一、案例背景与价值
身份证号码识别是计算机视觉在证件信息提取中的典型应用,广泛应用于身份验证、自动化录入、政务系统等场景。本案例基于python的opencv库,实现身份证号码的定位→分割→识别全流程,兼顾实用性与可复现性。
二、技术栈说明
编程语言:python 3.x
核心库:
opencv(cv2):图像预处理、轮廓检测、形态学操作
numpy:数值计算与数组处理
(可选)tesseract ocr:替代模板匹配的字符识别方案
三、整体实现流程
身份证号码识别遵循四大核心步骤:
图像预处理:降噪、二值化、增强字符边缘
号码区域定位:通过轮廓检测与位置筛选锁定18位数字区域
字符分割:垂直投影或轮廓排序分割单个字符
字符识别:模板匹配/机器学习模型识别数字(含字母x)
四、数据准备
需提前准备两张图片:
sfzh.png:包含0-9数字的模板图像(用于训练字符模板)

sfz.jpg:待识别的身份证原件图像
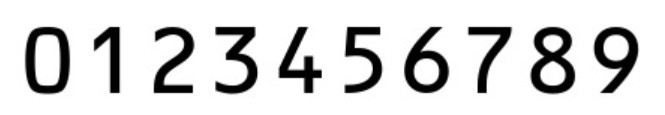
五、代码详解与实战
1. 基础函数定义与导入
首先导入依赖库,并定义两个辅助函数:
cv_show:快速显示图像(避免重复写imshow和waitkey)sort_contours:按指定方向排序轮廓(确保字符顺序正确)
import cv2
import numpy as np
# 绘图展示函数:简化图像显示流程
def cv_show(name, image):
cv2.imshow(name, image)
cv2.waitkey(0)
cv2.destroyallwindows()
# 轮廓排序函数:支持左→右、右→左、上→下、下→上
def sort_contours(cnts, method='left-to-right'):
reverse = false
i = 0
if method in ['right-to-left', 'bottom-to-top']:
reverse = true
if method in ['top-to-bottom', 'bottom-to-top']:
i = 1
boundingboxes = [cv2.boundingrect(c) for c in cnts]
(cnts, boundingboxes) = zip(*sorted(zip(cnts, boundingboxes),
key=lambda b: b[1][i], reverse=reverse))
return cnts, boundingboxes2. 模板图像预处理:生成字符匹配模板
首先处理sfzh.png(包含0-9的数字模板),提取每个数字的标准轮廓,作为后续匹配的基准。
步骤1:读取模板并转灰度/二值图
# 读取模板图像
img_template = cv2.imread("sfzh.png")
cv_show('template image', img_template)
# 转灰度图(减少颜色通道干扰)
gray_template = cv2.imread("sfzh.png", 0)
# 二值化:反阈值化(数字变白,背景变黑)
ret, ref_bin = cv2.threshold(gray_template, 150, 255, cv2.thresh_binary_inv)
cv_show('binary template', ref_bin)步骤2:轮廓检测与数字排序
# 查找外轮廓(仅保留数字的外边界)
_, contours, _ = cv2.findcontours(ref_bin, cv2.retr_external, cv2.chain_approx_simple)
# 按左→右排序轮廓(确保数字顺序是0→9)
sorted_contours, _ = sort_contours(contours, method='left-to-right')
# 可视化轮廓(确认数字是否正确检测)
cv2.drawcontours(img_template, sorted_contours, -1, (0, 255, 0), 2)
cv_show('template with contours', img_template)步骤3:生成数字模板字典
对每个数字轮廓提取roi(感兴趣区域),统一尺寸并存储,供后续匹配使用:
digits = {} # 存储数字模板:key=数字索引,value=标准化后的数字图像
for idx, contour in enumerate(sorted_contours):
# 获取数字的边界框
x, y, w, h = cv2.boundingrect(contour)
# 提取roi并扩展边界(避免裁剪数字)
roi = ref_bin[y-2:y+h+2, x-2:x+w+2]
# 统一尺寸为57×88(模板匹配的最佳尺寸)
roi = cv2.resize(roi, (57, 88))
# 按位取反(统一为数字黑、背景白)
roi = cv2.bitwise_not(roi)
# 存储模板
digits[idx] = roi
# 关闭所有窗口
cv2.destroyallwindows()3. 身份证号码识别:定位→分割→匹配
