1. 引言
在日常办公中,企业和个人经常需要处理大量的发票数据,包括提取发票代码、发票号码、开票日期、金额等关键信息。手动录入这些信息费时费力,因此自动化发票信息提取成为刚需。
本文将介绍如何利用 openai api 和 pymupdf (即 fitz) 实现 pdf 发票的自动信息提取。代码将解析 pdf 文件内容,并通过 ai 模型精准提取相关字段。
2. 依赖环境
在实现该功能之前,需要安装以下 python 依赖库:
pip install openai pymupdf
此外,需要在 config.py 中配置 api key 及 pdf 文件路径。
3. 代码实现
完整代码如下:
from openai import openai
import fitz # pymupdf
import config # 需要配置api key和pdf路径
def get_pdf_text(pdf_path):
doc = fitz.open(pdf_path)
markdown_text = ""
for page_num in range(len(doc)):
page = doc[page_num]
blocks = page.get_text("dict")["blocks"]
for block in blocks:
if "lines" in block:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
markdown_text += f"{text}"
markdown_text += "\n"
return markdown_text
def create_invoice_extraction_prompt(invoice_text):
prompt = f"""
请分析以下发票文本,准确提取以下信息:
1. 发票代码
2. 发票号码
3. 开票日期
4. 价税合计的小写金额
5. 销售方名称
6. 消费类型(如:餐饮、交通、办公用品、通讯等)
请务必仔细分析商品或服务内容,据此判断消费类型。
如果无法确定某项信息,请标注为"未找到"。
发票文本:
{invoice_text}
请以 json 格式返回结果:
{{
"发票代码": "",
"发票号码": "",
"开票日期": "",
"价税合计": "",
"销售方名称": "",
"消费类型": ""
}}
"""
return prompt
# 初始化 openai 客户端
client = openai(
api_key=config.dashscope_api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
sample_invoice_text = get_pdf_text(config.pdf_path)
# 创建聊天完成请求
completion = client.chat.completions.create(
model="qwq-32b", # 可按需更换模型名称
messages=[
{"role": "user", "content": create_invoice_extraction_prompt(sample_invoice_text)}
],
stream=true,
)
reasoning_content = "" # 记录思考过程
answer_content = "" # 记录最终答案
is_answering = false # 标记是否已进入回复阶段
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in completion:
if not chunk.choices:
print("\nusage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
print(delta.reasoning_content, end='', flush=true)
reasoning_content += delta.reasoning_content
else:
if delta.content and not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = true
print(delta.content, end='', flush=true)
answer_content += delta.content
print("\n\n" + "=" * 50)
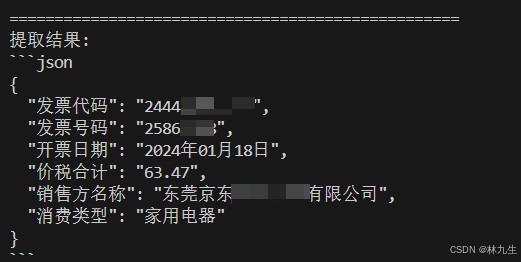
print("提取结果:")
print(answer_content)
4. 运行示例
5. 总结
通过本文的介绍,我们实现了一个基于 openai api 解析 pdf 发票的完整流程,包括:
- 使用 pymupdf 解析 pdf 文本
- 构造 ai 提示词,让大模型精准提取发票信息
- 调用 openai api 并解析返回 json 结果
这一方案可以广泛应用于财务报销、企业票据管理等场景,极大提高工作效率。如果你有更复杂的需求,可以尝试调整 prompt 或使用更强大的 llm 模型。
扩展代码(金额提取不稳定)
import fitz # pymupdf
import requests
import json
import base64
import os
import re
import glob
import shutil # 添加这行用于文件复制
import traceback # 添加这行用于异常处理
from loguru import logger
def pdf_to_images(pdf_path, output_dir="images", dpi=150):
"""
将pdf转换为图片
args:
pdf_path (str): pdf文件路径
output_dir (str): 输出目录
dpi (int): 图片分辨率
returns:
list: 生成的图片文件路径列表
"""
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 打开pdf文件
pdf_document = fitz.open(pdf_path)
image_paths = []
