一、背景与目标
在处理英文技术文档、论文或说明书时,常见的 pdf 翻译方案存在几个痛点:
- 翻译后版式错乱
- 图片、公式丢失
- 代码、url 被误翻译
- 中文字体无法正常显示
- 只能整页 ocr,无法保持原始排版
本文介绍一种基于 pymupdf(fitz)+ ollama 大模型的 pdf 翻译方案,目标是:
逐页、逐文本块翻译 pdf,自然语言翻译为中文,图片与版式完全保持不变
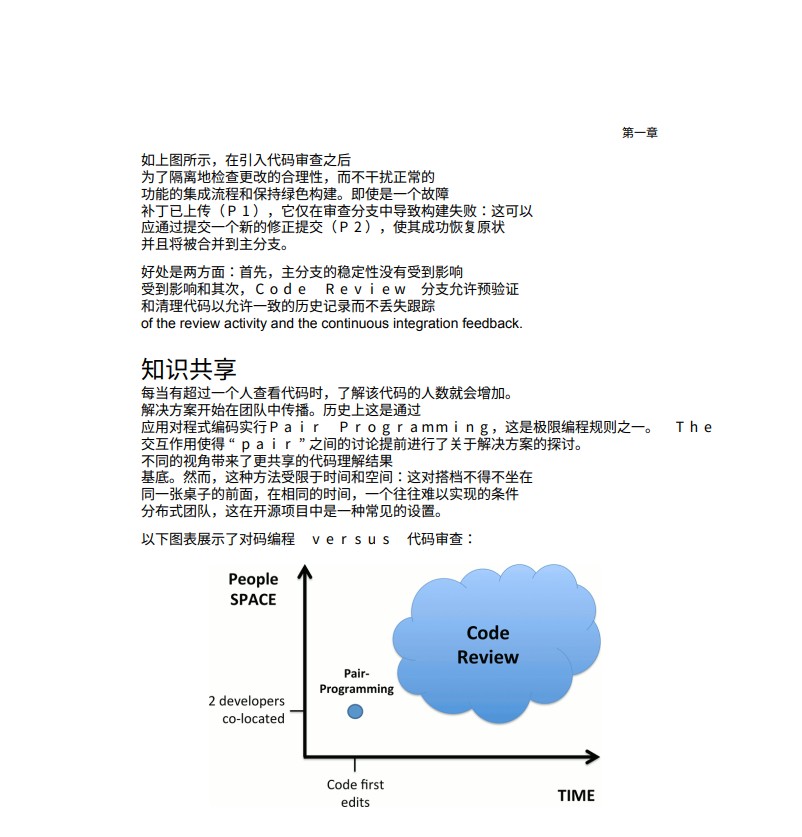
翻译后的效果如下图
二、整体技术方案
技术选型
| 模块 | 技术 |
|---|---|
| pdf 解析 | pymupdf(fitz) |
| 图片处理 | pymupdf pixmap |
| 大模型推理 | ollama |
| 翻译模型 | qwen2.5:7b |
| 输出方式 | 重新生成 pdf(逐页) |
核心思路
整个流程可拆解为 5 个步骤:
- 逐页解析 pdf
- 提取文本 span(包含字体、字号、位置)
- 提取并复制原始图片
- 使用大模型翻译自然语言文本
- 在原坐标位置重新绘制文本,生成新 pdf
三、核心类设计:pdftranslator
整个翻译逻辑被封装在 pdftranslator 类中,职责清晰、结构合理。
必须安装(核心依赖)
pip install pymupdf pip install ollama pip install pillow
完整代码
import fitz # pymupdf
import os
import tempfile
from pil import image
import io
import ollama
class pdftranslator:
def __init__(self, source_pdf_path, model="qwen2.5:7b"):
"""
初始化pdf翻译器
args:
source_pdf_path (str): 源pdf文件路径
model (str): ollama模型名称
"""
self.source_pdf_path = source_pdf_path
self.doc = fitz.open(source_pdf_path)
self.model = model
def extract_text_and_positions(self, page_num):
"""
提取指定页面的文本及其位置信息
args:
page_num (int): 页面编号(从0开始)
returns:
list: 包含文本块信息的列表
"""
page = self.doc[page_num]
text_blocks = []
# 获取页面上的文本块
blocks = page.get_text("dict")["blocks"]
for block in blocks:
if "lines" in block: # 文本块
for line in block["lines"]:
for span in line["spans"]:
text_blocks.append({
"text": span["text"],
"bbox": span["bbox"], # 边界框 [x0, y0, x1, y1]
"size": span["size"],
"font": span["font"],
"color": span["color"]
})
return text_blocks
def extract_images(self, page_num):
"""
提取指定页面的图片
args:
page_num (int): 页面编号(从0开始)
returns:
list: 包含图片信息的列表
"""
page = self.doc[page_num]
image_list = []
# 获取页面上的图片
image_list_raw = page.get_images()
for img_index, img in enumerate(image_list_raw):
xref = img[0]
pix = fitz.pixmap(self.doc, xref)
# 如果是cmyk图片,转换为rgb
if pix.n < 5:
img_data = pix.tobytes("png")
else:
pix1 = fitz.pixmap(fitz.csrgb, pix)
img_data = pix1.tobytes("png")
pix1 = none
# 获取图片在页面上的位置
img_rects = page.get_image_rects(xref)
image_info = {
"image_data": img_data,
"rect": img_rects[0] if img_rects else none,
"xref": xref
}
image_list.append(image_info)
pix = none
return image_list
def translate_text(self, text, dest_lang='zh'):
"""
使用ollama大模型翻译文本
args:
text (str): 要翻译的文本
