mysql 分库分表深度指南:从策略到落地
当单表数据突破 5000万行 时,b+树索引深度达到5层,磁盘i/o暴增,简单查询耗时超10秒。此时分库分表成为必然选择。本文将详解 shardingsphere/mycat 中间件选型、分片键设计哲学及 snowflake 基因改造方案。
一、分库分表核心策略与时机
1.1 什么时候必须分库分表?
触发条件 :
- 单表行数:> 5000万行(b+树深度增加导致随机i/o剧增)
- 单表大小:> 200gb(备份时间窗口>6小时)
- 写并发:> 5000 qps(主从延迟>15分钟)
- 查询耗时:简单查询>1秒
架构演进路径:
- 垂直分库:按业务拆分(用户库、订单库),解决耦合问题
- 垂直分表:大字段拆分到扩展表,单表体积减少60%
- 水平分表:单库内分表,缓解单表压力
- 水平分库:跨实例分片,支撑亿级数据
1.2 分片类型对比
| 分片类型 | 拆分维度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 垂直分库 | 业务模块 | 业务清晰,隔离故障 | 跨库事务复杂 | 微服务化改造 |
| 垂直分表 | 字段冷热 | 减少单表大小,提升缓存命中率 | 增加 join 查询 | 大字段(text/blob)分离 |
| 水平分表 | 行数据 | 单库内优化,无分布式事务 | 无法突破单库性能瓶颈 | 数据量<5000万 |
| 水平分库 | 行数据 | 无限扩展,支撑 pb 级数据 | 分片键设计复杂 | 10亿+订单、日志场景 |
二、中间件选型:shardingsphere vs mycat vs shardingcore
2.1 三大中间件核心能力对比
| 特性 | shardingsphere | mycat | shardingcore |
|---|---|---|---|
| 定位 | 生态化平台(jdbc + proxy + sidecar) | 独立中间件(proxy) | .net 生态分片框架 |
| 架构模式 | 支持 jdbc 和 proxy 混合部署 | 仅 proxy 模式 | 仅 jdbc 模式 |
| sql 支持 | 完整支持(子查询、union、join) | 部分支持(复杂 sql 需优化) | 完整支持(linq 集成) |
| 分布式事务 | xa、seata 柔性事务 | xa 弱事务 | 依赖外部事务方案 |
| 数据迁移 | 提供 scaling 迁移工具 | 手动迁移为主 | 支持运行时动态建表 |
| 社区活跃度 | apache 顶级项目,持续更新 | 社区维护放慢 | .net 生态活跃 |
| 性能 | jdbc 模式性能损耗<3% | 网络代理损耗 10-15% | 与原生 ef core 持平 |
| 云原生 | 支持 k8s operator | 支持较弱 | 需自建 |
选型建议:
- java 生态 + 复杂查询:首选 shardingsphere(功能最完整)
- 遗留系统 + 快速接入:考虑 mycat(无需改代码)
- .net 项目:必选 shardingcore(无缝集成 ef core)
2.2 shardingsphere 架构详解
混合部署模式:
# sharding-proxy 配置示例(透明代理)
schemaname: order_db
datasources:
ds_0: { url: jdbc:mysql://db0:3306/order_db0, ... }
ds_1: { url: jdbc:mysql://db1:3306/order_db1, ... }
rules:
- !sharding
tables:
orders:
actualdatanodes: ds_${0..1}.orders_${0..15}
tablestrategy:
standard:
shardingcolumn: order_id
shardingalgorithmname: gene_hash
shardingalgorithms:
gene_hash:
type: class_based
props:
strategy: standard
algorithmclassname: com.example.geneshardingalgorithmjdbc 模式优势:应用直连数据库,无网络代理损耗,性能接近原生 sql。
2.3 mycat 快速接入
核心配置(schema.xml):
<schema name="order_db" checksqlschema="true">
<table name="orders" datanode="dn$0-15" rule="mod-long" />
</schema>
<datanode name="dn0" datahost="dh0" database="order_db0" />
