一、前言
1.1 什么是慢查询日志
慢查询日志是mysql提供的一种性能诊断工具,用于记录执行时间超过指定阈值的sql语句。通过分析这些“慢sql”,可以精准定位数据库性能瓶颈,优化索引、sql写法或表结构。
1.2 基础知识要求
- mysql基础:熟悉配置文件、基本sql命令
- 权限要求:需要
super或process权限查看运行状态 - 运维经验:了解磁盘空间、日志轮转等基本概念
二、慢查询日志的开启方式
2.1 临时开启(当前会话/全局,重启失效)
-- 查看当前慢查询状态 show variables like '%slow_query%'; show variables like '%long_query_time%'; -- 开启慢查询日志(全局,立即生效,重启失效) set global slow_query_log = on; -- 设置慢查询阈值(秒),建议设为0.1~2秒之间 set global long_query_time = 1; -- 设置日志文件路径(可选,默认在数据目录下) set global slow_query_log_file = '/var/lib/mysql/slow-query.log'; -- 设置未使用索引的sql也记录 set global log_queries_not_using_indexes = on;
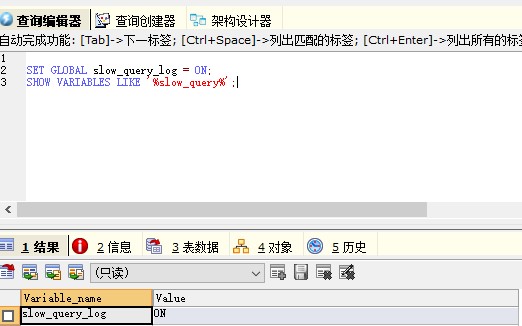
2.2 永久开启(修改配置文件)
linux/mac:/etc/my.cnf 或 /etc/mysql/my.cnf
windows:my.ini
[mysqld] # 开启慢查询日志 slow_query_log = 1 # 日志文件路径 slow_query_log_file = /var/lib/mysql/slow-query.log # 慢查询阈值(秒) long_query_time = 1 # 记录未使用索引的查询 log_queries_not_using_indexes = 1 # 日志输出格式(file或table,默认file) # log_output = file
配置完成后重启mysql服务:
# systemctl sudo systemctl restart mysqld # service sudo service mysql restart
三、参数解析
| 参数 | 类型 | 默认值 | 说明 | 建议值 |
|---|---|---|---|---|
slow_query_log | boolean | off | 是否开启慢查询日志 | on(生产环境建议开启) |
long_query_time | float | 10.0 | 慢查询阈值(秒) | 1~2秒(业务敏感可设为0.5) |
slow_query_log_file | string | hostname-slow.log | 日志文件路径 | 独立目录,便于监控 |
log_queries_not_using_indexes | boolean | off | 是否记录未使用索引的查询 | on(找出索引缺失的sql) |
log_output | enum | file | 日志输出方式 | file 或 table |
min_examined_row_limit | integer | 0 | 扫描行数超过此值才记录 | 1000(过滤小表扫描) |
log_slow_admin_statements | boolean | off | 是否记录慢管理语句(如optimize) | on(全面监控) |
四、慢查询日志分析工具
4.1 使用mysqldumpslow工具
mysql自带日志分析工具,可对慢查询日志进行聚合统计。
# 基本用法 mysqldumpslow /var/lib/mysql/slow-query.log # 常用参数 mysqldumpslow -s t -t 10 /var/lib/mysql/slow-query.log # 按查询时间排序,取前10条 mysqldumpslow -s c -t 10 /var/lib/mysql/slow-query.log # 按执行次数排序 mysqldumpslow -s r -t 10 /var/lib/mysql/slow-query.log # 按返回行数排序 mysqldumpslow -a /var/lib/mysql/slow-query.log # 不抽象数字,显示具体sql
4.2 使用pt-query-digest(percona toolkit)
更强大的第三方分析工具,提供详细的统计报告。
# 安装percona-toolkit # ubuntu/debian sudo apt-get install percona-toolkit # centos/rhel sudo yum install percona-toolkit # 分析慢查询日志 pt-query-digest /var/lib/mysql/slow-query.log > slow_report.txt # 分析当前运行的查询(实时) pt-query-digest --processlist h=localhost,u=root,p=password
五、实际案例:电商订单慢查询优化
5.1 案例背景
某电商平台订单表orders,数据量约500万行,业务反馈订单列表页面加载缓慢(超过5秒),需要定位并优化。
5.2 步骤一:开启慢查询并复现问题
