在数据处理、数据分析和自动化办公场景中,csv(逗号分隔值)文件是最常用的数据交换格式之一。python 作为数据处理的主流语言,原生提供了csv模块处理csv文件,但面对复杂场景(如大文件、csv 与 excel 格式互转、特殊字符处理)时,原生模块往往需要大量额外封装。
本文将介绍如何使用 free spire.xls for python 库实现 csv 文件的读取、写入操作。开始前先通过 pip 安装该免费库:
pip install spire.xls.free
相比标准库 csv,它的核心优势在于:
- 更简洁的 api - 减少代码复杂度
- 更强兼容性 – 自动处理编码,原生支持中文、特殊字符
- 多格式支持 - csv、excel、pdf 等格式的互转
1. 通过 python 读取csv文件
1.1 基础读取:读取整份csv文件
以下示例展示如何读取csv文件的所有数据,包括表头和内容,并打印输出:
from spire.xls import *
def read_csv_file(file_path):
# 创建workbook对象
workbook = workbook()
# 加载csv文件
workbook.loadfromfile(file_path, ",", 1, 1)
# 获取第一个工作表(csv文件加载后默认生成一个工作表)
worksheet = workbook.worksheets[0]
# 获取工作表的行数和列数
row_count = worksheet.lastrow
col_count = worksheet.lastcolumn
# 遍历所有单元格并打印数据
print("csv文件内容:")
for row in range(1, row_count + 1):
row_data = []
for col in range(1, col_count + 1):
cell_value = worksheet.range[row, col].text
row_data.append(cell_value)
print("\t".join(row_data))
# 释放资源
workbook.dispose()
# 调用函数读取csv文件
if __name__ == "__main__":
csv_file_path = "sales_data.csv" # 替换为你的csv文件路径
read_csv_file(csv_file_path)
读取结果:
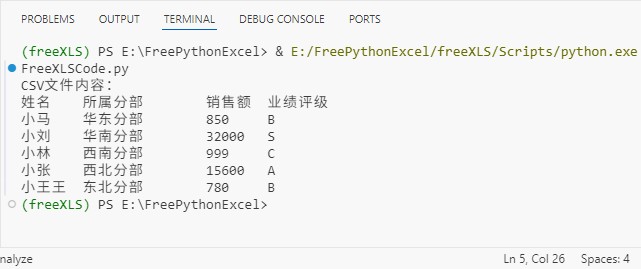
1.2 进阶读取:按条件筛选数据
实际场景中常需筛选特定行/列数据,例如读取“销售额>1000”的行:
from spire.xls import *
def read_csv_with_filter(file_path):
workbook = workbook()
workbook.loadfromfile(file_path, ",", 1, 1)
worksheet = workbook.worksheets[0]
row_count = worksheet.lastrow
col_count = worksheet.lastcolumn
# 假设第3列是销售额(数值型),筛选销售额>1000的行
print("销售额>1000的记录:")
# 跳过表头(第一行)
for row in range(2, row_count + 1):
# 获取销售额单元格的值并转换为浮点数
sales_value = float(worksheet.range[row, 3].text)
if sales_value > 1000:
row_data = []
for col in range(1, col_count + 1):
row_data.append(worksheet.range[row, col].text)
print("\t".join(row_data))
workbook.dispose()
if __name__ == "__main__":
read_csv_with_filter("sales_data.csv")
按条件读取结果:
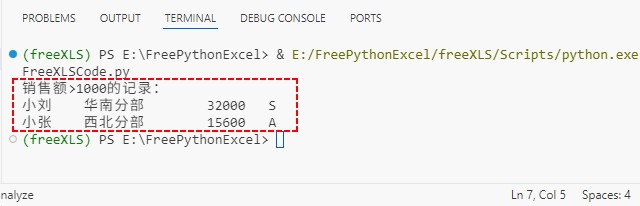
2. 通过 python 写入 csv 文件
2.1 基础写入:创建并写入 csv 文件
以下示例展示如何创建新的 csv 文件,并写入表头和多行数据:
from spire.xls import *
def write_csv_file(file_path):
# 创建workbook对象
workbook = workbook()
