1.beautifulsoup4简介
1.1 bs4与lxml
开门见山!我们先来聊聊bs4是个啥,它能干啥,bs4是一个从html和xml文件中提取数据的python库,它可以将复杂html文件转换为一个复杂的树形结构,这棵树的每一个结点都是python对象,所有对象都可以归纳为4类,我们在后面会说
beautifulsoup会自动将输入文档转换为unicode编码,将输入文档转换为utf-8编码
lxml与bs4一样是优秀的python解释器,它也是,但是这二者有什么样的区别,决定了我们为什么选择beautifulsoup,lxml是从文档的局部入手,只能局部遍历,但bs4就不一样了,它会载入整个文档,解析整个dom树,正是因为这个工程量巨大,所以bs4会有很大的时间和空间的开销,整体性能是低于lxml的
但是我们使用beautifulsoup4必有其原因:bs4用来解析html比较简单,api设计也是非常的银性化(人性化)方便我们使用,它也支持css选择器,这对于解析整个dom树的bs4可谓是如虎添翼,它还支持python标准库中的html解析器和lxml的xml解析器
1.2 beautifulsoup的4类对象
我们前面说:“将复杂html文件转换为一个复杂的树形结构,这棵树的每一个结点都是python对象”,这些python可以大致分为4类:tag、navigablestring、beautifulsoup和comment,我们通过几个例子来熟悉一下这四类对象的使用方法:
- 1.tap 标签及其内容,但默认只拿到第一个
- 2.navigablestring 标签里的内容(字符串)
- 3.beautifulsoup 表示整个文档
- 4.comment 是一个特殊的navigablestring类型,但输出的内容不包含注释
首先第一步就是导包:from bs4 import beautifulsoup;然后通过文件操作的语句来打开我们项目中的一个html文件,用一个file对象接收我们的html文件后想要让beautifulsoup解析它,我们还需要传入一个解析器:html.parser
from bs4 import beautifulsoup
import re
