一、前言
为什么要学习pandas?我们之前其实已经接触了xlwings,它的强项是控制 excel。比如打开文件、读写单元格、设置字体颜色、操作图表。它不擅长计算,但是如果用 xlwings 逐行遍历 10 万行数据做加法,速度会比蜗牛还慢,同样如果用vba处理,庞大的数据处理需求,就有点难为二位了
因此 pandas 是“超级加工厂”:它的强项是计算和处理数据。它把数据加载到内存(ram)里,处理 100 万行数据的筛选、求和、匹配,通常只需要 0.x 秒,下面我们主要了解一下它的基础使用用法。
如果需要使用这个包,我们一样使用pip命令进行安装,然后通过import pandas as pd 进行引入,就可以使用了:
pip install pandas
二、理解series和dataframe
2.1 创建series
series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
sr = pd.series(["a",4,6,"今天",8]) print(sr) print(sr.index) # 显示索引 rangeindex(start=0, stop=5, step=1)
注意这里我们没有给sr一个index,因此默认是用数字来表示的,index是pandas的标识符,用于标识每一行的位置,输出的sr结果如下,series 可以代表包含不同的数据类型:
0 a
1 4
2 6
3 今天
4 8
dtype: object
那如果我们给定index,得到的结果就是:
sr = pd.series(["a",4,6,"今天",8],index=["a","b","c","d","e"]) print(sr) print(sr.index) # 显示索引 index(['a', 'b', 'c', 'd', 'e'], dtype='object')
运行结果:
a a
b 4
c 6
d 今天
e 8
dtype: object
我们也可以通过字典的方式生成,如下:
sort_dictionary = {"a":"a","b":4,"c":6,"d":"今天","e":8}
sr = pd.series(sort_dictionary)
print(sr) # 字典的键作为索引,值作为具体的第二列的值
2.2 读取series
series的读取类似字典的读取方式,如下如果取的是一个值,那么返回的就是一个值的具体类型,比如只通过sr["a"]取值,那么返回的类型是<class 'str'>,而如果取得是多个,则返回的类型还是series。
sort_dictionary = {"a":"a","b":4,"c":6,"d":"今天","e":8}
sr = pd.series(sort_dictionary)
print(sr["a"]) # 显示索引为a的值
print(type(sr["a"])) # 显示索引为a的值的类型
print("=========") # 分隔线
print(sr[["a","b","c"]]) # 显示索引为a,b,c的值
print(type(sr[["a","b","c"]])) # 显示索引为a,b,c的值的类型
输出为:
a
<class 'str'>
=========
a a
b 4
c 6
dtype: object
<class 'pandas.core.series.series'>
2.3 创建dataframe
我们上面提到的series只是一个一维的,但是dataframe就将其带入到了二维的场景:
df = pd.dataframe({
"a": [1, 2, 3],
"b": [4, 5, 6],
"c": [7, 8, 9]
},index=["a","b","c"])
print(df)
输出为:
a b c