-- 临时开启慢查询记录阈值0.5秒 set global slow_query_log = on; set global long_query_time = 0.5; set global log_queries_not_using_indexes = on; -- 确认日志文件位置 show variables like 'slow_query_log_file'; -- 结果:/var/lib/mysql/slow-query.log
执行慢的订单查询sql:
select
o.order_id,
o.user_id,
o.order_amount,
o.order_status,
o.created_at,
u.user_name,
u.phone
from orders o
left join users u on o.user_id = u.user_id
where o.order_status = 'pending'
and o.created_at >= '2024-01-01'
and o.created_at < '2024-02-01'
order by o.created_at desc
limit 20;5.3 步骤二:分析慢查询日志
# 查看慢查询日志 mysqldumpslow -s t -t 5 /var/lib/mysql/slow-query.log
日志输出:
count: 156 time=3.52s (549s) lock=0.01s (1.56s) rows_sent=20.0 (3120), rows_examined=5234567.0 (816m), root[root]@localhost select o.order_id, o.user_id, o.order_amount, o.order_status, o.created_at, u.user_name, u.phone from orders o left join users u on o.user_id = u.user_id where o.order_status = 's' and o.created_at >= 'yyyy-mm-dd' and o.created_at < 'yyyy-mm-dd' order by o.created_at desc limit n
关键信息:
- 平均耗时:3.52秒
- 平均扫描行数:523万行(几乎全表扫描)
- 执行次数:156次,总耗时549秒
5.4 步骤三:使用explain分析执行计划
explain select
o.order_id,
o.user_id,
o.order_amount,
o.order_status,
o.created_at,
u.user_name,
u.phone
from orders o
left join users u on o.user_id = u.user_id
where o.order_status = 'pending'
and o.created_at >= '2024-01-01'
and o.created_at < '2024-02-01'
order by o.created_at desc
limit 20\gexplain结果:
| id | select_type | table | type | possible_keys | key | key_len | rows | extra |
|---|---|---|---|---|---|---|---|---|
| 1 | simple | o | all | idx_created_at | null | null | 5,234,567 | using where; using filesort |
| 1 | simple | u | eq_ref | primary | primary | 4 | 1 | null |
问题诊断:
- type=all:orders表全表扫描,未使用任何索引
- rows≈523万:扫描全部数据行
- extra包含using filesort:order by需要额外排序,无法利用索引
- possible_keys显示idx_created_at:虽然有created_at索引,但优化器未选择
5.5 步骤四:深入分析索引失效原因
-- 查看orders表现有索引 show index from orders;
现有索引:
- primary key (
order_id) - index idx_user_id (
user_id) - index idx_created_at (
created_at) - index idx_status (
order_status)
索引失效分析:
- where条件包含
order_status和created_at两个字段 - mysql优化器判断使用任一单列索引都需要回表过滤另一个条件,扫描行数依然很大
- 最终选择了全表扫描
5.6 步骤五:制定优化方案
方案一:创建联合索引(推荐)
-- 创建联合索引,将等值查询字段放前面,范围查询放后面 create index idx_status_created on orders (order_status, created_at); -- 验证索引效果 explain select ...(同原sql)\g
优化后explain结果:
| table | type | key | key_len | rows | extra |
|---|---|---|---|---|---|
| o | range | idx_status_created | 102 | 185,000 | using where; using index condition |
