python-docx是一个可以操作word文档的python开源库,简单易用,适合用来自动化办公。
一、安装 python-docx 库
可以使用pip命令安装python-docx 库。在 windows 命令行窗口执行如下命令:
pip install python-docx c:\users\wgx58>pip install python-docx collecting python-docx using cached python_docx-1.2.0-py3-none-any.whl.metadata (2.0 kb) requirement already satisfied: lxml>=3.1.0 in c:\python\lib\site-packages (from python-docx) (6.0.2) requirement already satisfied: typing_extensions>=4.9.0 in c:\python\lib\site-packages (from python-docx) (4.15.0) using cached python_docx-1.2.0-py3-none-any.whl (252 kb) installing collected packages: python-docx successfully installed python-docx-1.2.0
二、新建与打开word文档
在python-docx中,一个word文档用一个document对象来表示,所以我们要新建一个word文档,只需要实例化一个document对象即可。
程序代码如下:
from docx import document
doc = document()
doc.save('d:/0工作文档/word文档/mydoc.docx')
要打开一个已存在的word文档,只需要在实例化的时候传入该文档的路径即可。
程序代码如下:
from docx import document
doc = document('d:/0工作文档/word文档/mydoc.docx')
doc.save('d:/0工作文档/word文档/mydoc1.docx')
三、保存word文档
要保存word文档可以调用document对象的save()方法,传入要保存的路径即可。
说明:如果该路径已存在同名文件,会直接被覆盖掉,并不会给出任何提示。
程序代码如下:
from docx import document
doc = document('d:/0工作文档/word文档/mydoc.docx')
doc.save('d:/0工作文档/word文档/mydoc1.docx')
四、在word文档中插入各种内容
相关概念
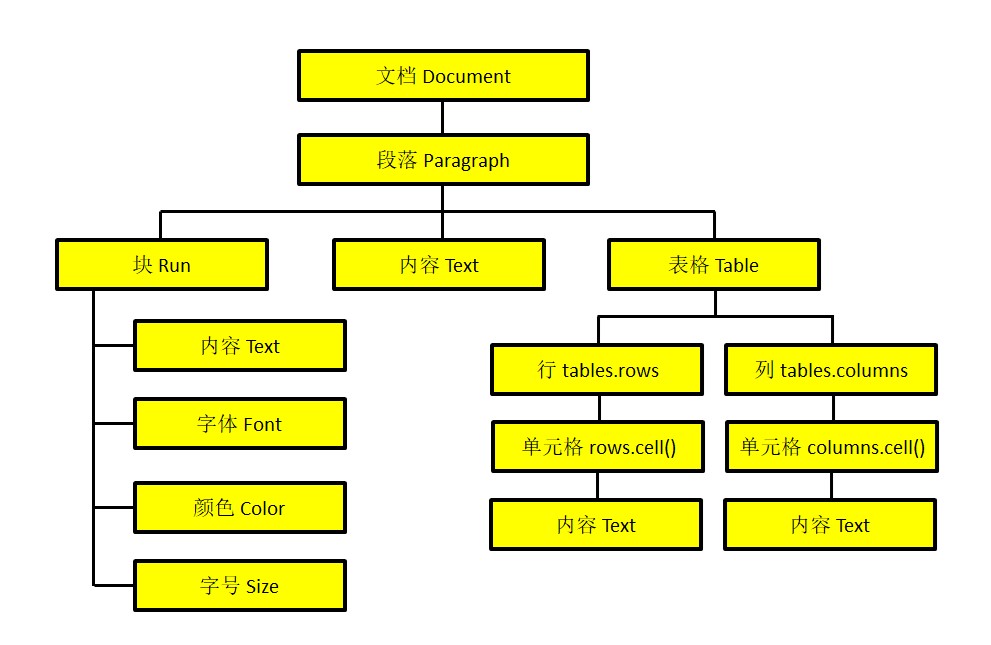
1、document对象
document对象表示整个文档。
2、paragraph对象
每一个段落代表一个paragraph对象。
3、run对象
一个run对象指的是paragraph对象中相同样式的连续文字。
4、table对象
table对象指的是一个单独的表格。一个表包含行(row)、列(column)和单元格(cell)。
以上各类对象之间的关系如下图所示:
添加标题
本节用到的函数及属性如下表所示:
| 函数/属性 | 用法 |
|---|---|
| docx.document() | 创建word文档 |
| doc.add_heading(content,level) | 添加标题 |
| doc.save(path) | 保存word文档 |
例如:
from docx import document
def create_word():
doc1 = document() # 创建word文档
doc1.add_heading('欢迎使用python创建word',0) # 增加0级标题
doc1.add_heading('python操作 增加1级标题',1) # 增加1级标题
doc1.add_heading('python操作 增加2级标题',2) # 增加2级标题
doc1.save(r'd:\0工作文档\word文档\test.docx') # 保存文档
if __name__ == '__main__':
create_word()
程序的运行结果如下图所示:

插入段落
本节用到的函数及属性如下表所示:
| 函数/属性 | 用法 |
|---|---|
| doc.add.paragraph(content,style) | 添加段落 |
| paragraph.add_run(content) | 添加块 |
例如:
from docx import document
from docx.enum.style import wd_builtin_style
def create_word():
doc1 = document() # 创建一个word文档
doc1.add_paragraph('七律·长征','heading 1') # 增加段落信息,使用【标题1】样式
par1=doc1.add_paragraph('作者:毛泽东\n')
par1.add_run('红军不怕远征难,万水千山只等闲。\n')