file = open("./demo.html", "rb")
html = file.read().decode("utf-8")
# 通过html.parser解析器把我们的html解析成了一棵树
bs = beautifulsoup(html, "html.parser")
# 1.tap
print("1. tap的例子:获取title")
print(bs.title)
# 2.navigablestring
print("2. navigablestring的例子:获取title的string内容和div的属性")
print(bs.title.string)
print(bs.div.attrs) # 获取标签中的所有属性,并返回一个字典
# 3.beautifulsoup
print("3. beautifulsoup的例子:获取整个html文档的name")
print(bs.name)
# 4.comment
print("4. comment的例子:获取a的string")
print(bs.a.string)
按照以往管理咱来看看代码!从第7行开始我们对这四类对象做了实例解释,对应tap类型,我们打印了bs.title,即这个html文档的
标签的全部信息,第12、13行我们通过bs.title.string和bs.div.attrs打印了标签内的信息,title的string信息和div盒子的属性,后面的代码也是同样的道理
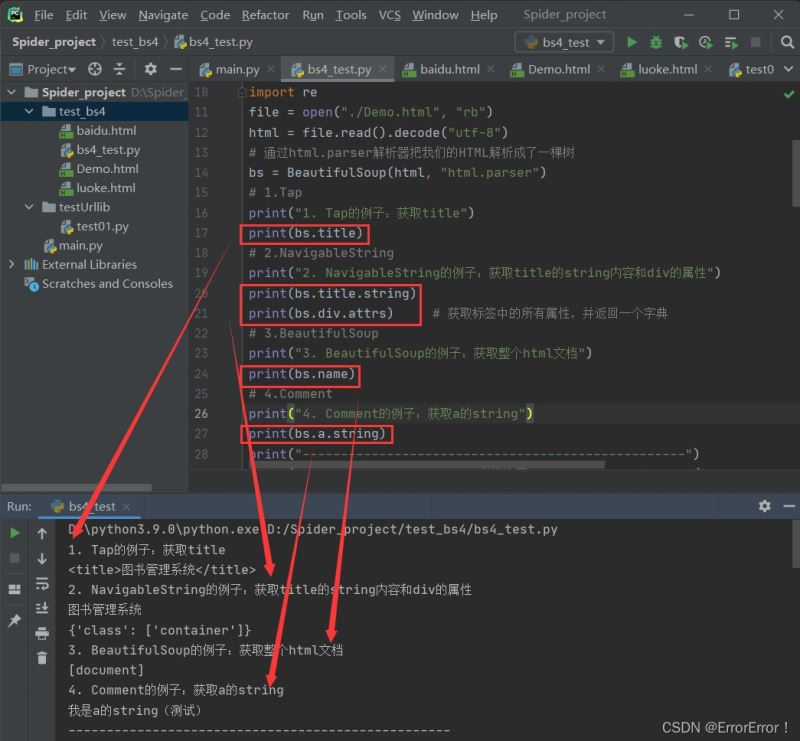
2.文档搜索方式
我们在通过网页的地址获取到其源码后不可能直接使用,所以我们在获取html源码后要先对其进行信息的定向搜索和筛选,然后再供我们使用,对应beautifulsoup的文档搜索,它提供了这样几种搜索方式:使用find_all()方法直接搜索、使用kwargs指定参数进行搜索、指定字符串搜索(常与正则表达式匹配使用)和设置limit参数进行搜索,我们依旧通过一些实际操作来掌握这些搜索方法
2.1 使用find_all()搜索
- 字符串过滤:会查找与字符串完全匹配的内容(注意一定是完全匹配)