# 获取pdf文件名(不含扩展名)
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
# 遍历每一页
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
# 设置缩放矩阵以控制分辨率
mat = fitz.matrix(dpi/72, dpi/72)
# 渲染页面为图片
pix = page.get_pixmap(matrix=mat)
# 保存图片,文件名包含pdf名称
image_path = os.path.join(output_dir, f"{pdf_name}_page_{page_num + 1}.png")
pix.save(image_path)
image_paths.append(image_path)
pdf_document.close()
return image_paths
def image_to_base64(image_path):
"""
将图片转换为base64编码
args:
image_path (str): 图片文件路径
returns:
str: base64编码的图片数据
"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def analyze_image_with_qwen(image_path, prompt="请描述这张图片的内容", ollama_url="http://192.168.1.2:11434"):
"""
使用ollama api的qwen2.5vl:3b模型分析图片
args:
image_path (str): 图片文件路径
prompt (str): 分析提示词
ollama_url (str): ollama服务器地址
returns:
str: 模型分析结果
"""
# 将图片转换为base64
image_base64 = image_to_base64(image_path)
# 构建请求数据
data = {
"model": "qwen2.5vl:3b",
"prompt": prompt,
"images": [image_base64],
"stream": false
}
try:
# 发送请求到ollama api
response = requests.post(
f"{ollama_url}/api/generate",
json=data,
headers={"content-type": "application/json"}
)
if response.status_code == 200:
result = response.json()
return result.get("response", "无法获取分析结果")
else:
return f"api请求失败,状态码: {response.status_code}"
except requests.exceptions.requestexception as e:
logger.info(f"####{response.text}")
return f"请求异常: {str(traceback.format_exc())}"
def get_pdf_files(source_dir):
"""
获取目录中的所有pdf文件
args:
source_dir (str): 源目录路径
returns:
list: pdf文件路径列表
"""
pdf_files = []
# 支持的pdf文件扩展名
pdf_extensions = ['*.pdf']
for extension in pdf_extensions:
pattern = os.path.join(source_dir, '**', extension)
pdf_files.extend(glob.glob(pattern, recursive=true))
return sorted(pdf_files)
def copy_and_rename_pdf(original_pdf_path, output_dir, new_filename):
"""
复制pdf文件到指定目录并重命名
args:
original_pdf_path (str): 原始pdf文件路径
output_dir (str): 输出目录
new_filename (str): 新文件名(不含扩展名)
returns:
str: 新文件的完整路径
"""
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 清理文件名中的非法字符
safe_filename = re.sub(r'[<>:"/\\|?*]', '_', new_filename)
# 构建新的文件路径
new_pdf_path = os.path.join(output_dir, f"{safe_filename}.pdf")
try:
# 复制文件
shutil.copy2(original_pdf_path, new_pdf_path)
logger.info(f"pdf文件已复制并重命名为: {new_pdf_path}")
return new_pdf_path
except exception as e:
logger.info(f"复制pdf文件时出错: {str(e)}")
return none
def analyze_with_qwen3_32b(analysis_text, extra_prompt, ollama_url="http://192.168.1.2:11434"):
"""
使用qwen3:32b模型进行二次分析和格式化
args:
analysis_text (str): 第一次分析的结果
extra_prompt (str): 格式化提示词
ollama_url (str): ollama服务器地址
returns:
str: 格式化后的结果
"""
# 构建完整的提示词
full_prompt = f"{extra_prompt}\n\n基于以下发票分析结果:\n{analysis_text}\n\n请按照上述格式要求输出:/no_think"
# 构建请求数据
data = {
"model": "qwen3:32b",
"prompt": full_prompt,
"stream": false
}
try:
# 发送请求到ollama api
response = requests.post(
f"{ollama_url}/api/generate",
json=data,
headers={"content-type": "application/json"}
)
if response.status_code == 200:
result = response.json()
return result.get("response", "无法获取格式化结果").strip()
else:
return f"api请求失败,状态码: {response.status_code}"
except requests.exceptions.requestexception as e:
return f"请求异常: {str(e)}"
def process_single_pdf(pdf_path, output_dir, analysis_prompt):
"""
处理单个pdf文件
args:
pdf_path (str): pdf文件路径
output_dir (str): 输出目录
analysis_prompt (str): 分析提示词
returns:
dict: 处理结果
"""
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
logger.info(f"\n开始处理pdf文件: {pdf_name}")
# 为每个pdf创建独立的图片目录
images_dir = os.path.join(output_dir, "images", pdf_name)
# 1. pdf转图片
image_paths = pdf_to_images(pdf_path, images_dir)
# 2. 使用qwen2.5vl分析每张图片
logger.info(f"=== 步骤2: {pdf_name} ai图像识别分析 ===")
results = {}
formatted_outputs = []
for i, image_path in enumerate(image_paths, 1):
logger.info(f"正在分析 {pdf_name} 第 {i} 页图片...")
analysis_result = analyze_image_with_qwen(image_path, analysis_prompt)
logger.info(f"分析结果: {analysis_result}")
# 使用qwen3:32b提取
extra_prompt = """
注意:如果金额必须最大的数字为金额
输出格式:最大数字的金额_类别_商户名称_纳税人识别号_发票号码_年_月_日
示例输出格式:82.00_餐饮_寿司餐饮服务管理有限公司_111100259570_22970898_2025_03_30
""".strip()
# 使用qwen3:32b进行二次处理和格式化
formatted_result = analyze_with_qwen3_32b(analysis_result, extra_prompt)
logger.info(f"qwen3:32b原始输出: {formatted_result}")
formatted_result= formatted_result.split("</think>")[-1].strip()
logger.info(f"格式化结果: {formatted_result}")
formatted_outputs.append(formatted_result)
results[f"page_{i}"] = {
"image_path": image_path,
"analysis": analysis_result,
"formatted_output": formatted_result
}
logger.info(f"最终格式化输出: {formatted_result}")
break
# 3. 复制pdf文件并重命名
copied_pdf_paths = []
for i, analysis_result in enumerate(formatted_outputs, 1):
if analysis_result.strip(): # 确保分析结果不为空
# 创建重命名的pdf目录
renamed_pdf_dir = os.path.join(output_dir, "renamed_pdfs")
# 复制并重命名pdf文件
new_pdf_path = copy_and_rename_pdf(pdf_path, renamed_pdf_dir, analysis_result)
if new_pdf_path:
copied_pdf_paths.append(new_pdf_path)
return {
"pdf_name": pdf_name,
"pdf_path": pdf_path,
"results": results,
"formatted_outputs": formatted_outputs,
"copied_pdf_paths": copied_pdf_paths # 添加复制的pdf路径信息
}
def process_pdf_directory(source_dir, output_dir, analysis_prompt="请详细分析这张发票,提取以下信息:最大金额、商户名称、纳税人识别号、发票号码、开票日期、商品类别等关键信息"):
"""
批量处理pdf目录
args:
source_dir (str): 源pdf目录
output_dir (str): 输出目录
analysis_prompt (str): 分析提示词
returns:
dict: 所有处理结果
"""
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 获取所有pdf文件
pdf_files = get_pdf_files(source_dir)
if not pdf_files:
logger.info(f"在目录 {source_dir} 中未找到pdf文件")
return {}
logger.info(f"找到 {len(pdf_files)} 个pdf文件")
all_results = {}
all_formatted_outputs = []