par1.add_run('五岭逶迤腾细浪,乌蒙磅礴走泥丸。\n')
par1.add_run('金沙水拍云崖暖,大渡桥横铁索寒。\n')
par1.add_run('更喜岷山千里雪,三军过后尽开颜。\n')
doc1.add_paragraph('译文','heading 2')
doc1.add_paragraph('红军不怕万里长征路上的一切艰难困苦,把千山万水都看得极为平常。\n五岭山脉绵延不绝,可在红军眼里不过像翻腾着的细小波浪;乌蒙山高大雄伟,在红军眼里也不过像在脚下滚过的泥丸。\n金沙江浊浪滔天,湍急的流水拍击着高耸的山崖,溅起阵阵雾水,像是冒出蒸汽一样。大渡河险桥横架,晃动着凌空高悬的根根铁索,寒意阵阵。\n更加令人欣喜的是千里岷山,皑皑白雪,红军翻越过去以后人人心情开朗,个个笑逐颜开。')
# 增加无序列表
doc1.add_paragraph('新乡市的高校:')
doc1.add_paragraph('河南科技学院',style='list bullet')
doc1.add_paragraph('河南医药大学',style='list bullet')
doc1.add_paragraph('河南师范大学',style='list bullet')
doc1.add_paragraph('河南工学院',style='list bullet')
doc1.add_paragraph('新乡学院',style='list bullet')
# 增加有序列表
doc1.add_paragraph('新乡市的高校:')
doc1.add_paragraph('河南师范大学',style='list number')
doc1.add_paragraph('河南医药大学',style='list number')
doc1.add_paragraph('河南科技学院',style='list number')
doc1.add_paragraph('河南工学院',style='list number')
doc1.add_paragraph('新乡学院',style='list number')
# 保存word文档
doc1.save(r'd:\0工作文档\word文档\test.docx') # 保存文档
if __name__ =='__main__':
create_word()
程序的运行结果如下图所示:

插入块(run)
代码如下:
from docx import document
def create_word():
doc1 = document() # 创建一个word文档
doc1.add_paragraph('七律·长征', 'title') # 增加段落信息,使用【标题1】样式
par1 = doc1.add_paragraph('作者:毛泽东\n')
par1.add_run('红军不怕远征难,万水千山只等闲。\n')
par1.add_run('五岭逶迤腾细浪,乌蒙磅礴走泥丸。\n')
par1.add_run('金沙水拍云崖暖,大渡桥横铁索寒。\n')
par1.add_run('更喜岷山千里雪,三军过后尽开颜。')
par1.runs[0].bold = true
par1.runs[1].underline = true
par1.runs[2].italic = true
par1.runs[3].underline = true
par1.runs[4].italic = true
doc1.save(r'd:\0工作文档\word文档\test.docx') # 保存文档
if __name__ == '__main__':
create_word()
程序的运行结果如下图所示:

插入分页符
插入分页符使用add_page_break,代码如下:
from docx import document
from docx.enum.style import wd_builtin_style
def create_word():
doc1 = document() # 创建一个word文档
doc1.add_paragraph('七律·长征','title') # 增加段落信息,使用【标题1】样式
par1=doc1.add_paragraph('作者:毛泽东\n')
par1.add_run('红军不怕远征难,万水千山只等闲。\n')
par1.add_run('五岭逶迤腾细浪,乌蒙磅礴走泥丸。\n')
par1.add_run('金沙水拍云崖暖,大渡桥横铁索寒。\n')
par1.add_run('更喜岷山千里雪,三军过后尽开颜。\n')
doc1.add_paragraph('译文','titile')
doc1.add_paragraph('红军不怕万里长征路上的一切艰难困苦,把千山万水都看得极为平常。\n五岭山脉绵延不绝,可在红军眼里不过像翻腾着的细小波浪;乌蒙山高大雄伟,在红军眼里也不过像在脚下滚过的泥丸。\n金沙江浊浪滔天,湍急的流水拍击着高耸的山崖,溅起阵阵雾水,像是冒出蒸汽一样。大渡河险桥横架,晃动着凌空高悬的根根铁索,寒意阵阵。\n更加令人欣喜的是千里岷山,皑皑白雪,红军翻越过去以后人人心情开朗,个个笑逐颜开。')
doc1.add_page_break() # 在此处插入一个分页符
