在使用 numpy 进行数据处理时,我们经常会遇到把多个数组按照列(column)组合成一个矩阵的需求。最常见的场景包括:
- 将多个特征列合并成一个训练数据矩阵
- 合并 gt 与预测结果
- 将多个 1d 数组拼成 2d 数组
很多人第一时间会想到 np.hstack,但其实 np.column_stack 才是真正为“列拼接”设计的函数,尤其对 1d 数组的处理更加符合直觉。
本文将从原理、差异、示例到图解,全面讲解 np.column_stack 的使用。
1.np.column_stack是什么?
np.column_stack 的作用是:
将多个数组以“列”的方式拼接成一个新的二维数组。
如果输入数组是 1d,会先转换为列向量再拼接。
函数签名非常简单:
numpy.column_stack(tup)
- tup:一个序列(列表、元组均可),其中的每个元素是数组或可转为数组的对象。
- 返回:一个二维数组。
2. 为什么要用 column_stack?
很多初学者会把 column_stack 和 hstack 混用,但它们的行为有显著不同:
| 函数 | 输入 1d 数组时 | 输入 2d 数组时 | 用途 |
|---|---|---|---|
| column_stack | 自动转成列向量,并按列组合 | 按列组合(与 hstack 等价) | 组合特征列、更自然的列拼接 |
| hstack | 直接水平拼接成一行 | 按列组合 | 更接近简单拼接 |
简而言之:
👉 如果你把 1d 数组当成“数据列(column)”,应该用 column_stack。
3. 示例:从最基础到更实用
3.1 堆叠两个 1d 数组
import numpy as np a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) result = np.column_stack((a, b)) print(result)
输出:
[[1 4]
[2 5]
[3 6]]
解释:
- a 和 b 是 (3,) 的 1d 数组
- column_stack 会自动变成 (3,1) 列向量
- 按列合并得到 (3,2) 矩阵
这恰好符合我们对“合并两个特征列”的直觉。
3.2 堆叠两个 2d 数组
a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6], [7, 8]]) result = np.column_stack((a, b)) print(result)
输出:
[[1 2 5 6]
[3 4 7 8]]
二维数组时,column_stack 和 hstack 表现相同——横向拼接。
3.3 混合 1d 和 2d 数组
a = np.array([1, 2, 3]) b = np.array([[4], [5], [6]]) result = np.column_stack((a, b)) print(result)
输出:
[[1 4]
[2 5]
[3 6]]
1d 会自动转换为列向量,非常方便。
4.column_stack的可视化理解
下面是一个更直观的图示,有助于你彻底理解 column_stack 的工作原理:
1d → 列向量 → 按列组合
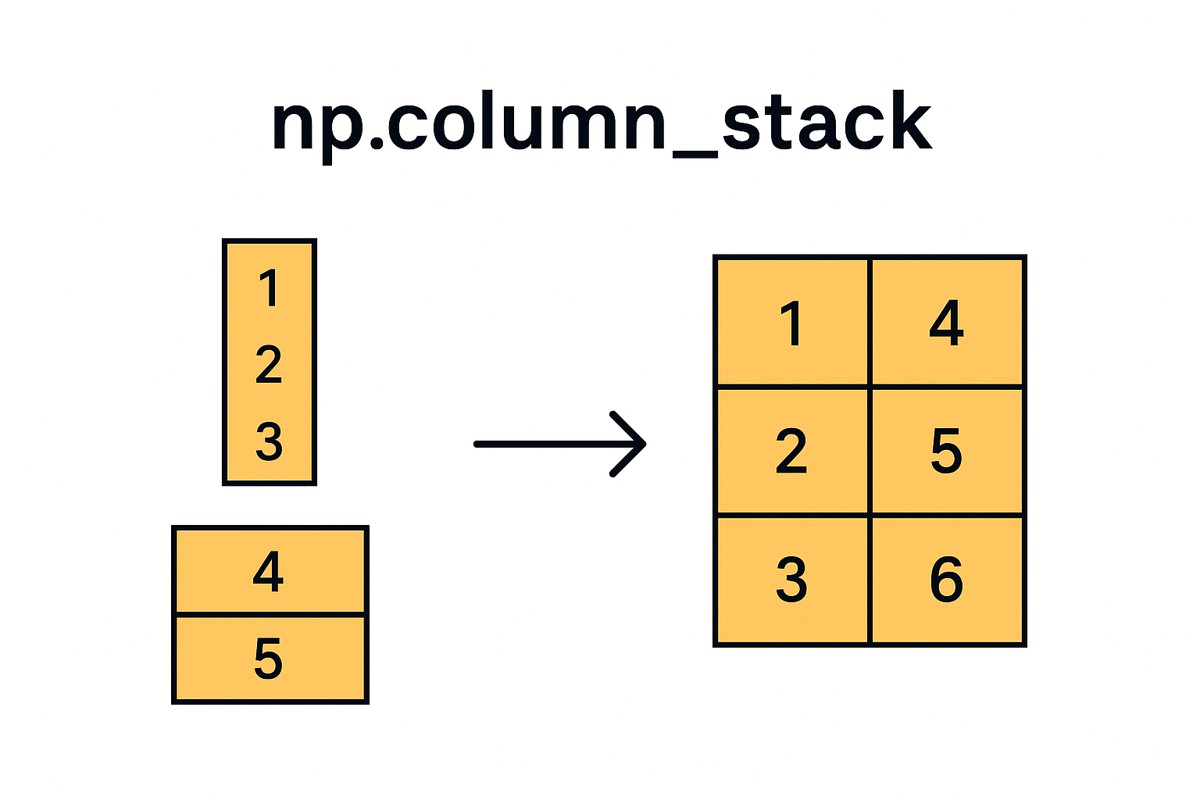
图中左侧是两个 1d 数组,它们被转换成两列,再拼成一个 2d 数组。
这个可视化呈现出了 column_stack 的核心:
👉 把每个输入都当成“一列”,然后拼接。
5. column_stack 的典型使用场景
5.1 拼接多个特征列(ml/数据分析常用)
age = np.array([18, 25, 32]) height = np.array([170, 180, 165]) x = np.column_stack((age, height))
即:
[[ 18 170]
[ 25 180]
[ 32 165]]
这就是典型的 特征矩阵 x。
5.2 合并 ground truth + 预测结果
gt = np.array([1, 0, 1]) pred = np.array([1, 1, 0]) np.column_stack((gt, pred))
5.3 将多个独立数组快速构建成一张表
name = ["a", "b", "c"] score = [90, 80, 95] table = np.column_stack((name, score))
6. 与其他堆叠函数的对比总结
| 函数 | 按列还是按行? | 对 1d 数组的处理 | 最适合用途 |
|---|---|---|---|
| column_stack | 按列 | 自动变“列” | 构建数据矩阵、特征拼接 |
| hstack | 按行水平拼接 | 直接拼成一维 | 简单拼接 |
| vstack | 按行堆叠 | 变为行向量 | 竖向堆数据 |
| stack | 增加新维度 | 完全自定义 axis | 自由组合三维/四维结构 |
建议记忆:
column_stack = feature_columns 的组合工具
对于机器学习、图像关键点、gt+pred 数据结构来说特别适用。
到此这篇关于深入理解numpy 的 np.column_stack的实现的文章就介绍到这了,更多相关numpy np.column_stack内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论