引言
在处理大量word文档时,你是否曾为查找并高亮特定内容而烦恼?无论是合同关键词的审查、报告中异常数据的标注,还是教学资料的重点突出,手动操作无疑是耗时且易出错的。自动化办公是趋势,但在c#中操作word文档,尤其是精准查找并高亮文本,往往充满挑战。
本文将深入探讨c#中实现word文本查找与高亮的多种方法,并着重介绍一种高效且易用的解决方案,助你轻松驾驭文档处理。
1. 为什么我们需要在word中查找并高亮文本?典型应用场景解析
在c#中对word文档进行文本查找与高亮处理,其价值远不止于简单的界面操作替代。它在多个实际应用场景中发挥着关键作用:
- 文档内容审核与合规性检查:自动查找并高亮敏感词汇、特定条款或不符合规范的内容,确保文档符合法规要求。
- 关键词提取与数据清洗:从大量非结构化文档中快速定位并提取关键信息,为后续数据分析奠定基础。
- 自动化报告生成:根据预设规则,在生成的报告中自动高亮重要的结论、异常数据或需要关注的指标。
- 教学与培训资料制作:自动突出显示知识点、重点概念,提升学习效率。
- 文档版本比对与差异标记:在文档修订过程中,自动高亮新增加或修改的内容,方便审阅。
这些场景无一不强调了自动化处理在提高效率、降低人工错误方面的巨大价值。
2. c#实现word文本查找与高亮的传统方案与挑战
在c#中操作word文档,我们通常会想到两种传统方案:
- com interop(microsoft office interop)
- 优势:直接调用office应用程序的api,功能最全面,可以实现word应用的所有功能。
- 劣势:
- 环境依赖:需要目标机器安装对应版本的microsoft office。
- 部署复杂性:服务器端部署时,可能遇到权限、稳定性等问题。
- 性能问题:每次操作都需要启动word进程,效率低下,不适合批量处理。
- 跨平台限制:本质上是windows平台的com技术,无法跨平台使用。
- open xml sdk
- 优势:无需安装office,直接操作word文档的底层xml结构,部署相对简单。
- 劣势:
- api复杂:对word文档的open xml结构有较高的理解门槛,api较为底层和繁琐。
- 学习曲线陡峭:需要花费大量时间学习文档的内部结构和各个元素的xml表示。
- 开发效率低:实现复杂功能需要编写大量代码,开发周期长。
这两种方案在实际开发中都存在各自的痛点和局限性,尤其是在追求高效率、低学习成本和跨平台兼容性的今天,它们往往难以满足现代开发的需求。
3. 拥抱高效利器:使用spire.doc for .net实现精准查找与高亮
面对传统方案的挑战,第三方库如spire.doc for .net提供了一个优雅且强大的解决方案。它是一个独立的word组件,无需安装microsoft office即可在c#应用程序中创建、读取、写入和转换word文档。
方案对比
| 特性 | com interop | open xml sdk | spire.doc for .net |
|---|---|---|---|
| 易用性 | 中(需熟悉word对象模型) | 低(api复杂,需懂xml) | 高(api简洁直观) |
| 环境依赖 | 需安装office | 无需安装office | 无需安装office |
| 功能丰富度 | 极高(office全功能) | 较高(需自行实现) | 极高(封装好常用功能) |
| 学习成本 | 中 | 高 | 低 |
| 性能 | 慢(启动word进程) | 中等 | 快 |
| 部署复杂性 | 高 | 中等 | 低 |
spire.doc for .net优势
spire.doc for .net凭借其简洁的api、强大的功能、无需安装office的特性,以及对多种查找模式(全词匹配、大小写敏感、正则表达式)和自定义高亮样式的支持,成为c# word文档处理的理想选择。
代码示例:查找并高亮文本
下面是一个使用spire.doc for .net加载word文档,查找所有“c#”并高亮为黄色的简单示例:
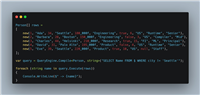
using spire.doc;
using spire.doc.documents;
using spire.doc.fields;
using system.drawing; // 用于color
public class wordhighlighter
{
public static void highlighttextinword(string inputfilepath, string outputfilepath, string searchtext)
{
// 1. 加载文档
document doc = new document();
doc.loadfromfile(inputfilepath);
// 2. 设置查找选项
// findallstring方法支持多种重载,这里我们使用区分大小写且全词匹配的查找
// 第一个参数是查找的文本
// 第二个参数是是否区分大小写 (true为区分,false为不区分)
// 第三个参数是是否全词匹配 (true为全词匹配,false为包含即可)
textselection[] selections = doc.findallstring(searchtext, true, true);
// 3. 遍历所有找到的文本并高亮
foreach (textselection selection in selections)
{
// 获取选中的文本范围,并设置其高亮颜色
selection.getasonerange().characterformat.highlightcolor = color.yellow;
// 如果需要其他颜色,可以使用color.red, color.lightblue等
}
// 4. 保存修改后的文档
doc.savetofile(outputfilepath, fileformat.docx);
system.console.writeline($"文档已处理并保存到: {outputfilepath}");
}
public static void main(string[] args)
{
// 假设有一个名为 "input.docx" 的word文档在你的项目根目录或指定路径
// 请替换为你的实际文件路径
string inputdoc = "input.docx";
string outputdoc = "output_highlighted.docx";
string texttofind = "c#";
highlighttextinword(inputdoc, outputdoc, texttofind);
}
}
进阶用法提示:
- 正则表达式查找:
doc.findallstring(new regex("your_regex_pattern"))可以实现更复杂的模式匹配。 - 多个关键词高亮:可以循环调用
findallstring方法,或使用正则表达式匹配多个关键词。 - 自定义高亮颜色和样式:
characterformat对象提供了丰富的属性,可以设置字体、字号、颜色、背景色等。
总结
在c#中进行word文档的文本查找与高亮,无论是为了内容审核、数据提取还是自动化报告,都是一项常见的需求。传统方案如com interop和open xml sdk各有优劣,但在易用性、部署和开发效率上存在挑战。
spire.doc for .net作为一款专业的第三方库,以其简洁的api、强大的功能和无需office环境的特性,极大地简化了word文档的处理过程。它不仅能帮助开发者轻松实现文本的精准查找与高亮,还能有效提升开发效率和应用性能。它将是你提升生产力的强大盟友。
以上就是c#中实现word文本查找与高亮的多种方法的详细内容,更多关于c# word文本查找与高亮的资料请关注代码网其它相关文章!




发表评论