# 增加无序列表
doc1.add_paragraph('新乡市的高校:')
doc1.add_paragraph('河南科技学院',style='list bullet')
doc1.add_paragraph('河南医药大学',style='list bullet')
doc1.add_paragraph('河南师范大学',style='list bullet')
doc1.add_paragraph('河南工学院',style='list bullet')
doc1.add_paragraph('新乡学院',style='list bullet')
# 增加有序列表
doc1.add_paragraph('新乡市的高校:')
doc1.add_paragraph('河南师范大学',style='list bullet')
doc1.add_paragraph('河南医药大学',style='list bullet')
doc1.add_paragraph('河南科技学院',style='list bullet')
doc1.add_paragraph('河南工学院',style='list bullet')
doc1.add_paragraph('新乡学院',style='list bullet')
# 保存word文档
doc1.save(r'd:\0工作文档\word文档\test.docx') # 保存文档
if __name__ =='__main__':
create_word()
插入图片
本节用到的函数及属性如下表所示:
| 函数/属性 | 用法 |
|---|---|
| doc.add_picture(path,width,height) | 添加图片 |
| pic.width | 获取图片宽度 |
| pic.height | 获取图片高度 |
| doc.sections[0].page_width | 获取页面宽度 |
| doc.sections[0].left_margin | 获取页面高度 |
例如:
from docx import document
def create_word():
doc1 = document()
page_width = doc1.sections[0].page_width # 获取文档的宽度
page_left_width = doc1.sections[0].left_margin # 获取文档的左边距
print(page_width)
print(page_left_width)
content_width = page_width-page_left_width*2 # 获取中间内容的宽度
print(content_width)
doc1.add_heading("插入图片如下",level=0)
# 增加图片,设置图片的宽度占文档宽度的一半
pic = doc1.add_picture(r'd:\0工作文档\typora文档\word\pic01.jpg',int(content_width*0.5))
doc1.save(r'd:\0工作文档\typora文档\word\pic.docx') # 保存文档
if __name__ == '__main__':
create_word()
插入表格
本节用到的函数及属性如下表所示:
| 函数/属性 | 用法 |
|---|---|
| doc.add_table(rows=x,cols=x) | 添加表格 |
| table.add_row() | 添加行 |
例如:
from docx import document
def create_table():
doc1 = document() # 创建word文档
t1 = doc1.add_table(1,4) # 添加一个1行4列的表格
# 设置表格的内容
t1.rows[0].cells[0].text = '学号'
t1.rows[0].cells[1].text = '姓名'
t1.rows[0].cells[2].text = '性别'
t1.rows[0].cells[3].text = '班级'
data = (
(1,'刘备','男','物流231班'),
(2,'孙权','女','物流231班'),
(3,'曹操','男','物流232班')
)
for s_id,s_name,s_gender,s_class in data:
row = t1.add_row() # 增加一行数据
row.cells[0].text = str(s_id) # 注意:要把数值型转换为文本类型
row.cells[1].text = s_name
row.cells[2].text = s_gender
row.cells[3].text = s_class
doc1.save(r'd:\0工作文档\typora文档\word\table.docx') # 保存文档
if __name__ =='__main__':
create_table()
程序的运行结果如下图所示:

五、读取word文档的内容
如果需要读取word文档的内容,可以通过相关的变量读取段落、块、表格、行、单元格等信息。
读取段落信息
使用doc.paragraphs属性返回所有段落的列表。使用paragraph.text获取段落的内容。
