将mysql中的数据通过canal同步到redis,是一种比较常见的数据库与缓存间增量数据同步的方案,核心思路是利用canal解析mysql的binlog,捕获数据变更,然后更新到redis。这样做的好处是对业务代码侵入小,能较好地保证数据一致性。
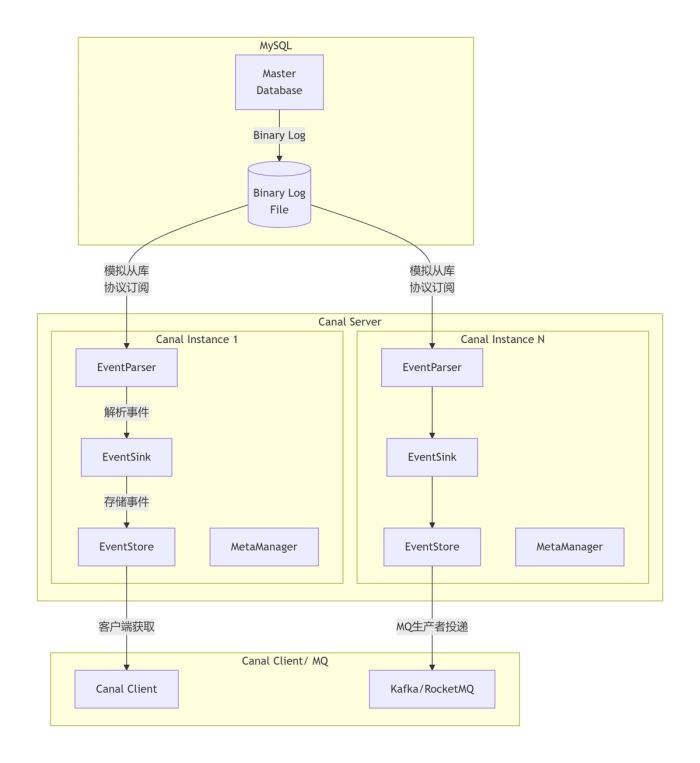
核心工作原理
canal工作的核心是伪装成mysql的从库(slave)。
- 模拟从库交互:canal启动后,会模拟mysql从库的行为,向mysql主库(master)发送一个
dump请求。 - 主库推送binlog:mysql主库接收到
dump请求后,会将自己的二进制日志(binary log)推送给canal。 - 解析与转发:canal接收到原始的二进制日志流后,会对其进行解析,转换成易于处理的对象,然后传递给下游模块进行存储和消费。
这个过程使得canal能够实时捕获数据库的变更(如insert、update、delete),从而实现数据的增量订阅与消费。
为了让你能快速把握核心流程,这里用一个表格来汇总主要步骤和关键点:
| 步骤 | 关键动作 | 说明/注意事项 |
|---|---|---|
| 1. 环境准备 | 开启mysql binlog | 必须设置为row模式,并配置server_id。 |
| 创建canal数据库用户 | 授予select, replication slave, replication client权限。 | |
| 准备redis | 确保canal服务器可访问redis。 | |
| 2. 安装配置canal | 部署canal server | 可从官方github仓库下载发布版。 |
修改canal.properties | 配置canal服务模式,例如指定使用tcp模式或者与rabbitmq、kafka等消息队列集成。 | |
修改instance.properties | 配置数据库连接信息(地址、用户名、密码等)和binlog订阅规则。 | |
| 3. 开发数据处理逻辑 | 接收并解析binlog | 使用canal客户端或通过消息队列消费者(如监听kafka)获取数据变更。 |
| 设计redis数据格式 | 决定数据在redis中的存储格式(如string、hash等)。 | |
| 写入redis | 根据解析出的数据操作类型(增、删、改),执行相应的redis写入或删除命令。 | |
| 4. 启动与验证 | 启动canel及客户端 | 先启动canal server,再启动你的客户端程序。 |
| 测试数据变更 | 在mysql中执行增、删、改操作,观察redis中数据是否按预期变化。 |
🔧 操作细节与要点
1. 环境准备:配置mysql
- [mysqld] log-bin=mysql-bin # 开启binlog binlog-format=row # 选择row模式[citation:4] server_id=1 # 配置一个唯一的server_id
- 创建canal用户并授权:在mysql中执行以下命令:
create user 'canal'@'%' identified by 'your_password'; grant select, replication slave, replication client on *.* to 'canal'@'%'; flush privileges;
2. canal安装与配置
下载与解压:从canal的github release页面下载所需版本的安装包,然后解压到目标目录。
canal服务端口 canal.port = 11111 # 服务模式,如tcp, kafka, rocketmq等[citation:6] canal.servermode = tcp # 目的地集合,对应instance配置的文件夹名 canal.destinations = example
主库地址 canal.instance.master.address = 127.0.0.1:3306 # 数据库用户名 canal.instance.dbusername = canal # 数据库密码 canal.instance.dbpassword = your_canal_password # 要监听的表,支持正则表达式 canal.instance.filter.regex = .*\\..*