# 处理每个pdf文件
for i, pdf_path in enumerate(pdf_files, 1):
logger.info(f"处理进度: {i}/{len(pdf_files)}")
try:
result = process_single_pdf(pdf_path, output_dir, analysis_prompt)
all_results[result["pdf_name"]] = result
all_formatted_outputs.extend(result["formatted_outputs"])
except exception as e:
logger.info(f"处理 {pdf_path} 时出错: {str(e)}")
continue
return all_results, all_formatted_outputs
def save_results(results, output_dir, filename="analysis_results.json"):
"""
保存分析结果到json文件
args:
results (dict): 分析结果
output_dir (str): 输出目录
filename (str): 文件名
"""
output_file = os.path.join(output_dir, filename)
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=false, indent=2)
logger.info(f"\n分析结果已保存到: {output_file}")
def save_formatted_outputs(formatted_outputs, output_dir, filename="formatted_outputs.txt"):
"""
保存格式化输出到文本文件
args:
formatted_outputs (list): 格式化输出列表
output_dir (str): 输出目录
filename (str): 文件名
"""
output_file = os.path.join(output_dir, filename)
with open(output_file, 'w', encoding='utf-8') as f:
for output in formatted_outputs:
f.write(output + '\n')
logger.info(f"格式化输出已保存到: {output_file}")
def main():
"""
主函数
"""
logger.info("pdf批量分析工具")
logger.info("=" * 30)
# 获取源pdf目录
# source_dir = input("请输入源pdf目录路径: ").strip()
source_dir = r"d:\2025年7月期间发票"
if not os.path.exists(source_dir):
logger.info("源目录不存在,请检查路径")
return
if not os.path.isdir(source_dir):
logger.info("输入的路径不是目录")
return
# 获取输出目录
# output_dir = input("请输入输出目录路径: ").strip()
output_dir = r"d:\2025年7月期间发票2"
# 自定义分析提示词
# custom_prompt = input("请输入分析提示词(直接回车使用默认): ").strip()
custom_prompt = "分析发票图片,提取发票最大的小写金额,产品所属类别,销售方名称,纳税人识别号,发票号码,开票日期,一段话"
# if not custom_prompt:
# custom_prompt = """请分析这张发票图片,并严格按照以下格式输出一行结果:
# 金额_类别_商户名称_纳税人识别号_发票号码_年_月_日
# 要求:
# 1. 金额:提取"价税合计"字段对应的金额,通常格式为(小写)¥82.00,只提取数字部分如82.00
# 2. 类别:根据商品判断(餐饮、住宿、交通、办公、其他)
# 3. 商户名称:发票上的企业名称
# 4. 纳税人识别号:统一社会信用代码或纳税人识别号
# 5. 发票号码:发票号码
# 6. 日期:开票日期,格式为年_月_日,如2025_03_30
# 注意:
# - 重点识别"价税合计"字段,不要识别成"合计"
# - 金额前可能有(小写)¥符号,只提取数字部分
# - 确保提取的是价税合计的最终金额
# 示例输出格式:82.00_餐饮_寿司餐饮服务管理有限公司_111100259570_22970898_2025_03_30
# 请只输出这一行格式化结果,不要包含其他说明文字。"""
try:
# 批量处理pdf目录
logger.info(f"\n开始批量处理pdf目录: {source_dir}")
all_results, all_formatted_outputs = process_pdf_directory(source_dir, output_dir, custom_prompt)
if not all_results:
logger.info("没有成功处理任何pdf文件")
return
# 保存结果
save_results(all_results, output_dir)
save_formatted_outputs(all_formatted_outputs, output_dir)
logger.info("批量处理完成")
logger.info("\n=== 所有格式化输出结果 ===")
for i, output in enumerate(all_formatted_outputs, 1):
logger.info(f"{i:3d}: {output}")
except exception as e:
logger.info(f"处理过程中出现错误: {str(e)}")
if __name__ == "__main__":
main()
到此这篇关于python基于openai api轻松实现pdf发票信息提取的文章就介绍到这了,更多相关python提取pdf发票信息内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论