前言
logback应该是目前最流行的日志打印框架了,毕竟spring boot中默认的集成的日志框架也是logback。
在实际项目开发过程中,常常会遇到由于打印大量日志而导致程序并发降低,qps降低的问题,而通过logback异步日志输出则能很大程度上解决这个问题。
一、什么是appender?
官方介绍:

logback 将编写日志事件的任务委托给名为 appenders 的组件,appenders 必须实现ch.qos.logback.core.appender的接口。
简单来说,appender就是用来处理logback框架下日志输出事件的组件。
- appender接口的核心方法如下:
package ch.qos.logback.core;
import ch.qos.logback.core.spi.contextaware;
import ch.qos.logback.core.spi.filterattachable;
import ch.qos.logback.core.spi.lifecycle;
public interface appender<e> extends lifecycle, contextaware, filterattachable {
public string getname();
public void setname(string name);
//核心方法:处理日志事件
void doappend(e event);
}
其中doappend()方法是 logback 框架中最重要的方法。它负责将日志事件以适当的格式输出到适当的输出设备。
二、appender类图
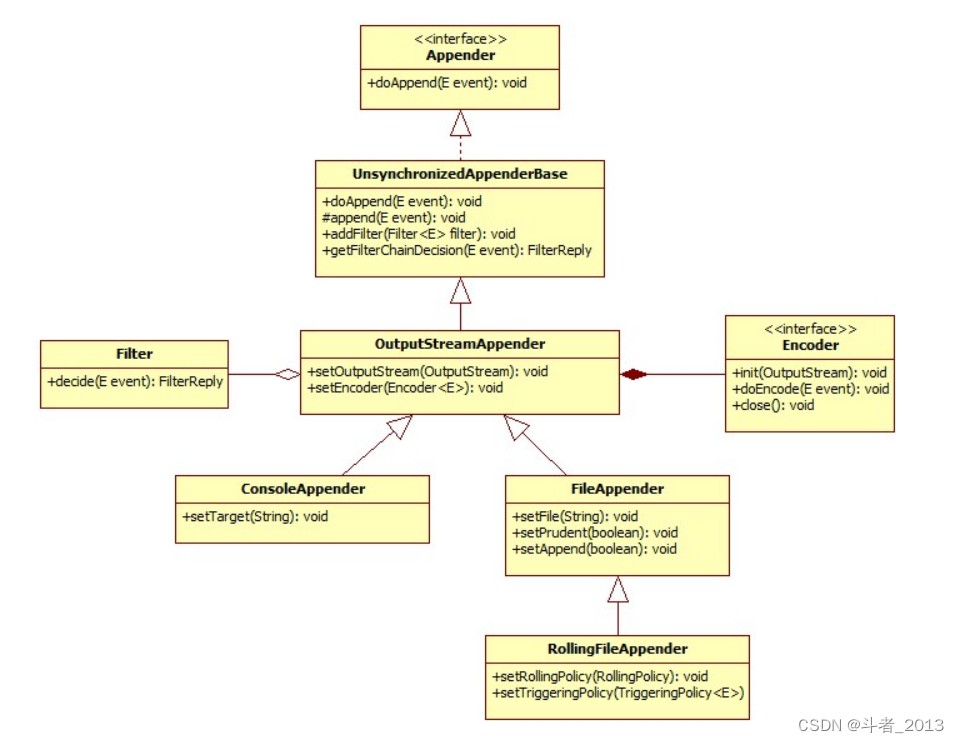
说明:
outputstreamappender 是另外三个附加程序的超类,即 consoleappender 和 fileappender,后者又是 rollingfileappender 的超类。
下一个图说明了 outputstreamappender 及其子类的类图。
1、控制台日志输出 consoleappender
- 配置示例:
<configuration>
<appender name="stdout" class="ch.qos.logback.core.consoleappender">
<encoder>
<pattern>%-4relative [%thread] %-5level %logger{35} - %msg %n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="stdout" />
</root>
</configuration>
说明:
控制台日志输出主要是在开发环境采用,比如在idea中开发时,可以清楚直观得在控制台看到运行日志,更方便程序调试。
当应用发布到测试环境、生产环境时,建议关闭控制台日志输出,以提高日志输出的吞吐量,减少不必要的性能开销。
2、单日志文件输出 fileappender
- 配置示例:
<configuration>
<appender name="file" class="ch.qos.logback.core.fileappender">
<!-- 日志文件名称 -->
<file>testfile.log</file>
<!-- 是否追加输出 -->
<append>true</append>
<!-- 立即刷新,设置成false可以提高日志吞吐量 -->
<immediateflush>true</immediateflush>
<encoder>
<!-- 日志输出格式 -->
<pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="file" />
</root>
</configuration>
弊端:
采用单日志文件输出日志,很容易导致日志文件的体积一直膨胀,不利于日志文件的管理和查看。
一般很少采用。
3、滚动日志文件输出 rollingfileappender
- 配置示例:
<configuration>
<appender name="file" class="ch.qos.logback.core.rolling.rollingfileappender">