- 正则表达式搜索:使用search()方法匹配内容,它搜索的对象依旧是一个标签,一个整体而不是拆分开来
t_list = bs.find_all("a")
t_list02 = bs.find_all(re.compile("a"))
对应字符串搜索,我们往find_all()方法中传入了一个字符串"a",进行整个文档的字符串过滤,只有含有单个"a"的内容才会被筛选出来,我们使用正则表达式搜索时往find_all()方法中传入re.compile(“a”)这样的一个匹配规则,它会返回所有含有"a"的标签内容,比如等都不例外
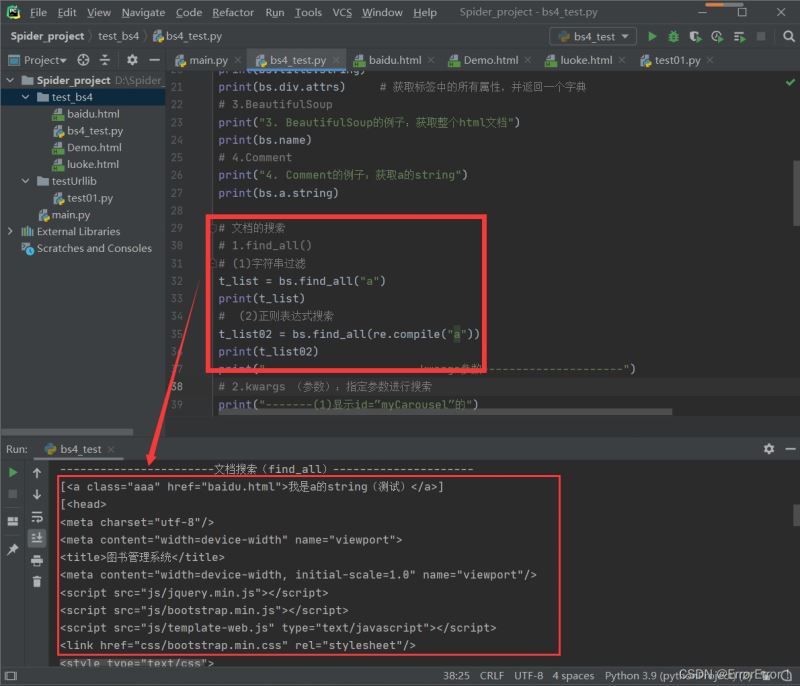
2.2 使用kwargs指定参数搜索
同样是使用find_all()方法进行文档搜索,但是我们往其中传入的参数完全不同,举两个例子,我们要搜索id="update"的标签、有class字样的标签还有href="baidu.html"的标签
# 2.kwargs (参数):指定参数进行搜索
print("-------(1)显示id=“update“的")
t_list03 = bs.find_all(id="update")
for item in t_list03:
print(item)
print("-------(2)只要有class就显示出来")
t_list04 = bs.find_all(class_=true)
for item in t_list04:
print(item)
print("-------(3)指定查找href=”baidu.html“")
t_list05 = bs.find_all(href="baidu.html" rel="external nofollow" )
for item in t_list05:
print(item)
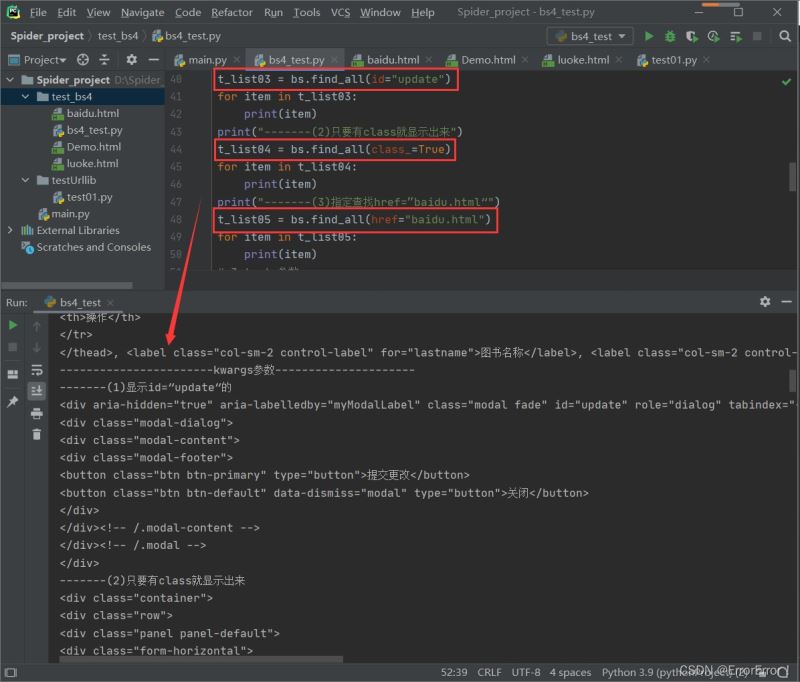
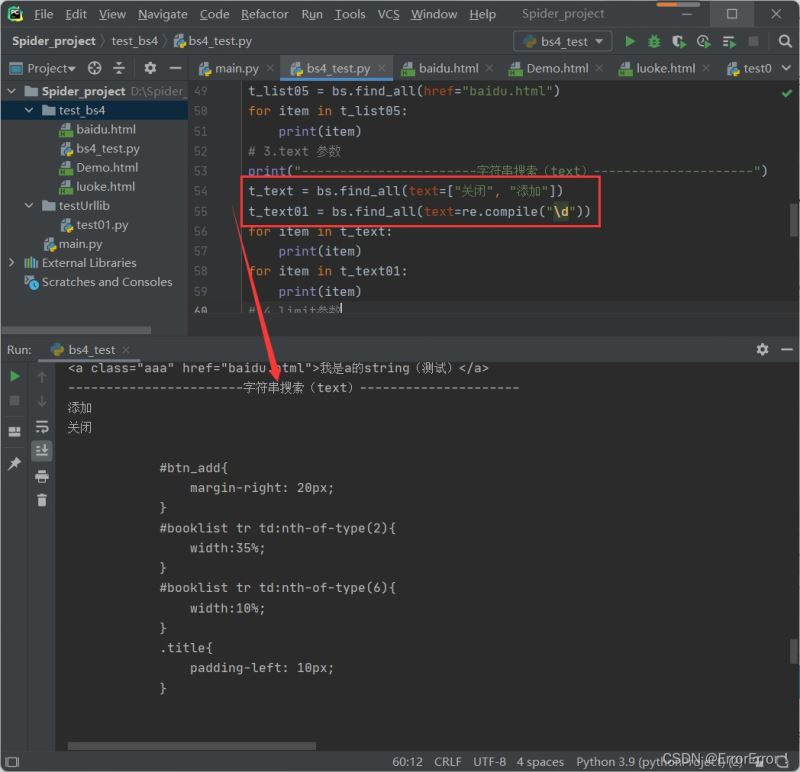
2.3 text参数搜索
使用text参数进行搜索就稍显轻松了,使用text搜索我们一般会使用列表和正则表达式搜索,这样才能达到我们定向筛选数据的效果,话不多说上代码