程序代码如下:
from docx import document doc1 = document(r"d:\0工作文档\typora文档\word\test.docx") # 创建word文档 print(len(doc1.paragraphs)) print(doc1.paragraphs[0].text) print(doc1.paragraphs[1].text) 程序的运行结果为: 379 一、绪论 (一)课题背景
读取块信息
使用paragraph.runs属性返回段落中所有块的列表。使用run.text获取块的内容。
程序代码如下:
from docx import document
doc1 = document(r"d:\0工作文档\typora文档\word\test.docx") # 创建word文档
p=doc1.paragraphs[2]
print(p.text)
runs=p.runs
print(len(runs))
for run in runs:
print(run.text)
读取表格信息
使用doc.tables属性返回文档中所有表格的列表。使用run.text获取块的内容。
程序代码如下:
from docx import document
doc1 = document(r"d:\0工作文档\typora文档\word\test.docx") # 创建word文档
t=doc1.tables
print("表格数量:",len(t)) # 返回文档中表格的数量
t1=t[0] # 返回第一个表格
print("第一个表格的行数:",len(t1.rows)) # 返回第一个表格的行数
print("=="*20)
print("==============按行显示表格内容:=================")
print("=="*20)
for row in t1.rows:
for cell in row.cells:
print(cell.text, end=' ')
print("")
print("第一个表格的列数:",len(t1.columns)) # 返回第一个表格的列数
print("=="*20)
print("==============按行列显示表格内容:=================")
print("=="*20)
for column in t1.columns:
for cell in column.cells:
print(cell.text, end=' ')
print("") 使用模板生成文档
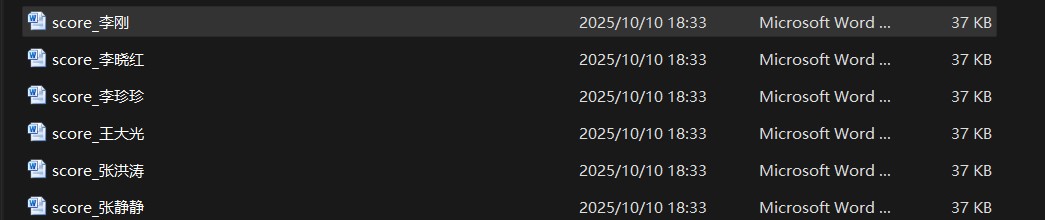
例如:需要生成如下图所示的学生成绩通知单(每个学生生成一份)。

程序代码如下:
from docx import document
def create_score(d):
doc1 = document() # 创建word文档
doc1.add_heading(f'{d[1]}成绩通知单',0) # 添加标题
t=doc1.add_table(1,6) # 添加表格,1行6列
row=t.rows[0] # 设置表格第一行每个单元格内容
row.cells[0].text = "学号"
row.cells[1].text = "姓名"
row.cells[2].text = "语文"
row.cells[3].text = "数学"
row.cells[4].text = "英语"
row.cells[5].text = "班级"
row=t.add_row() # 添加一行,并设置每个单元格内容
row.cells[0].text = d[0]
row.cells[1].text = d[1]
row.cells[2].text = str(d[2])
row.cells[3].text = str(d[3])
row.cells[4].text = str(d[4])
row.cells[5].text = d[5]
doc1.save(f"d:/0工作文档/typora文档/word/score_{d[1]}.docx") # 保存为单个文件
if __name__ == '__main__':
data = [
('100001', '李刚', 80, 98, 85, '八年级二班'),
('100002', '张洪涛', 95, 66, 92, '八年级二班'),
('100003', '张静静', 77, 78, 94, '八年级二班'),
('100004', '李晓红', 68, 84, 74, '八年级二班'),
('100005', '王大光', 91, 97, 93, '八年级二班'),
('100006', '李珍珍', 87, 78, 79, '八年级二班')
]
for d in data:
create_score(d)
程序的执行结果如下图所示:
到此这篇关于python使用python-docx库操作word(创建、读取和插入)文档的完整指南的文章就介绍到这了,更多相关python python-docx操作word内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论