3. 开发数据处理逻辑
canal客户端示例(java伪代码)展示了如何处理binlog并操作redis:
// canal客户端监听binlog(伪代码)
canalconnector connector = canalconnectors.newclusterconnector("127.0.0.1:2181", "example", "", "");
connector.connect();
connector.subscribe(".*\\..*");
while (true) {
message message = connector.getwithoutack(100);
for (canalentry.entry entry : message.getentries()) {
if (entry.getentrytype() == canalentry.entrytype.rowdata) {
canalentry.rowchange rowchange = canalentry.rowchange.parsefrom(entry.getstorevalue());
for (canalentry.rowdata rowdata : rowchange.getrowdataslist()) {
string tablename = entry.getheader().gettablename();
// 根据表名和主键构造redis key,这里假设第一列为主键
string key = "cache:" + tablename + ":" + rowdata.getbeforecolumns(0).getvalue();
if (rowchange.geteventtype() == canalentry.eventtype.delete) {
redis.del(key); // 删除缓存[citation:6]
} else {
// 更新缓存:这里可以将rowdata的aftercolumns序列化后存储
redis.set(key, serialize(rowdata.getaftercolumnslist())); // 更新缓存[citation:6]
}
}
}
}
}4. 启动与验证
d /your/target/directory/bin sh startup.sh
- 验证:
- 检查canal服务日志
logs/canal/canal.log,查看服务是否正常启动。 - 检查实例日志
logs/example/example.log,查看实例运行状态和是否有数据同步。 - 在mysql中执行insert、update、delete操作,观察redis中对应的key是否按预期变化。
- 检查canal服务日志
⚠️ 常见问题与技巧
- 数据格式设计:同步到redis时,需合理设计key和value。key通常包含表名和主键-6。value可使用string存储json序列化后的整行数据,或用hash存储字段和值的映射。
- 幂等性处理:在网络不稳定或客户端重启的情况下,可能会收到重复的binlog消息。确保数据同步逻辑具有幂等性。
- 处理ddl语句:canal可以解析ddl(如alter table)。如果表结构变更影响redis中的数据格式,客户端需能处理或触发缓存重建。
- 性能考量:直接通过canal tcp客户端同步,在高并发下可能成为瓶颈。此时可引入消息队列(如kafka、rocketmq) 解耦-6,canal将变更事件发送到mq,由消费者异步处理并更新redis。
- 使用现成平台:除了自建canal集群,也可考虑使用cloudcanal这类数据平台,它提供了图形化界面,简化了mysql到redis同步链路的创建和管理-1。
💎 总结
利用canal同步mysql数据到redis,关键在于正确配置mysql的binlog,合理部署和配置canal,并编写可靠的数据处理和redis写入逻辑。引入消息队列可以提升整体的可靠性和扩展性。同时,务必注意数据格式的设计和幂等性处理。
到此这篇关于mysql数据实时同步redis的方案全解析的文章就介绍到这了,更多相关mysql redis同步内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论