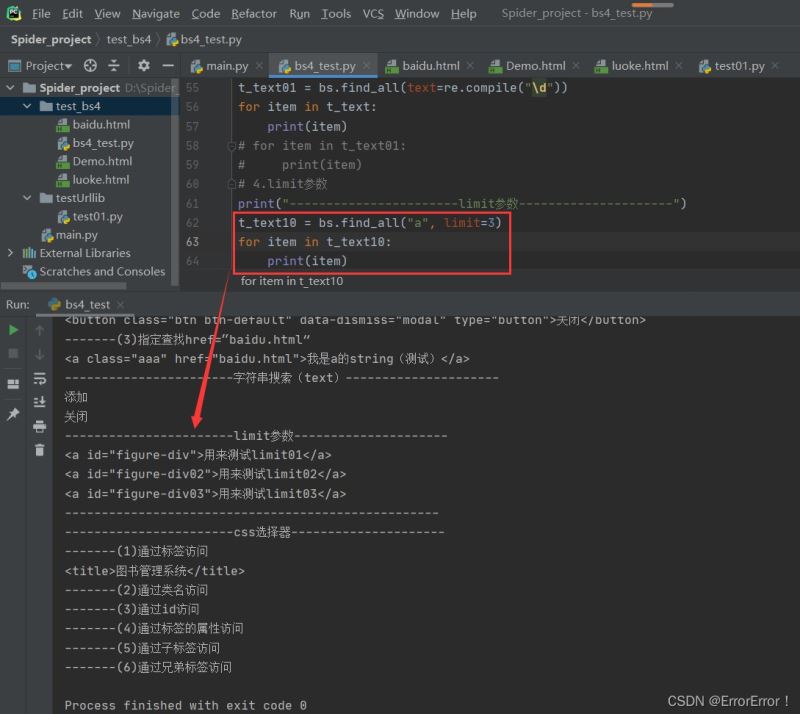
2.4 设置limit参数搜索
如果我们通过代码bs.find_all(class_=true)来筛选出存在"class"的部分,结果是有很多很多的,但是我们如果只想要3个结果,需要设置参数limit=x来满足我们的需求
t_text10 = bs.find_all("a", limit=3)
for item in t_text10:
print(item)
2.5 css选择器
相对来说通过css选择器来进行文档搜索就很丰富了,可以通过标签、类名、id名、标签属性和子标签等等方式来进行搜索,不一样的是我们会使用bs.select()方法来筛选
# css选择器
print("-------(1)通过标签访问")
t_css = bs.select('title') # 通过标签访问
for item in t_css:
print(item)
print("-------(2)通过类名访问")
t_css2 = bs.select(".col-sm-3") # 通过类名访问
for item in t_css2:
print(item)
print("-------(3)通过id访问")
t_css3 = bs.select("#btn_add")
for item in t_css3:
print(item)
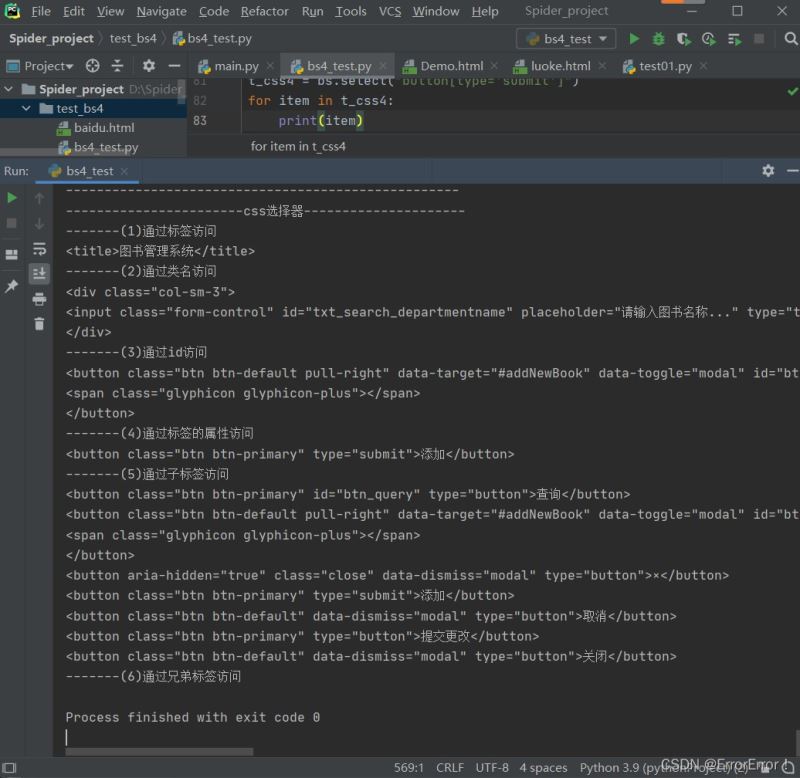
print("-------(4)通过标签的属性访问")
t_css4 = bs.select("button[type='submit']")
for item in t_css4:
print(item)
# 注意不能有空格
print("-------(5)通过子标签访问")
t_css5 = bs.select("div > button")
for item in t_css5:
print(item)
以上就是python使用beautifulsoup4解析html文档的操作指南的详细内容,更多关于python beautifulsoup4解析html的资料请关注代码网其它相关文章!





发表评论