a 1 4 7
b 2 5 8
c 3 6 9
其实你可以发现内部就是一个字典,然后我们通过index指定了索引,如果说没有给具体的索引,那么第一列就是0,1,2,我们也可以通过以下命令打印此dataframe的具体信息:
print(df.dtypes) # 显示数据类型 print(df.index) # index(['a', 'b', 'c'], dtype='object') print(df.columns) # index(['a', 'b', 'c'], dtype='object')
2.4 读取dataframe
(1)按列读出
我们通过下面的命令读取上面创建的dataframe:
print(df["a"]) # 显示列a
print(type(df["a"])) # 显示列a的类型
print("========") # 分隔线
print(df[["a","b"]]) # 显示列a,b
print(type(df[["a","b"]])) # 显示列a,b的类型
可以看到在控制台输出,可以看出是一列一列取的,如果只是看一列,那类型为series,如果是两列,就是dataframe:
a 1
b 2
c 3
name: a, dtype: int64
<class 'pandas.core.series.series'>
========
a b
a 1 4
b 2 5
c 3 6
<class 'pandas.core.frame.dataframe'>
(2)按行读出
那如果需要按行读出呢,我们可以使用loc方法,如下:
print(df.loc["a"]) print(type(df.loc["a"]))
得到的输出结果如下,可以发现取出的是一维数组,因此类型还是series:
a 1
b 4
c 7
name: a, dtype: int64
<class 'pandas.core.series.series'>
而如果我们同时需要取两行的话,就可以通过列表切片的方式进行索引
print(df.loc["a":"b"]) print(type(df.loc["a":"b"]))
输出结果如下,可以发现取出的是2行多列,因此是二维数组,数据类型就变成dataframe了:
a b c
a 1 4 7
b 2 5 8
<class 'pandas.core.frame.dataframe'>
(3)单个数据或区域读出
同时我们也可以实现单个单元格的获取和指定区域的获取:
print(df.loc["a","a"]) # 显示索引为a,列名为a的值
print("="*20) # 分割线
print(df.loc["a":"b","a"]) # 显示索引为a到b,列名为a的值
输出如下:
1
====================
a 1
b 2
name: a, dtype: int64
三、联动excel进行数据读取
3.1 加载excel文件
比如我们有一个data.xlsx 文件,我们首先简单进行读取:
import pandas as pd file_path = r"c:\users\22330\desktop\进行中\data.xlsx" df = pd.read_excel(file_path) # 读取对应的文件 print(df) print(df.index) print(df.index.is_unique) # true
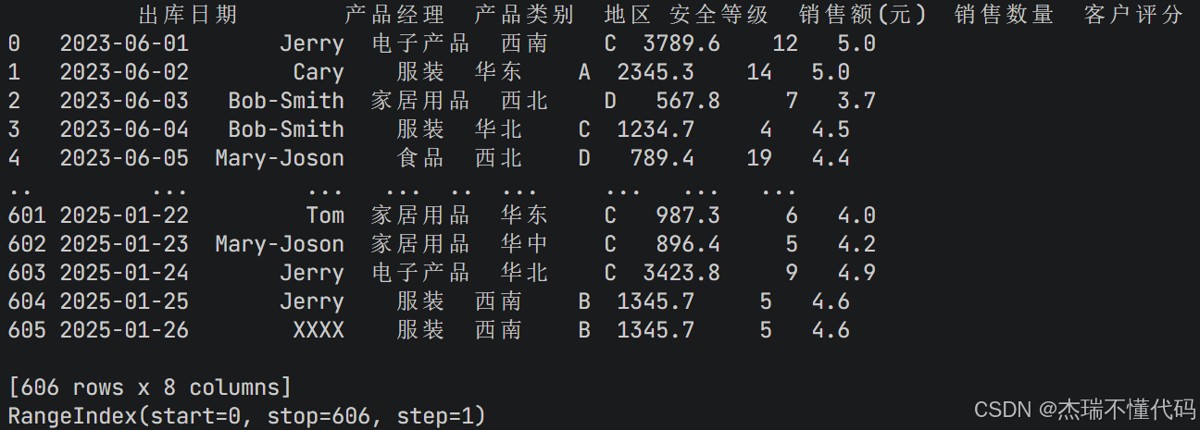
可以看到,打印出了开始5行和最后的五行,最左侧的一列数字是pandas的标识符,用于标识每一行的位置,在df输出的最后,也告知了数据源的形状,是606行*8列。当然如果看的是csv文件,可以把read_excel()改成read_csv()。
有的时候我们只想看数据的前几行数据,就可以使用(只会显示前5行数据)
