引言:python参数传递的本质
在python编程中,参数传递是一个看似简单却暗藏玄机的概念。许多开发者,尤其是从其他语言转来的程序员,常常会被python的参数传递机制所迷惑。python采用的是"对象引用传递"机制,这意味着函数接收的是对原始对象的引用,而非对象本身的副本。这种机制对于不可变对象(如整数、字符串、元组)和可变对象(如列表、字典)会产生截然不同的效果。
def greet(name):
print(f"hello, {name}!")
表面上看,这段代码简单明了,但当name参数传递的是复杂对象时,情况就会变得微妙起来。本文将深入探讨python参数传递的各种陷阱,帮助开发者写出更健壮、更可靠的代码。
基础类型参数传递问题
整数与列表的参数传递对比
让我们从一个简单的加法函数开始探索:
def add(a, b):
a += b
return a
if __name__ == "__main__":
# 整数测试
x, y = 10, 20
print(add(x, y)) # 输出: 30
print(x, y) # 输出: 10 20 (原值不变)
# 列表测试
list1, list2 = [1, 2], [3, 4]
print(add(list1, list2)) # 输出: [1, 2, 3, 4]
print(list1, list2) # 输出: [1, 2, 3, 4] [3, 4] (list1被修改)
# 元组测试
tuple1, tuple2 = (1, 2), (3, 4)
print(add(tuple1, tuple2)) # 输出: (1, 2, 3, 4)
print(tuple1, tuple2) # 输出: (1, 2) (3, 4) (原值不变)不同数据类型的参数传递行为
为了更清晰地展示不同数据类型的参数传递行为,我们整理如下表格:
| 数据类型 | 可变性 | 函数内修改后 | 原变量是否改变 | +=操作结果 |
|---|---|---|---|---|
| 整数 | 不可变 | 创建新对象 | 否 | 新对象 |
| 列表 | 可变 | 原地修改 | 是 | 原地修改 |
| 元组 | 不可变 | 创建新对象 | 否 | 新对象 |
| 字符串 | 不可变 | 创建新对象 | 否 | 新对象 |
| 字典 | 可变 | 原地修改 | 是 | 原地修改 |
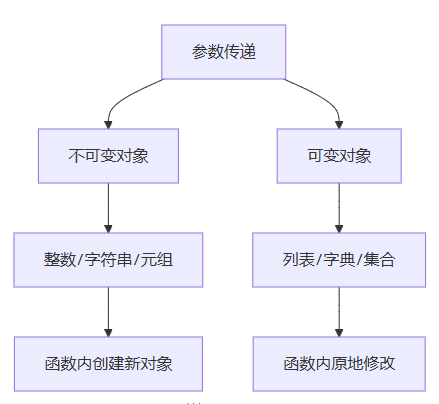
图表说明:python参数传递根据对象可变性表现出不同的行为。不可变对象在函数内操作会创建新对象,而可变对象则会原地修改。
类定义中的参数传递陷阱
默认参数的危险
当我们在类定义中使用可变对象作为默认参数时,会遇到一个特别隐蔽的问题。让我们通过一个company类的例子来说明:
class company:
def __init__(self, name, staffs=[]): # 危险!默认参数是可变对象
self.name = name
self.staffs = staffs
def add(self, staff):
self.staffs.append(staff)
def remove(self, staff):
if staff in self.staffs:
self.staffs.remove(staff)
# 测试情况
if __name__ == "__main__":
# 情况1:传递自定义列表
staff_list = ["alice", "bob"]
company1 = company("techcorp", staff_list)
company1.add("charlie")
print(company1.staffs) # 输出: ['alice', 'bob', 'charlie']
print(staff_list) # 输出: ['alice', 'bob', 'charlie'] (原列表被修改)
# 情况2:使用默认列表
company2 = company("startup1")
company3 = company("startup2")
company2.add("david")
print(company2.staffs) # 输出: ['david']
print(company3.staffs) # 输出: ['david'] (company3也被影响了!)问题分析与解决方案
这个问题的根源在于:默认参数在函数定义时就被求值并创建,而不是在每次调用时。因此,所有使用默认参数的company实例实际上共享同一个列表对象。
正确的做法是:
class company:
def __init__(self, name, staffs=none): # 使用none作为默认值
self.name = name
self.staffs = staffs if staffs is not none else [] # 每次创建新列表
