一、前言
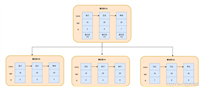
当单库数据量达到千万级、单表达到百万级时,性能会急剧下降,分库分表是解决数据存储瓶颈的核心方案。本文基于 shardingsphere-jdbc,详解垂直分库、水平分库、水平分表的实现方式。
二、分库分表基础:cap 定理与解决方案
- cap 定理:分布式系统无法同时满足一致性(c)、可用性(a)、分区容忍性(p),mysql 分库分表通常选择:
- ap:保证可用性,牺牲强一致性(最终一致);
- cp:保证强一致性,牺牲可用性(适合金融场景);
- 主流解决方案:
- shardingsphere-jdbc:轻量级,嵌入应用内,无中间件依赖;
- shardingsphere-proxy:独立中间件,支持多语言;
- mycat:老牌数据库中间件。
三、shardingsphere-jdbc 核心概念
- 分片键:用于分库 / 分表的字段(如 user_id、id);
- 分片算法:inline(行内表达式)、mod(取模)、hash(哈希)等;
- 绑定表:关联表(如 t_order 和 t_order_item),避免笛卡尔乘积,提升查询效率;
- 广播表:字典表(如 t_dict),同步到所有分片节点,保证数据一致。
四、分库分表实战(yaml 配置)
1. 垂直分库(按业务拆分)
将不同业务表拆分到不同数据库(如用户表→user_ds,订单表→order_ds):
rules:
- !sharding
tables:
t_user:
actualdatanodes: user_ds.t_user # 用户表在user_ds库
t_order:
actualdatanodes: order_ds.t_order # 订单表在order_ds库2. 水平分库(按分片键拆分到多个库)
将订单表按 user_id 取模拆分到 order_ds_0 和 order_ds_1 两个库:
rules:
- !sharding
tables:
t_user:
actualdatanodes: user_ds.t_user
t_order:
actualdatanodes: order_ds_${0..1}.t_order0 # 订单表在2个库的t_order0表
databasestrategy:
standard:
shardingcolumn: user_id # 分片键:user_id
shardingalgorithmname: userid_inline # 分片算法
shardingalgorithms:
userid_inline:
type: inline
props:
algorithm-expression: order_ds_${user_id % 2} # 取模拆分3. 水平分表(按分片键拆分到多个表)
将订单表按 id 取模拆分到每个库的 t_order0 和 t_order1 表:
rules:
- !sharding
tables:
t_user:
actualdatanodes: user_ds.t_user
t_order:
actualdatanodes: order_ds_${0..1}.t_order${0..1} # 2库×2表=4个物理表
databasestrategy:
standard:
shardingcolumn: user_id
shardingalgorithmname: userid_inline
tablestrategy:
standard:
shardingcolumn: id # 分表键:id
shardingalgorithmname: orderid_inline
shardingalgorithms:
userid_inline:
type: inline
props:
algorithm-expression: order_ds_${user_id % 2}
orderid_inline:
type: inline
props:
algorithm-expression: t_order${id % 2} # 取模分表4. 关联表(绑定表)+ 广播表
rules:
- !sharding
tables:
t_user:
actualdatanodes: user_ds.t_user
t_order:
actualdatanodes: order_ds_${0..1}.t_order${0..1}
databasestrategy:
standard:
shardingcolumn: user_id
shardingalgorithmname: userid_inline
tablestrategy:
standard:
shardingcolumn: id
shardingalgorithmname: orderid_inline
t_order_item: # 订单项表(关联表)
actualdatanodes: order_ds_${0..1}.t_order_item${0..1}
databasestrategy:
standard:
shardingcolumn: user_id
shardingalgorithmname: userid_inline
tablestrategy:
standard:
shardingcolumn: order_id
shardingalgorithmname: orderid_item_inline
bindingtables: # 绑定表:t_order和t_order_item
- t_order,t_order_item
shardingalgorithms:
userid_inline:
type: inline
props:
algorithm-expression: order_ds_${user_id % 2}
orderid_inline:
type: inline
props:
algorithm-expression: t_order${id % 2}
orderid_item_inline:
type: inline
props:
algorithm-expression: t_order_item${order_id % 2}
- !broadcast # 广播表:t_dict(字典表)
tables:
- t_dict五、分库分表注意事项
- 分片键选择:优先选查询高频字段(如 user_id),避免跨分片查询;
- 避免跨库事务:尽量将同一事务的操作落在同一分片;
- 主键生成:使用雪花算法生成分布式 id(64 位,19 位整数),避免主键冲突;
- 查询优化:
- 避免 select *,使用覆盖索引;
- 关联查询使用绑定表,减少笛卡尔乘积。
总结
- 垂直分库按业务拆分,水平分库 / 分表按分片键拆分,解决单库 / 单表数据量过大问题;
- shardingsphere-jdbc 通过 yaml 配置实现分片,inline 算法简单高效,适合大部分场景;
- 绑定表减少关联查询开销,广播表保证字典数据一致,分片键选择是分库分表的核心。
以上就是mysql使用shardingsphere-jdbc实现数据分片的详细内容,更多关于mysql shardingsphere-jdbc数据分片的资料请关注代码网其它相关文章!



发表评论