print(df.head()) # 显示前五行数据
如果我们想要看此表的详细信息,可以通过df.info()得到
print(df.info()) # 显示数据框的信息,包括列名、非空值数量、数据类型等
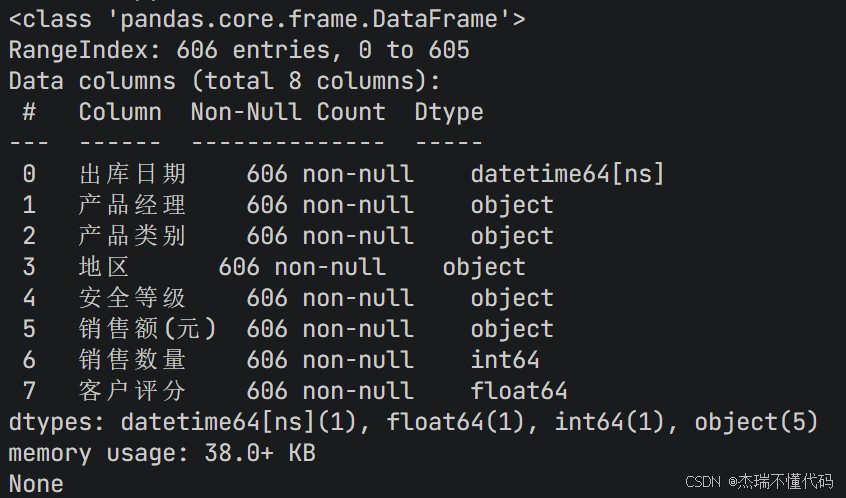
可以看到在上面的图中打印出来了data.xlsx中每一列的具体信息,是否有空值,数据类型,文件大小等。
如果单纯只是想要看一下数据区域的大小,或者列名,或者数据类型,可以尝试以下命令:
print(df.shape) # 显示数据行数和列数 print(df.columns) # 显示列名 print(df.dtypes) # 显示数据类型
3.2 使用pandas进行数据读取
可以看到我们的第一列是出库日期,我们可以用出库日期来作为索引,因此可以使用以下方法,将出库日期作为索引列,这样方便我们后期的查询,其中inplace=true表示将"出库日期"列设置为 dataframe 的索引,并且 直接修改原始的 df ,而不是返回一个新的:
df.set_index("出库日期",inplace=true)
print(df.head())
我们打印一下开始的几行,可以看到索引已经变成出库日期了:

现在比如我们想要知道 2023-06-03 出库的货物的 安全等级,就可以这样写:
print(df.loc["2023-06-03","安全等级"]) # d
或者可以进行多个数据的查询:
print(df.loc["2023-06-03",["安全等级","产品类别"]])
print("="*60) # 分割线
print(df.loc["2023-06-03":"2023-06-05",["安全等级","产品类别"]])
输出结果为:
安全等级 d
产品类别 家居用品
name: 2023-06-03 00:00:00, dtype: object
============================================================
安全等级 产品类别
出库日期
2023-06-03 d 家居用品
2023-06-04 c 服装
2023-06-05 d 食品
或者我们的行和列都可以变成数据区间,例如:
print(df.loc["2023-06-03":"2023-06-05","产品经理":"地区"])
输出:
产品经理 产品类别 地区
出库日期
2023-06-03 bob-smith 家居用品 西北
2023-06-04 bob-smith 服装 华北
2023-06-05 mary-joson 食品 西北
3.3 使用pandas进行条件查询
比如我们想要查询产品经理为jerry的所有记录,就可以这样写,下方的 : 代表返回所有列:
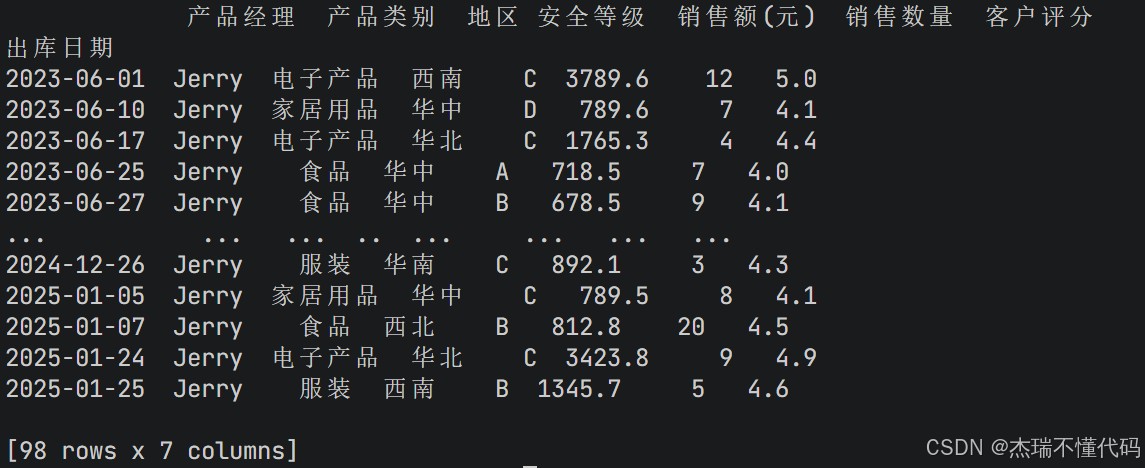
print(df.loc[df["产品经理"]=="jerry",:])
于是可以看到,输出中返回了筛选之后的结果,注意这里的98行只包括数据源(不包括标题行),因此共98条符合的记录:
也可以把条件写的复杂一些,然后进行多条件的筛选,也可以返回指定的列,如下方的写法:
# 显示产品经理为jerry且安全等级为d的所有数据 print(df.loc[(df["产品经理"]=="jerry")&(df["安全等级"]=="d"),:]) # 显示产品经理为jerry且安全等级为d的销售额和地区 print(df.loc[(df["产品经理"]=="jerry")&(df["安全等级"]=="d"),["销售额(元)","地区"]])
以上就是使用pandas操作excel表格的详细入门教程的详细内容,更多关于pandas操作excel表格的资料请关注代码网其它相关文章!






发表评论