在企业级应用和科研场景中,ppt 不再仅仅是演示工具,它更是一个承载了大量核心业务信息的非结构化数据库。方案说明、数据总结、流程逻辑,甚至隐藏在备注里的演讲稿,都可能是未来分析、归档和自动化流程的重要来源。
然而,这些内容通常被困在二进制文件里,无法直接参与系统处理。本文将从开发者角度出发,介绍如何解构 ppt 并提取文本、图片和表格,让你的演示文档从视觉展示工具进化为可操作的数据源。
一、 为什么要提取 ppt 上的内容
在部分人群的认知里,ppt 是信息的终点,因为它将项目展示给了客户或领导,已经完成了效果展示这项工作。但在数字化转型背景下,它其实是数据的起点。
- 企业知识库的流失: 大量高价值的汇报材料、分析报告、周报/月报只存在于 ppt 中,无法被搜索和复用。
- 数据孤岛: 财务或业务数据被做成了 ppt 图表,导致原始数值无法再利用,只能靠人工手动录入 excel。
- ai 时代的语料需求: 随着大模型(llm)和 rag(检索增强生成)技术的普及,ppt 里的非线性信息需要被转化为结构化文本,才能喂给 ai 进行分析。
总的来说就是: 仅仅把 ppt 当成文档已经不符合当前的需求,更理想的状态是将其当成一种可解析的数据载体。
二、 ppt 的内部结构与工程提取的难点
ppt 看起来是只是一张张幻灯片的堆叠,但其内部是由复杂的对象容器组成的。
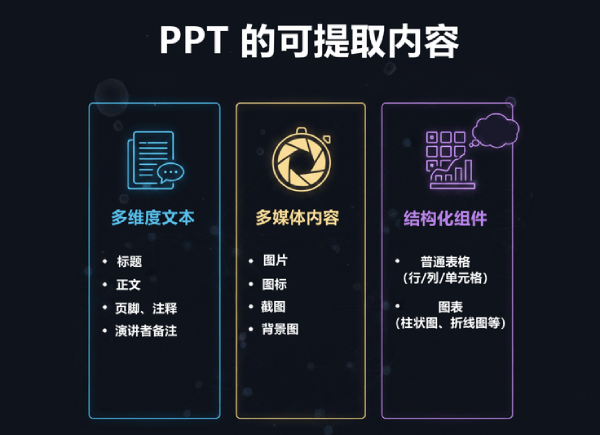
1. ppt 由哪些可提取内容组成
- 多维度文本: 包含标题、正文、页脚、注释,以及极具价值的演讲者备注。
- 多媒体内容: 插入的图片、图标、截图,甚至是作为业务背景的底图。
- 结构化组件: 普通表格(行/列/单元格)和图表(柱状图、折线图等)。
2. 为什么不建议直接复制 ppt 中的内容
- 非线性结构: ppt 是基于画布坐标的展示格式。同一页幻灯片里,文本可能散落在多个形状中,其在 xml 里的存储顺序并不等同于视觉阅读顺序。例如我们看到的位于最下方的段落中的文本,并不一定是最后添加的。
- 数据损耗: 简单复制图表只能得到截图,背后真实的分类标签和数值序列会完全丢失。
- 对象嵌套: ppt 中存在大量组合形状和 smartart,如果不进行递归解析,难以完整提取逻辑关系。
三、 工程化思路:ppt 内容提取的一般流程
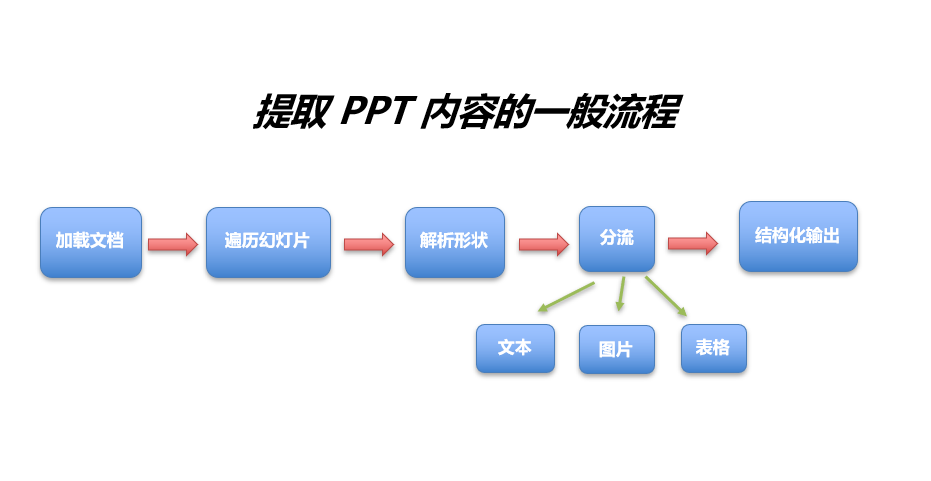
想要实现稳定提取内容,需要遵循 ppt 内容解构的思路:
- 加载文档: 使用解析引擎(如 spire.presentation)加载 pptx 文件。
- 遍历幻灯片: 以页面为基本单位进行扫描。
- 解析形状: 递归遍历页面中的每一个元素。
- 按类型分流:
- 文本: 提取字符串,并记录其空间坐标(用于排序)。
- 图片: 提取二进制流并关联其所在的 slide id。
- 表格: 还原行列结构,转化为二维数组。
- 结构化输出: 将结果封装为 json 或存入数据库,供下游系统调用。
四、 提取 ppt 文本:不只是 gettext 那么简单
在提取文本时,开发者需要考虑信息的层级与顺序。
- 空间解析逻辑: 为了保证提取出的文本符合一般阅读习惯,建议根据形状的
top(纵坐标)和left(横坐标)进行二次排序,避免提取结果东一句西一句,无法流畅阅读。 - 备注区的价值: 不管是注释还是演讲者笔记,它们容易被忽略,但却是 ppt 内容的深度补充。在 rag 场景中,备注提供的上下文往往比幻灯片上的几个关键词更重要。
下面我们使用 python 代码来展示如何提取幻灯片上的文本:
from spire.presentation.common import *
from spire.presentation import *
# 创建一个presentation对象
presentation = presentation()
# 加载pptx文件
presentation.loadfromfile("输入文档.pptx")
# 用于存储文本内容的列表
text = []
# 遍历每一页幻灯片
for slide in presentation.slides:
# 遍历每个形状
for shape in slide.shapes:
# 判断形状是否是iautoshape
if isinstance(shape, iautoshape):
# 遍历每个段落并获取文本内容
for paragraph in (shape if isinstance(shape, iautoshape) else none).textframe.paragraphs:
text.append(paragraph.text)
# 将文本内容写入到文件中
with open("幻灯片文本.txt", "w", encoding='utf-8') as f:
for s in text:
f.write(s + "\n")
# 释放presentation对象
presentation.dispose()
五、 提取图片:图片本身 vs 使用场景
在 ppt 中提取图片通常分为两种路径:
- 资产化归档: 获取并导出所有图片素材,用于内容审核或建立素材库。