dest_lang (str): 目标语言
returns:
str: 翻译后的文本
"""
try:
# 构建翻译提示,明确要求将英文翻译成中文,只返回翻译结果,保持原文格式
prompt = f"""请将以下英文文本翻译成中文,保持原文的格式、空格和标点符号,只返回翻译结果,不要添加任何解释。
翻译要求:
1. 所有代码内容(包括代码块、函数名、类名、变量名、命令、配置项等)必须保持原样,不得翻译。
2. 所有网址(以 http://、https://、www. 开头的链接)必须保持原样,不得翻译。
3. 所有数字保持原样,不得翻译或改写(包括整数、小数、百分比、版本号、时间、日期、编号等)。
4. 保持原文中的空格、换行、缩进等格式,确保翻译后格式一致。
5. 仅翻译自然语言描述性的英文文本,其余内容全部保持不变。
英文文本如下:
{text}
"""
print(f"正在翻译文本: {text[:50]}..." if len(text) > 50 else f"正在翻译文本: {text}")
# 调用ollama模型
response = ollama.chat(
model=self.model,
messages=[
{
'role': 'user',
'content': prompt
}
]
)
translated = response['message']['content'].strip()
print(f"翻译结果: {translated[:50]}..." if len(translated) > 50 else f"翻译结果: {translated}")
return translated
except exception as e:
print(f"翻译错误: {e}")
return text # 如果翻译失败,返回原文本
def create_translated_pdf(self, output_path, dest_lang='zh', start_page=0, end_page=none):
"""
创建翻译后的pdf文件,保持原有版面布局
args:
output_path (str): 输出pdf文件路径
dest_lang (str): 目标语言
start_page (int): 开始页面(从0开始)
end_page (int): 结束页面(从0开始,none表示到最后一页)
"""
# 确定页面范围
if end_page is none:
end_page = len(self.doc) - 1
else:
end_page = min(end_page, len(self.doc) - 1)
# 处理指定范围的页面
for page_num in range(start_page, end_page + 1):
print(f"正在处理第 {page_num + 1} 页...(共{len(self.doc)}页)")
# 创建新的pdf文档
new_doc = fitz.open()
# 获取原始页面信息
original_page = self.doc.load_page(page_num)
page_width = original_page.rect.width
page_height = original_page.rect.height
# 创建新页面
new_page = new_doc.new_page(width=page_width, height=page_height)
# 复制原始页面的布局和图片
original_page = self.doc[page_num]
# 复制图片
images = self.extract_images(page_num)
for img_info in images:
if img_info["rect"]:
# 插入原始图片
new_page.insert_image(img_info["rect"], stream=img_info["image_data"])
# 提取并翻译文本
text_blocks = self.extract_text_and_positions(page_num)
# 为了更好地保持版面,我们需要更精确地处理文本
for block in text_blocks:
if block["text"].strip(): # 避免空文本
translated_text = self.translate_text(block["text"], dest_lang)
# 计算文本位置
bbox = block["bbox"]
x0, y0, x1, y1 = bbox
# 创建文本插入点(使用左下角作为基点)
# fitz使用笛卡尔坐标系,y轴向上
point = fitz.point(x0, y0 + block["size"])
# 使用text writer来保持更好的版面
# 首先擦除原始文本区域(可选)
# 然后插入翻译后的文本
# 检查文本是否包含中文字符,如果是,则使用中文字体
if any(ord(char) > 127 for char in translated_text): # 包含非ascii字符(如中文)
try:
new_page.insert_text(
point,