| u | eq_ref | primary | 4 | 1 | null |
优化效果:
- 扫描行数从523万降到18.5万(减少96.5%)
- 执行时间从3.5秒降至0.08秒
方案二:使用覆盖索引(进一步优化)
-- 创建覆盖索引,避免回表查询 -- 注意: -- 创建索引需要在线上业务停止时进行,避免死锁 -- 覆盖索引需要包含所有查询字段 -- 重建索引可能需要很长时间,可能破坏数据,建议先备份数据 create index idx_status_created_cover on orders (order_status, created_at, order_id, user_id, order_amount); -- 但orders表字段较多,覆盖索引可能过大,需权衡
方案三:sql语句改写
-- 使用子查询先筛选出订单id,再关联用户表
select
o.order_id,
o.user_id,
o.order_amount,
o.order_status,
o.created_at,
u.user_name,
u.phone
from (
select order_id, user_id, order_amount, order_status, created_at
from orders
where order_status = 'pending'
and created_at >= '2024-01-01'
and created_at < '2024-02-01'
order by created_at desc
limit 20
) o
left join users u on o.user_id = u.user_id;5.7 步骤六:验证优化效果
再次查看慢查询日志
mysqldumpslow -s t -t 5 /var/lib/mysql/slow-query.log
优化后日志
优化成果总结:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 平均耗时 | 3.52秒 | 0.08秒 | 97.7% ↓ |
| 扫描行数 | 523万 | 18.5万 | 96.5% ↓ |
| 总耗时/天 | 549秒 | 12.5秒 | 97.7% ↓ |
六、更多实际案例
6.1 案例二:隐式类型转换导致索引失效
问题sql:
sql
-- phone字段定义为varchar(20),但传入数字类型 select * from users where phone = 13800138000;
explain分析:


- type=all,key=null,rows=全表
原因:mysql将phone字段自动转换为数字类型,导致索引失效
优化:
-- 正确写法,传入字符串 select * from users where phone = '13800138000';
6.2 案例三:函数操作导致索引失效(和mysql版本有关系)
问题sql:
select * from orders where date(created_at) = '2024-01-15';

优化:
select * from orders where created_at >= '2024-01-15' and created_at < '2024-01-16';
6.3 案例四:分页查询深度过大
问题sql:
-- 第10000页,每页20条 select * from orders order by order_id limit 200000, 20;
优化方案(延迟关联):
select * from orders o
inner join (
select order_id from orders
order by order_id
limit 200000, 20
) t on o.order_id = t.order_id;七、生产环境最佳实践
7.1 慢查询阈值设置建议
- oltp系统(高并发):
0.5~1秒 - olap系统(分析查询):
2~5秒 - 核心交易链路:
0.1~0.3秒(配合监控告警)
7.2 日志管理
- 定期轮转,避免占满磁盘
- 使用
logrotate工具管理日志 - 生产环境建议将
log_output设为table,便于sql查询分析
-- 将日志输出到mysql.slow_log表 set global log_output = 'table'; -- 查询慢日志表 select * from mysql.slow_log where query_time > 2 order by start_time desc limit 10;
7.3 监控告警
- 接入prometheus/grafana,监控慢查询数量趋势
- 设置告警:每分钟慢查询数 > 10 或 某sql耗时 > 5秒
7.4 慢查询分析流程总结
开启慢查询 → 收集日志 → 分析top慢sql → explain执行计划 → 定位问题
↑ ↓
监控告警 ← 验证效果 ← 上线变更 ← 制定优化方案 ← 索引失效/扫描行数多八、学习建议
- 循序渐进:先从
mysqldumpslow入手,掌握基础分析后再引入pt-query-digest - 结合explain:每个慢sql都要用
explain分析,理解mysql优化器的选择 - 建立知识库:记录常见慢查询模式及优化方案(隐式转换、函数操作、排序问题等)
- 预防为主:上线前通过
explain审核新sql,避免慢查询流入生产 - 定期巡检:每周分析慢查询日志,发现潜在性能隐患
以上就是mysql慢查询开启与优化指南的详细内容,更多关于mysql慢查询开启与优化的资料请关注代码网其它相关文章!




发表评论