# 其他方法保持不变实际应用案例
案例1:配置管理系统中的参数传递
假设我们正在开发一个配置管理系统,需要处理各种配置项的更新:
def update_config(config, new_settings):
"""更新配置参数"""
config.update(new_settings)
return config
# 使用示例
global_config = {"timeout": 30, "retries": 3}
new_settings = {"timeout": 60, "cache_size": "1gb"}
updated = update_config(global_config, new_settings)
print(updated) # 输出: {'timeout': 60, 'retries': 3, 'cache_size': '1gb'}
print(global_config) # 输出: 同上!原配置被修改了解决方案:如果不想修改原配置,应该先创建副本:
def update_config(config, new_settings):
"""安全更新配置参数"""
new_config = config.copy()
new_config.update(new_settings)
return new_config
案例2:数据分析流水线
在数据分析中,我们经常需要传递大型数据结构:
def process_data(data):
"""处理数据并添加统计信息"""
data["stats"] = {
"mean": sum(data["values"]) / len(data["values"]),
"max": max(data["values"])
}
return data
raw_data = {"values": [10, 20, 30, 40]}
processed = process_data(raw_data)
# raw_data现在也包含stats了,这可能不是我们想要的解决方案:明确区分输入和输出数据:
def process_data(input_data):
"""安全处理数据"""
output_data = {
"original_values": input_data["values"].copy(),
"stats": {
"mean": sum(input_data["values"]) / len(input_data["values"]),
"max": max(input_data["values"])
}
}
return output_data深入理解:python的变量模型
要彻底理解python的参数传递机制,我们需要了解python的变量模型:
- 变量是对象的引用:python中的变量实际上是对内存中对象的引用
- 不可变对象:创建后不能修改(如int, float, str, tuple)
- 可变对象:创建后可以修改(如list, dict, set)
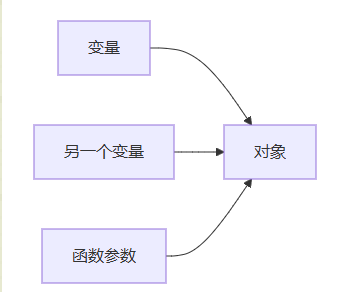
图表说明:多个变量、函数参数可以引用同一个对象,特别是当对象是可变时,这种共享会导致意外的修改。
最佳实践与总结
python参数传递的黄金法则
- 避免可变默认参数:使用none作为默认值,然后在函数内部创建新对象
- 明确意图:如果函数需要修改输入参数,应在文档中明确说明
- 防御性拷贝:当不确定调用者是否希望保留原对象时,创建参数的副本
- 使用不可变对象:在可能的情况下,优先选择元组而不是列表
性能考虑
虽然创建副本更安全,但对于大型数据结构可能会影响性能。在这种情况下:
- 明确文档说明函数是否会修改输入
- 考虑使用生成器或视图(view)来避免复制大数据
- 对于性能关键代码,可以在安全性和性能之间做出明确权衡
总结表格:参数传递的正确姿势
| 场景 | 问题 | 解决方案 |
|---|---|---|
| 默认参数 | 可变默认参数在函数定义时创建并共享 | 使用none作为默认值,函数内创建新对象 |
| 函数修改参数 | 意外修改了调用者的数据 | 创建参数的深拷贝或明确文档说明 |
| 大型数据结构 | 复制成本高 | 考虑使用不可变视图或明确文档说明修改行为 |
| 类属性初始化 | 多个实例共享同一默认可变属性 | 在__init__中初始化可变属性 |
python的参数传递机制既强大又微妙。理解这些细节是成为python高手的关键一步。记住:显式优于隐式,清晰的代码和文档可以避免大多数参数传递相关的问题。
希望本文能帮助你在python编程中避开参数传递的陷阱,写出更加健壮可靠的代码!
到此这篇关于python参数传递的陷阱之从基础类型到类的深入探讨的文章就介绍到这了,更多相关python参数传递内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论