接下来处理待识别的身份证图像sfz.jpg,完成号码区域的定位与字符识别。
步骤1:身份证图像预处理
# 读取身份证原图
img_id = cv2.imread('sfz.jpg')
img_copy = img_id.copy() # 用于后续绘制结果
cv_show('original id card', img_id)
# 转灰度图
gray_id = cv2.imread('sfz.jpg', 0)
cv_show('gray id card', gray_id)
# 二值化(阈值根据原图亮度调整)
ret, id_bin = cv2.threshold(gray_id, 120, 255, cv2.thresh_binary_inv)
cv_show('binary id card', id_bin)步骤2:定位身份证号码区域
通过轮廓的位置筛选,锁定身份证底部的18位数字区域(注意:坐标范围需根据实际图像调整):
# 查找身份证图像的所有外轮廓
_, contours_id, _ = cv2.findcontours(id_bin.copy(), cv2.retr_external, cv2.chain_approx_simple)
# 筛选号码区域:根据y坐标(330~360)和x坐标(x>220)定位底部数字
locs = []
for (i, contour) in enumerate(contours_id):
x, y, w, h = cv2.boundingrect(contour)
if 330 < y < 360 and x > 220:
locs.append((x, y, w, h))
# 按x坐标排序(确保数字从左到右排列)
locs = sorted(locs, key=lambda x: x[0])
步骤3:单字符预处理与模板匹配
对每个筛选出的数字区域,进行预处理后与模板匹配,识别具体数字:
output = [] # 存储最终识别结果
for (gx, gy, gw, gh) in locs:
# 1. 提取数字区域并扩展边界
group = gray_id[gy-2:gy+gh+2, gx-2:gx+gw+2]
# 2. 自适应阈值(自动优化黑白对比)
group = cv2.threshold(group, 0, 255, cv2.thresh_binary | cv2.thresh_otsu)[1]
# 3. 统一尺寸为模板大小(57×88)
roi = cv2.resize(group, (57, 88))
# 4. 按位取反(与模板格式一致)
roi = cv2.bitwise_not(roi)
# 5. 模板匹配:计算当前roi与所有模板的相似度
scores = []
for digit, template in digits.items():
# 使用tm_ccoeff方法(值越大越匹配)
result = cv2.matchtemplate(roi, template, cv2.tm_ccoeff)
(_, score, _, _) = cv2.minmaxloc(result)
scores.append(score)
# 6. 取得分最高的模板对应的数字
jieguo = str(np.argmax(scores))
output.append(jieguo)
# (可选)可视化识别结果:绘制矩形框与数字文本
cv2.rectangle(img_copy, (gx-5, gy-5), (gx+gw+5, gy+gh+5), (0, 0, 255), 1)
cv2.puttext(img_copy, jieguo, (gx, gy-15),
cv2.font_hershey_simplex, 0.65, (0, 0, 255), 2)步骤4:输出结果与可视化
# 打印识别结果(拼接成18位身份证号)
print("识别结果:{}".format("".join(output)))
# 显示带识别标记的身份证图像
cv2.imshow('id card with recognition', img_copy)
cv2.waitkey(0)
cv2.destroyallwindows()六、关键说明与优化方向
位置筛选的适配性:案例中的
330<y<360和x>220是基于特定身份证图像的坐标,实际应用需根据输入图像调整(可通过调试轮廓的(x,y,w,h)可视化确认)。模板匹配的局限性:若身份证图像存在旋转、缩放或光照不均,需增加角度校正(如仿射变换)或改用深度学习模型(如cnn)提升鲁棒性。
校验位验证:识别完成后,可通过身份证校验位公式(第18位=前17位的加权和模11)验证结果合法性。
七、效果展示
运行代码后,终端会输出识别出的18位身份证号,同时窗口会显示带红色矩形框和数字标记的身份证图像(如下示例):
识别结果:11010119900101123x
以上就是基于opencv的身份证号码识别完整实现,代码可直接复现,如需优化可针对具体场景调整参数或替换识别模型~
总结
到此这篇关于基于opencv与python实现身份证号码识别的文章就介绍到这了,更多相关opencv与python身份证号码识别内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论