translated_text,
fontsize=block["size"],
fontname="china-ss",
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
except:
# 如果内置字体失败,使用默认字体
new_page.insert_text(
point,
translated_text,
fontsize=block["size"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
else:
# 如果是英文文本,使用原始字体
try:
new_page.insert_text(
point,
translated_text,
fontsize=block["size"],
fontname=block["font"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
except:
new_page.insert_text(
point,
translated_text,
fontsize=block["size"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
else:
# 如果是空文本,直接复制原始文本(如空格等)
bbox = block["bbox"]
x0, y0, x1, y1 = bbox
point = fitz.point(x0, y0 + block["size"])
# 对于空文本块,也检查是否包含中文字符
if any(ord(char) > 127 for char in block["text"]): # 包含非ascii字符(如中文)
try:
new_page.insert_text(
point,
block["text"],
fontsize=block["size"],
fontname="china-ss",
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
except:
# 如果内置字体失败,使用默认字体
new_page.insert_text(
point,
block["text"],
fontsize=block["size"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
else:
# 如果是英文文本,使用原始字体
try:
new_page.insert_text(
point,
block["text"],
fontsize=block["size"],
fontname=block["font"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
except:
new_page.insert_text(
point,
block["text"],
fontsize=block["size"],
color=(0, 0, 0) # 强制使用黑色文字以确保可见
)
# 为每一页创建单独的pdf文件
page_output_path = output_path.replace('.pdf', f'_page_{page_num + 1}.pdf')
new_doc.save(page_output_path)
new_doc.close()
print(f"第 {page_num + 1} 页翻译完成,输出文件: {page_output_path}")
print(f"所有页面翻译完成!")
def get_page_count(self):
"""
获取pdf总页数
returns:
int: pdf总页数
"""
return len(self.doc)
def close(self):
"""
关闭文档
"""
if self.doc:
self.doc.close()
def main():
# 使用示例
source_pdf = "1.pdf"
output_pdf = "translated_1.pdf"
# 创建翻译器实例,使用ollama模型
translator = pdftranslator(source_pdf, model="qwen2.5:7b")
try:
print(f"pdf总页数: {translator.get_page_count()}")
# 翻译pdf并保持版面(只翻译前3页作为示例)
translator.create_translated_pdf(
output_path=output_pdf,
dest_lang='zh',
start_page=8,
end_page=211 # 翻译前3页(0-2)
)
finally:
# 关闭文档
translator.close()
if __name__ == "__main__":
main()
运行结果

到此这篇关于python结合pymupdf手把手实现pdf原版式翻译的实战指南的文章就介绍到这了,更多相关python pymupdf翻译pdf内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论