<!-- 日志文件名称 -->
<file>logfile.log</file>
<rollingpolicy class="ch.qos.logback.core.rolling.timebasedrollingpolicy">
<!-- 按天滚动生成历史日志文件 -->
<filenamepattern>logfile.%d{yyyy-mm-dd}.log</filenamepattern>
<!-- 历史日志文件保存的天数和容量大小-->
<maxhistory>30</maxhistory>
<totalsizecap>3gb</totalsizecap>
</rollingpolicy>
<encoder>
<pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="file" />
</root>
</configuration>
说明:
通过rollingpolicy 配置日志文件的滚动生成策略,以及历史日志文件保存的天数和总容量大小,
是测试环境和生产环境最推荐的日志输出方式。
三、同步输出和异步输出比较
同步输出
- 传统的日志打印采用的是同步输出的方式,所谓同步日志,即当输出日志时,必须等待日志输出语句执行完毕后,才能执行后面的业务逻辑语句。
- 使用logback的同步日志进行日志输出,日志输出语句与程序的业务逻辑语句将在同一个线程运行。
- 在高并发场景下,日志数量不但激增,作为磁盘io来说,容易产生瓶颈,导致线程卡顿在生成日志过程中,会影响程序后续的主业务,降低程序的性能。

异步输出
- 使用异步日志进行输出时,日志输出语句与业务逻辑语句并不是在同一个线程中运行,而是有专门的线程用于进行日志输出操作,处理业务逻辑的主线程不用等待即可执行后续业务逻辑。
- 这样即使日志没有完成输出,也不会影响程序的主业务,从而提高了程序的性能。
四、异步日志实现原理asyncappender
logback异步输出日志是通过asyncappender实现的。asyncappender可以异步的记录 iloggingevents日志事件。
但是这里需要注意,asyncappender只充当事件分配器,它必须引用另一个appender才能完成最终的日志输出。
示意图:
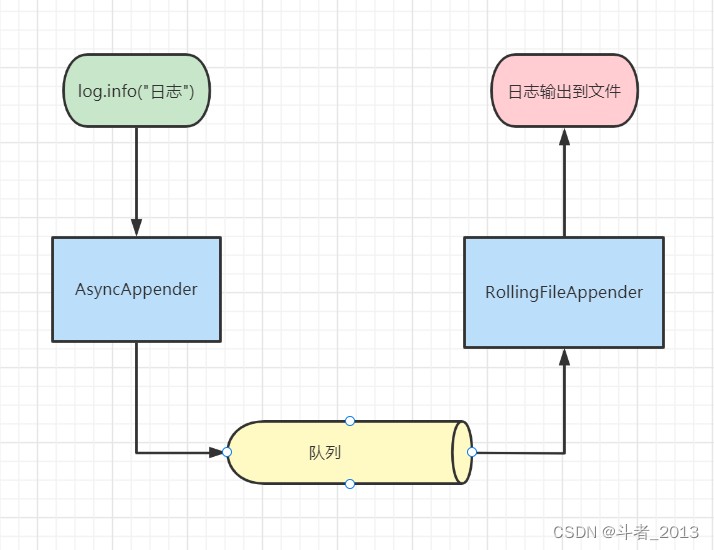
logback的异步输出采用生产者消费者的模式,将生成的日志放入消息队列中,并将创建一个线程用于输出日志事件,有效的解决了这个问题,提高了程序的性能。
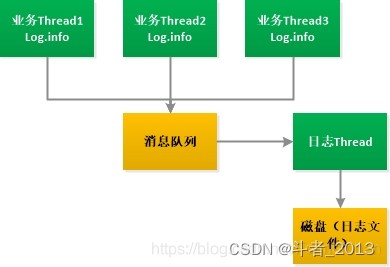
logback中的异步输出日志使用了asyncappender这个appender,通过看asyncappender源码,跟到它的父类asyncappenderbase,可以看到它有几个重要的成员变量:
appenderattachableimpl<e> aai = new appenderattachableimpl<e>(); blockingqueue<e> blockingqueue; asyncappenderbase<e>.worker worker = new asyncappenderbase.worker();
lockingqueue是一个队列,worker是一个消费线程,基本可以判定是个生产者消费者模式。
- 再看消费者(work)的主要代码:
while (parent.isstarted()) {
try {
e e = parent.blockingqueue.take(); //单条循环
aai.appendlooponappenders(e);
} catch (interruptedexception ie) {
break;
}
}
使用的是while单条循环 ,即logback异步输出是由一个消费者循环单条写入日志文件,工作流程如下图:
五、异步日志配置
配置示例:
配置异步输出日志的方式很简单,添加一个基于异步写日志的 appender,并指向原先配置的 appender即可。
<configuration>
<appender name="file" class="ch.qos.logback.core.fileappender">
<file>myapp.log</file>
<encoder>