<datanode name="dn1" datahost="dh0" database="order_db1" />
<datahost name="dh0" balance="1" writetype="0" dbtype="mysql">
<writehost host="hostm1" url="db0:3306" user="root" password="xxx"/>
<readhost host="hosts1" url="db1:3306" user="root" password="xxx"/>
</datahost>适用场景:遗留系统无法修改代码时,通过 mycat 透明代理实现分片。
三、分片键选择:架构设计的关键战役
3.1 分片键选择三原则
原则1:离散性(避免数据热点)
-- 错误:status 只有 3 个值,导致 3 个分片成为热点 partition by hash(status) partitions 64; -- 只有 3 个分区有数据 -- 正确:user_id 哈希,数据均匀分布 partition by hash(user_id) partitions 64;
原则2:业务相关性(80%查询需携带)
订单系统高频查询: 1. 用户查历史订单 → 必须带 user_id ✅ 2. 商家查订单 → 必须带 merchant_id ✅ 3. 客服按订单号查 → 必须带 order_no ✅ 分片键选择:user_id(覆盖场景最多)
原则3:稳定性(值不随业务变更)
-- 错误:手机号可能变更,导致数据迁移 -- 正确:user_id 是主键,永不改变
3.2 高级分片策略
基因分片:订单系统的终极方案
问题:订单系统有三大查询维度(user_id, merchant_id, order_no),如何保证每个维度都能快速定位分片?
解决方案:将 user_id 基因嵌入订单号中
snowflake 改造:
// 64位id结构:符号位(1) + 时间戳(41) + 分片基因(12) + 序列号(10)
public class orderidgenerator {
private static final int gene_bits = 12; // 12位基因支持4096个分片
public static long generateid(long userid) {
long timestamp = system.currenttimemillis() - 1288834974657l;
long gene = userid & ((1 << gene_bits) - 1); // 提取user_id后12位作为基因
long sequence = getnextsequence();
return (timestamp << 22) | (gene << 10) | sequence;
}
// 从订单id反推分片位置
public static int getshardkey(long orderid) {
return (int) ((orderid >> 10) & 0xfff); // 提取中间12位基因
}
}路由逻辑:
public class ordershardingrouter {
private static final int db_count = 8; // 8个库
private static final int table_count = 16; // 每库16张表
public static string route(long orderid) {
int gene = orderidgenerator.getshardkey(orderid);
int dbindex = gene % db_count; // 基因决定库
int tableindex = gene % table_count; // 基因决定表
return string.format("order_db_%d.orders_%d", dbindex, tableindex);
}
}突破点:
- ✅ 用户查询:用 user_id 直接定位分片
- ✅ 订单号查询:从 order_id 提取基因定位分片
- ✅ 数据均匀:user_id 后12位哈希分布随机,避免热点
一致性哈希:平滑扩容方案
传统取模问题:user_id % 8 扩容到 16 时,87.5% 数据需迁移。
一致性哈希:将哈希空间虚拟为 2^32 个节点,数据映射到虚拟节点,扩容时仅迁移相邻节点数据
实现框架:
// 使用 ketama 算法
public class consistenthashsharding {
private final sortedmap<long, string> circle = new treemap<>();
public void addserver(string server) {
for (int i = 0; i < 160; i++) { // 160个虚拟节点
