚 type-c 接口(含电源输入口)与 hdmi 2.1 高清接口,能够满足日常所有的外设接入与显示需求。而 10g 万兆网口的加入,则确保了在局域网内传输海量训练数据集时的吞吐效率。

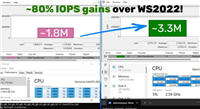
▼最右边的则是普通用户很少见到的 nvidia connectx-7 智能网卡。这原本是数据中心级设备才拥有的专属组件,它支持高达 400 gb/s 的传输速率,几乎消除了数据交换的物理屏颈。更重要的是,它不仅能提供惊人的 400 gb/s 超高带宽与极低延迟,而且支持将两台 ai top atom 串联为算力集群。利用双机共享算力和内存实现 1+1>2 的性能飞跃,让本地处理数千亿参数的超大规模模型成为可能。

▼拆机还是比较简单的,固定螺丝隐藏在机身底部的胶条下。

▼揭开底盖后是两根布局独特的 wifi 天线。在如此紧凑的空间内采取这种安置方式确实不多见,显然是为了规避内部复杂电子元器件的信号干扰,确保无线连接的稳定性。

▼内部的散热规格堪称“暴力”。为了压制 gb10 超级芯片的惊人算力,它配备了双涡轮(blower)风扇阵列,搭配厚度极其扎实的散热鳍片组。结合其全铝合金外壳的物理导热特性,这套散热方案即便是在 7x24 小时的 ai 满载训练任务下,也能提供令人心安的冷酷表现。



发表评论