- 上下文关联: 这是更有价值的做法——记录图片出现在哪一页、其上方是否有对应的标题。这样在后续检索时,系统能告诉你:“这张架构图是属于《xx系统设计方案》的第三页”。
下面代码简单展示了怎样从 ppt 中提取所有的图片,如需记录图片的信息,可以再进行调整。
from spire.presentation.common import *
from spire.presentation import *
# 创建presentation对象
ppt = presentation()
# 加载ppt文档
ppt.loadfromfile("示例.pptx")
# 遍历文档中所有图片
for i, image in enumerate(ppt.images):
# 提取图片
imagename = "提取图片/图_"+str(i)+".png"
image.image.save(imagename)
ppt.dispose()
六、 提取表格:容易被忽略的高价值数据
ppt 中的表格本身就是一种带有行列语义的结构化对象。在实际提取时,需要重点关注单元格的行列位置以及合并关系,否则在后续转换为 excel 或写入数据库时,很容易出现数据错位的问题。
在很多工程场景中,第一步并不是立刻生成 excel 文件,而是先完整还原表格的逻辑结构。只要行、列以及单元格之间的对应关系被准确保留下来,无论后续导出为 excel、json,还是写入数据库,都可以在此基础上完成。
spire.presentation 在遍历表格时,能够按行、按列访问每一个单元格,这使得我们可以在提取内容的同时保留表格的结构信息。下面的代码示例展示了如何逐行读取幻灯片中的表格,并将单元格内容保存为文本形式,方便进行后续结构化处理:
示例 python 代码:
from spire.presentation import *
from spire.presentation.common import *
# 创建一个presentation实例
presentation = presentation()
# 加载一个powerpoint文件
presentation.loadfromfile("示例.pptx")
tables = []
# 遍历所有幻灯片
for slide in presentation.slides:
# 遍历所有形状
for shape in slide.shapes:
# 检查形状是否是表格
if isinstance(shape, itable):
tabledata = ""
# 遍历所有行
for row in shape.tablerows:
rowdata = ""
# 遍历行中的所有单元格
for i in range(0, row.count):
# 获取单元格的值
cellvalue = row[i].textframe.text
rowdata += (cellvalue + "\t" if i < row.count - 1 else cellvalue)
tabledata += (rowdata + "\n")
tables.append(tabledata)
# 将表格写入文本文件
for idx, table in enumerate(tables, start=1):
filename = f"output/tables/table-{idx}.txt"
with open(filename, "w") as f:
f.write(table)
presentation.dispose()
七、 结构化输出:ppt → json / 业务数据
前面的步骤帮我们从 ppt 中拆解出了文本、图片和表格,但这些碎片化的数据如果只是散乱存放,依然难以被业务系统高效利用。在工程实践中,我们通常使用 json(一种轻量级的数据交换格式)将这些内容重新组织。
这种做法的逻辑是:建立物理实体(ppt)与数字对象(json)的一一映射。
下面我们展示怎样将一页幻灯片解构为 json:
{
"slide_index": 3,
"title": "2024q3 业务增长分析",
"content": {
"text_list": ["海外市场增长强劲", "供应链成本优化 5%"],
"tables": [
[["月份", "营收"], ["7月", "100w"], ["8月", "120w"]]
],
"notes": "此页数据未包含新收购的子公司部分。"
}
}
八、 典型应用场景
自动化报告对齐: 将历史 ppt 中的数据与财务系统自动对账。
智能搜索与 rag: 让企业 ai 能够根据 ppt 内容回答员工的问题。
内容审核: 批量检查演示文档中是否存在违规图片或过期陈述。
九、 总结
只有当 ppt 作为能被程序解析的数据载体时,它才是真正地进入了企业的生产力体系。借助专业成熟的开发库,如 spire.presentation,我们可以系统性地实现文本、图片、表格自动化提取,不仅是技术的提升,更是对数据价值的深度挖掘。
到此这篇关于python实现解构ppt并提取文本、图片和表格的文章就介绍到这了,更多相关python提取ppt内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论