circle.put(hash(server + "-" + i), server);
}
}
public string getserver(long key) {
if (circle.isempty()) return null;
long hash = hash(key);
sortedmap<long, string> tailmap = circle.tailmap(hash);
hash = tailmap.isempty() ? circle.firstkey() : tailmap.firstkey();
return circle.get(hash);
}
}四、全局id生成:snowflake 基因注入方案
4.1 snowflake 标准结构
64位id组成:
位段分布: 0-0 : 符号位(1位,始终为0) 1-41 : 时间戳(41位,支持69年,从2020起算) 42-52 : 机器id(10位,支持1024个节点) 53-63 : 序列号(12位,每毫秒4096个id)
问题:标准 snowflake 无法携带分片基因,路由需查询映射表。
4.2 基因注入改造
改造后结构:
0-0 : 符号位(1位) 1-41 : 时间戳(41位)- 支持到 2089年 42-53 : 分片基因(12位)- 支持4096个分片 54-63 : 序列号(10位)- 每毫秒1024个id
java 实现:
public class genesnowflake {
private final long twepoch = 1288834974657l; // 起始时间戳
private final long genebits = 12l; // 基因位数
private final long sequencebits = 10l; // 序列号位数
private final long geneshift = sequencebits; // 基因左移10位
private final long timestampshift = genebits + sequencebits; // 时间戳左移22位
public synchronized long nextid(long userid) {
long timestamp = system.currenttimemillis();
long gene = userid & ((1 << genebits) - 1); // 提取基因
long sequence = getsequenceinsamems(timestamp); // 毫秒内序列号
return ((timestamp - twepoch) << timestampshift) |
(gene << geneshift) |
sequence;
}
}性能指标:
- 生成速度:单节点 > 10万 id/秒
- 趋势递增:时间戳高位,保证数据库写入性能
- 零依赖:无需 redis、db,纯内存生成
4.3 id 反解与分片定位
从 order_id 提取路由信息:
// 提取基因(分片键)
public static int extractgene(long orderid) {
// 基因位于第10-21位:orderid >> 10 & 0xfff
return (int) ((orderid >> 10) & 0xfff);
}
// 提取生成时间
public static date extracttime(long orderid) {
long timestamp = (orderid >> 22) + twepoch;
return new date(timestamp);
}
// 完整路由示例
public class orderservice {
public order getorderbyid(long orderid) {
int gene = extractgene(orderid);
string dbtable = ordershardingrouter.routebygene(gene);
return executequery("select * from " + dbtable + " where order_id = ?", orderid);
}
}五、跨分片查询:三大解决方案
5.1 异构索引表(最常用)
方案:在 elasticsearch 中建立二级索引,存储分片路由信息
es 索引结构:
{
"order_index": {
"mappings": {
"properties": {
"order_no": { "type": "keyword" },
"shard_key": { "type": "integer" }, // 分片基因
"user_id": { "type": "long" },
"merchant_id": { "type": "long" }
}
}
}
}查询流程:
// 商家查询订单(先查es定位分片)
public list<order> getordersbymerchant(long merchantid) {
// 1. es 中查询 shard_key
searchresponse response = esclient.search(
new searchrequest("order_index")
.source(new searchsourcebuilder()
.query(querybuilders.termquery("merchant_id", merchantid))
.fetchfield("shard_key")
.size(10000))
);
// 2. 按 shard_key 分组
map<integer, list<long>> shardgroups = groupbyshard(response);
// 3. 并发查询各分片
return shardgroups.entryset().parallelstream()
.map(entry -> queryshard(entry.getkey(), entry.getvalue()))
.flatmap(list::stream)
.collect(collectors.tolist());
}5.2 全局二级索引(gsi)
shardingsphere 实现:
-- 创建全局索引(自动同步到指定存储节点)
create sharding global index idx_merchant on orders(merchant_id)
by sharding_algorithm(merchant_hash)
with storage_unit(ds_0, ds_1);
-- 查询时自动路由
select * from orders where merchant_id = 10086;
-- shardingsphere 自动改写为:先查 gsi 表获取 order_id,再路由到主表适用场景:低频但强一致性的跨分片查询
5.3 cqrs 模式:读写分离
架构设计:
写操作(command): 应用服务 → 分片路由 → 写入分片库 读操作(query): 应用服务 → es/hbase → 聚合结果
优势:
- 写操作保持分片优势
- 读操作通过 es 实现全文检索、聚合
- 避免跨分片 join
六、数据迁移:双写方案与灰度切换
6.1 双写架构
迁移期架构:


双写伪代码:
public void createorder(order order) {
try {
// 1. 写新库(主库)
ordernewdao.insert(order);
// 2. 写旧库(备份)
orderolddao.insert(order);
} catch (exception e) {
// 3. 新库失败必须回滚旧库
if (isnewsuccess()) {
ordernewdao.delete(order.getid());
}
throw e;
}
}关键原则:
- 新库优先:主写新库,成功后再写旧库
- 失败回滚:新库失败需删除旧库数据,保证最终一致性
- 监控告警:双写延迟>1秒触发告警
6.2 灰度切换四阶段
| 阶段 | 操作 | 流量比例 | 回滚策略 |
|---|---|---|---|
| 1. 双写阶段 | 新旧库同时写入 | 0% | 可随时切回旧库 |
| 2. 全量迁移 | 历史数据分批导入 | 0% | 校验收据 |
| 3. 增量验证 | 实时比对数据一致性 | 0% | 自动修复不一致 |
| 4. 灰度引流 | 按用户id百分比切换 | 1% → 50% → 100% | 发现问题立即回滚 |
切换命令:
// 动态分片路由(按用户id灰度)
public string routebyuserid(long userid) {
if (userid <= 10000) { // 1%用户切新库
return "order_new";
} else {
return "order_old";
}
}七、避坑指南与性能陷阱
7.1 热点数据分片倾斜
现象:某网红店铺订单全部分到同一分片,导致该分片成为热点
根因:merchant_id 哈希不均,大商家数据量占 30%
解决方案:
-- 复合分片键:(merchant_id + user_id) % 1024
-- 路由逻辑:将大商家数据按 user_id 二次打散
public int getshardkey(long merchantid, long userid) {
if (isbigmerchant(merchantid)) {
return (int) ((merchantid * 31 + userid) % 1024);
} else {
return (int) (merchantid % 1024);
}
}7.2 分布式事务:最终一致性方案