# 移除默认的工作表,创建新工作表
workbook.worksheets.clear()
worksheet = workbook.worksheets.add("csv_data")
# 定义表头和数据
header = ["姓名", "部门", "薪资", "入职时间"]
data = [
["张三", "销售部", "15000", "2023-01-10"],
["李四", "技术部", "12000", "2023-03-15"],
["王五", "市场部", "8000", "2022-11-20"]
]
# 写入表头
for col in range(len(header)):
worksheet.range[1, col + 1].text = header[col]
# 写入数据
for row in range(len(data)):
for col in range(len(data[row])):
worksheet.range[row + 2, col + 1].text = data[row][col]
# 保存为csv文件(指定编码为utf-8,避免中文乱码)
worksheet.savetofile(file_path, ",", encoding.get_utf8())
# 释放资源
workbook.dispose()
print(f"csv文件已成功写入:{file_path}")
if __name__ == "__main__":
write_csv_file("employee_data.csv")
生成的 csv 文件:
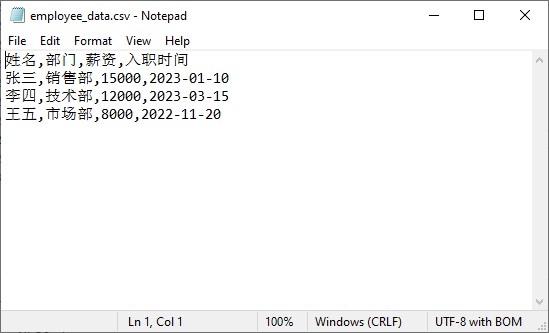
2.2 进阶写入:追加数据到已有 csv 文件
若需在已有 csv 文件末尾追加数据,可先读取原有数据,再写入新数据:
from spire.xls import *
def append_to_csv(file_path, new_data):
# 加载已有csv文件
workbook = workbook()
workbook.loadfromfile(file_path, ",", 1, 1)
worksheet = workbook.worksheets[0]
# 获取已有数据的最后一行
last_row = worksheet.lastrow
# 追加新数据
for row in range(len(new_data)):
for col in range(len(new_data[row])):
worksheet.range[last_row + row + 1, col + 1].text = new_data[row][col]
# 保存到新csv文件
worksheet.savetofile("new_employee_data.csv", ",", encoding.get_utf8())
workbook.dispose()
if __name__ == "__main__":
# 要追加的新数据
new_data = [
["赵六", "财务部", "9000", "2023-05-01"],
["孙七", "行政部", "7500", "2023-02-28"]
]
append_to_csv("employee_data.csv", new_data)
数据追加结果:
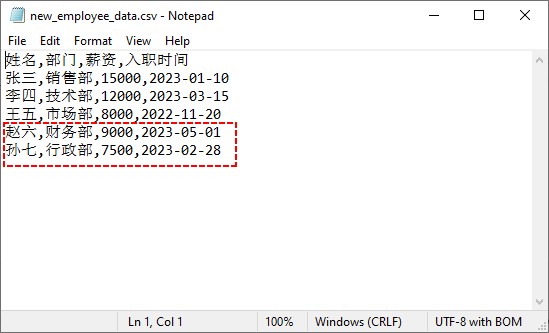
3. 常见问题与解决方案
- 中文乱码问题:保存时指定
encoding.get_utf8(),避免默认编码导致的乱码; - 大文件读写卡顿:可使用
worksheet.exportdatatable()将数据转为datatable,分片处理; - csv分隔符非逗号:加载/保存时指定分隔符(如制表符
\t、分号;),示例:workbook.loadfromfile(file_path, ";", 1, 1)。
4. 总结
free spire.xls for python 是处理 csv 文件的高效工具:
- 读取 csv 的核心步骤是:创建
workbook→ 加载文件 → 遍历工作表单元格; - 写入/追加 csv 的核心步骤是:创建/加载工作表 → 写入数据 → 指定编码保存为 csv 格式。
通过本文的示例,你可以快速掌握基于 python 的 csv 文件读取与写入技巧,满足日常数据处理、自动化办公等场景的需求。相比原生模块,该库的面向对象api更易维护,且能无缝对接 excel 格式,是 python 数据处理的优质选择。
以上就是通过python读写csv文件的入门教程的详细内容,更多关于python读写csv文件的资料请关注代码网其它相关文章!





发表评论