<pattern>%logger{35} - %msg%n</pattern>
</encoder>
</appender>
<appender name="async" class="ch.qos.logback.classic.asyncappender">
<appender-ref ref="file" />
<!-- 设置异步阻塞队列的大小,为了不丢失日志建议设置的大一些,单机压测时100000是没问题的,应该不用担心oom -->
<queuesize>10000</queuesize>
<!-- 设置丢弃debug、trace、info日志的阀值,不丢失 -->
<discardingthreshold>0</discardingthreshold>
<!-- 设置队列入队时非阻塞,当队列满时会直接丢弃日志,但是对性能提升极大 -->
<neverblock>true</neverblock>
</appender>
<root level="debug">
<appender-ref ref="async" />
</root>
</configuration>
核心配置参数说明:
| 属性名 | 类型 | 描述 |
|---|---|---|
| queuesize | int | blockingqueue的最大容量,默认情况下,大小为256。 |
| discardingthreshold | int | 设置日志丢弃阈值, 默认情况下,当队列还有20%容量,他将丢弃trace、debug和info级别的日志,只保留warn和error级别的日志。 |
| includecallerdata | boolean | 提取调用方数据可能相当昂贵。若要提高性能,默认情况下,当事件添加到事件队列时,不会提取与事件关联的调用方数据。默认情况下,只复制线程名和 mdc 等“廉价”数据。通过将 includeecallerdata 属性设置为 true,可以指示此附加程序包含调用方数据。 |
| maxflushtime | int | 根据被引用的 appender 的队列深度和延迟,asyncappender 可能需要不可接受的时间来完全刷新队列。当 loggercontext 停止时,asyncappender stop 方法将等待工作线程完成直到超时。使用 maxflushtime 指定最大队列刷新超时(以毫秒为单位)。无法在此窗口内处理的事件将被丢弃。此值的语义与 thread.join (long)的语义相同。 |
| neverblock | boolean | 默认是false,代表在队列放满的情况下是否卡住线程。也就是说,如果配置neverblock=true,当队列满了之后,后面阻塞的线程想要输出的消息就直接被丢弃,从而线程不会阻塞。 |
默认情况下,event queue配置最大容量为256个events。如果队列已经满了,那么应用程序线程将被阻塞,无法记录新事件,直到工作线程有机会分派一个或多个事件。当队列不再达到最大容量时,应用程序线程可以再次开始记录事件。因此,当应用程序在其事件缓冲区的容量或附近运行时,异步日志记录就变成了伪同步。
这未必是件坏事,asyncappender异步追加器设计目的是允许应用程序继续运行,尽管需要稍微多一点的时间来记录事件,直到附加缓冲区的压力减轻。
优化 appenders 事件队列的大小以获得最大的应用程序吞吐量取决于几个因素。
下列任何或全部因素都可能导致出现伪同步行为:
- 大量的应用程序线程
- 每个应用程序调用都有大量的日志事件
- 每个日志事件都有大量数据
- 子级appenders的高延迟
为了保持事情的进展,增加队列的大小通常会有所帮助,代价是减少应用程序可用的堆。
为了减少阻塞,在缺省情况下,当队列容量保留不到20% 时,asyncappender 将丢失 trace、 debug 和 info 级别的事件,只保留 warn 和 error 级别的事件。
这种策略确保了对日志事件的非阻塞处理(因此具有优异的性能) ,同时在队列容量小于20% 时减少 trace、 debug 和 info 级别的事件。事件丢失可以通过将丢弃阈值属性设置为0(零)来防止。
六、性能测试
这部分自己还没时间做测试,引用网上的一些测试数据。
既然能提高性能的话,必须进行一次测试比对,同步和异步输出日志性能到底能提升多少倍?