问题:跨库事务无法使用本地 acid
rocketmq 最终一致性:
@transactional
public void createorder(order order) {
// 1. 本地事务:写订单主库
orderdao.insert(order);
// 2. 发送事务消息(半消息)
transactionsendresult result = rocketmqtemplate.sendmessageintransaction(
"order_create_event",
messagebuilder.withpayload(order.tojson()).build(),
null
);
// 3. 消息确认后,下游消费加积分、扣库存
}
// 消费者异步处理
@rocketmqmessagelistener(topic = "order_create_event")
public void handleevent(orderevent event) {
bonusservice.addpoints(event.getuserid()); // 异步加积分
inventoryservice.deduct(event.getskuid()); // 异步扣库存
}优势:避免分布式锁,吞吐量提升 10 倍
7.3 跨分片分页陷阱
现象:limit 100, 10 跨分片查询需扫描所有分片,内存聚合后排序,性能极差
解决方案:
-- 方案1:业务折衷(禁用深分页,仅支持前100页)
-- 方案2:es 聚合查询(推荐)
get /order_index/_search
{
"from": 100,
"size": 10,
"sort": [{"create_time": "desc"}]
}
-- 方案3:游标分页(记录上次查询的 order_id)
select * from orders
where create_time < '2024-01-01' and order_id < #{lastorderid}
order by create_time desc limit 10;八、性能指标与架构演进
8.1 拆分前后性能对比
| 场景 | 拆分前 | 拆分后 | 提升倍数 |
|---|---|---|---|
| 用户订单查询 | 3200ms | 68ms | 47倍 |
| 商家订单导出 | 超时失败 | 8秒 | 可用 |
| 全表统计 | 不可用 | 1.2秒(近似) | 可用 |
| 写入并发 | 2000 qps | 8000 qps | 4倍 |
8.2 分库分表架构最佳实践
1. 分片键选择大于努力
// 基因分片是订单系统的最佳拍档 // 12位基因支持 4096 个分片 = 8库 × 16表 × 32冗余
2. 预留扩容空间
-- 初始设计:8库 × 16表 = 128分片 -- 支持单分片 500万行 → 总容量 6.4亿行 -- 预留 2 年数据增长
3. 避免过度设计
// 小表(<1000万行)无需分片 // 大表关联查询:优先冗余字段,避免跨分片 join
4. 监控驱动优化
-- 监控分片倾斜率 select db, table_name, count(*) as rows from information_schema.tables where table_schema like 'order_db_%' group by db, table_name having rows > avg(rows) * 1.5; -- 找出超平均分片50%的热点
8.3 终极架构方案
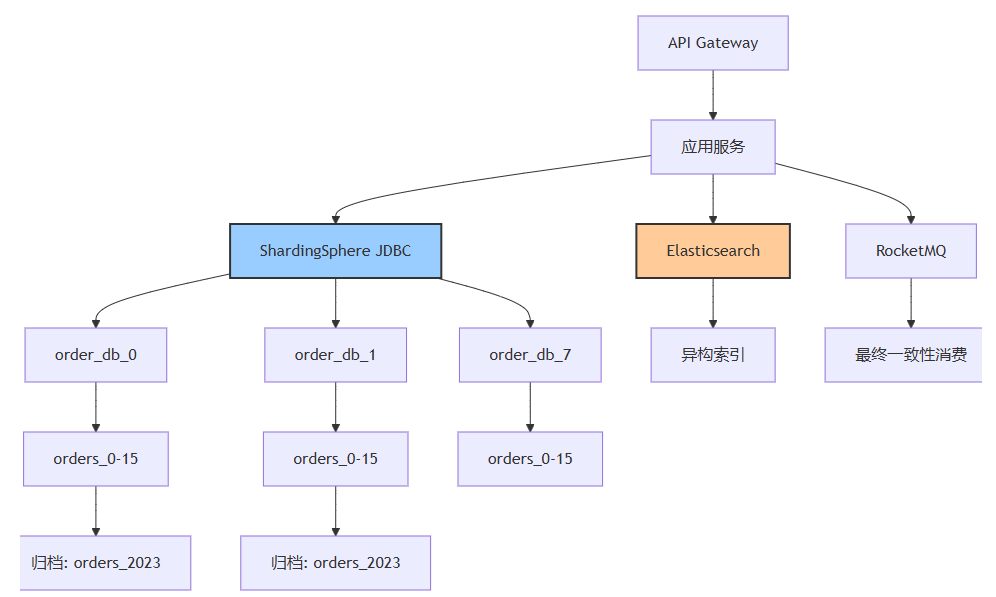
核心分层:
- 路由层:shardingsphere 负责分片
- 索引层:es 处理跨分片查询
- 消息层:rocketmq 保证最终一致性
- 归档层:历史数据迁移至 oss
总结
| 决策点 | 推荐方案 | 避免方案 |
|---|---|---|
| 分片键 | user_id + 基因注入 | 手机号、状态码 |
| 中间价 | shardingsphere (java) | 自研(成本高) |
| 全局id | snowflake 基因改造 | uuid(无序) |
| 跨分片查询 | es 异构索引 | 跨库 join |
| 数据迁移 | 双写 + 灰度 | 停机迁移 |
| 分布式事务 | 最终一致性(mq) | xa(性能差) |
黄金法则:分库分表不是架构的终点,而是数据治理的起点。真正的架构艺术,是在分与合之间找到平衡点,通过基因分片实现数据自治,通过 es 索引实现查询自由,通过 mq 实现事务自由,最终支撑从 10亿 到 100亿 的平滑演进。
到此这篇关于mysql分库分表深度指南之从策略到落地的文章就介绍到这了,更多相关mysql分库分表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论