服务器硬件
- cpu 六核
- 内存 8g
测试工具
- apache jmeter
1、同步输出日志
- 线程数:100
- ramp-up loop(可以理解为启动线程所用时间) :0 可以理解为100个线程同时启用
- 测试结果:
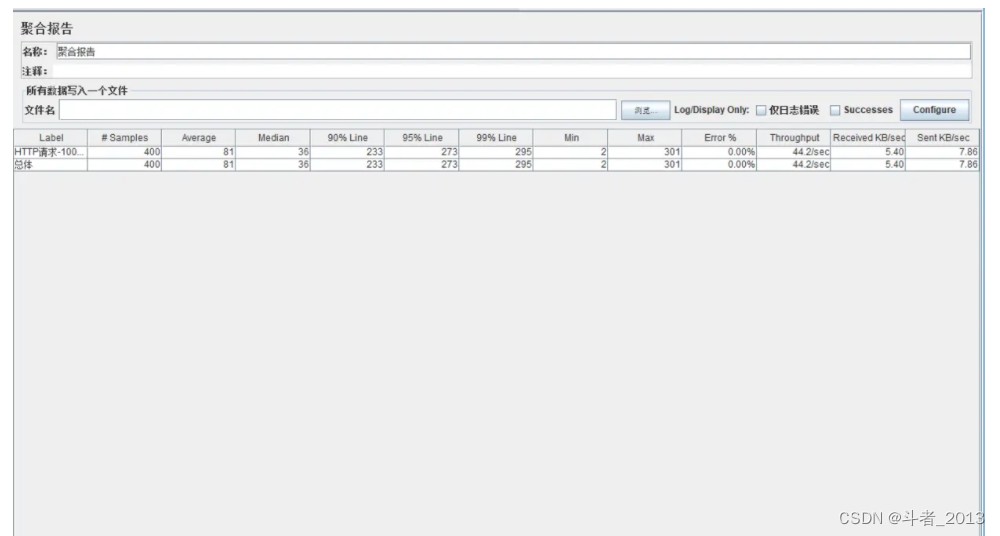
重点关注指标 throughput【tps】 吞吐量:系统在单位时间内处理请求的数量,在同步输出日志中 tps 为 44.2/sec
2、异步输出日志
- 线程数 100
- ramp-up loop:0
- 测试结果:
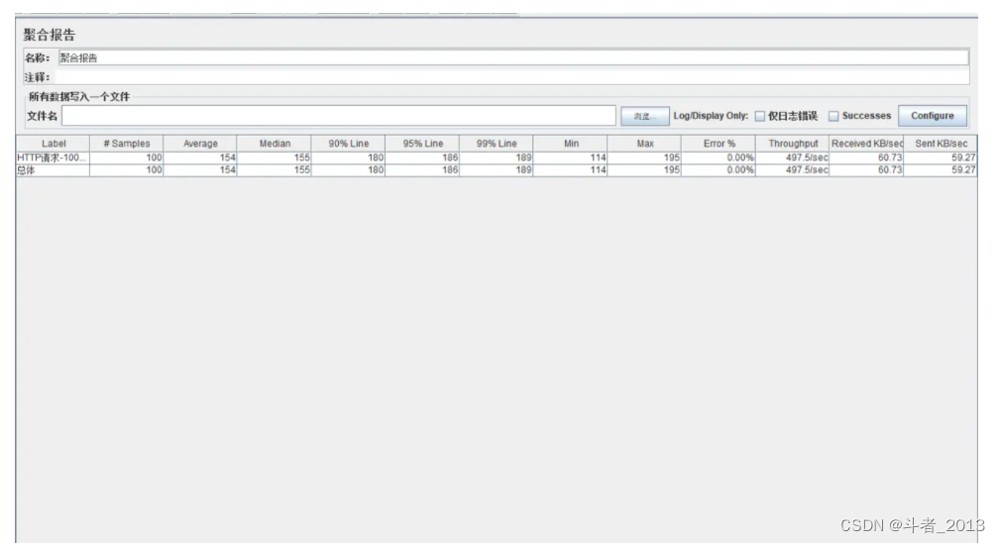
tps 为 497.5/sec , 性能提升了10多倍!!!
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论