在日常的数据处理中,我们经常会遇到多级表头的 excel 文件:例如“商品1 / 库存 / 销量”这种两行结构。 如果不正确处理表头,python 在读取时就会出现列名混乱、keyerror 等问题。
本文通过一个实际案例,带你完整走一遍:读取 excel → 整理多级表头 → 提取库存→销量的数据 → 绘图可视化。
一、示例 excel 数据结构
数据格式如下(前两行为表头):
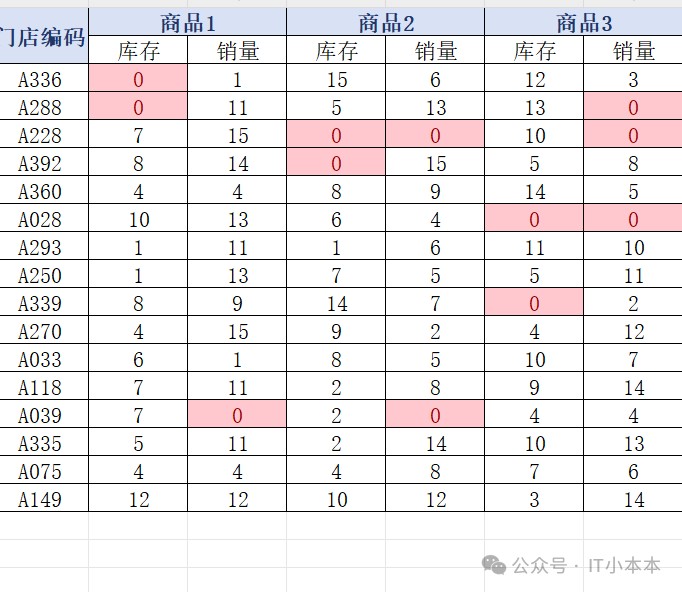
这种结构是典型的 multiindex 多级表头。
若直接读取,会导致列名变成:
('商品1', '库存'), ('商品1', '销量')
我们需要把它整理成更易操作的形式,例如:
商品1-库存
商品1-销量
商品2-库存
商品2-销量
二、python 读取多级表头(关键步骤)
使用 header=[0,1] 阅读两行表头:
df = pd.read_excel("data.xlsx", header=[0, 1])
随后整合成单行列名:
new_cols = []
for col1, col2 in df.columns:
if col1 == '门店编码':
new_cols.append('门店编码')
else:
new_cols.append(f"{col1}-{col2}")
df.columns = new_cols
这样就能避免 keyerror,并让所有列名清晰易用。
三、提取库存 > 销量的所有门店商品
逻辑很简单:
如果 库存 > 销量 :输出该商品
完整代码如下:
result = []
for index, row in df.iterrows():
store = row['门店编码']
for i in range(1, 6):
inv = row[f"商品{i}-库存"]
sales = row[f"商品{i}-销量"]
if inv > sales:
result.append([store, f"商品{i}", inv])
result_df = pd.dataframe(result, columns=['门店', '商品', '库存'])
print(result_df)
输出示例:
门店 商品 库存
a039 商品1 7
a039 商品2 2
a288 商品3 13
a335 商品4 6
这样我们就得到了所有“库存高于销量”的商品清单。
四、库存分析可视化(3 个图表)
下面使用 matplotlib + seaborn 来生成直观清晰的图表。
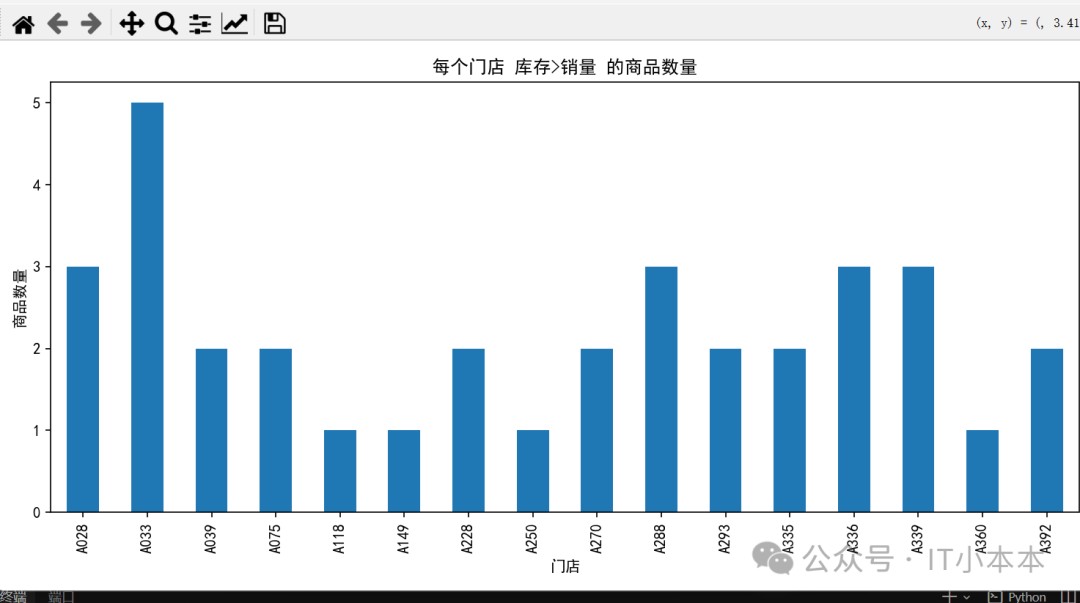
图表 1:每个门店库存>销量的商品数量(条形图)
import matplotlib.pyplot as plt
store_count = result_df.groupby("门店").size()
plt.figure(figsize=(10,5))
store_count.plot(kind='bar')
plt.title("每个门店 库存>销量 的商品数量")
plt.xlabel("门店")
plt.ylabel("商品数量")
plt.tight_layout()
plt.show()
可帮助判断:哪些门店库存积压最大。
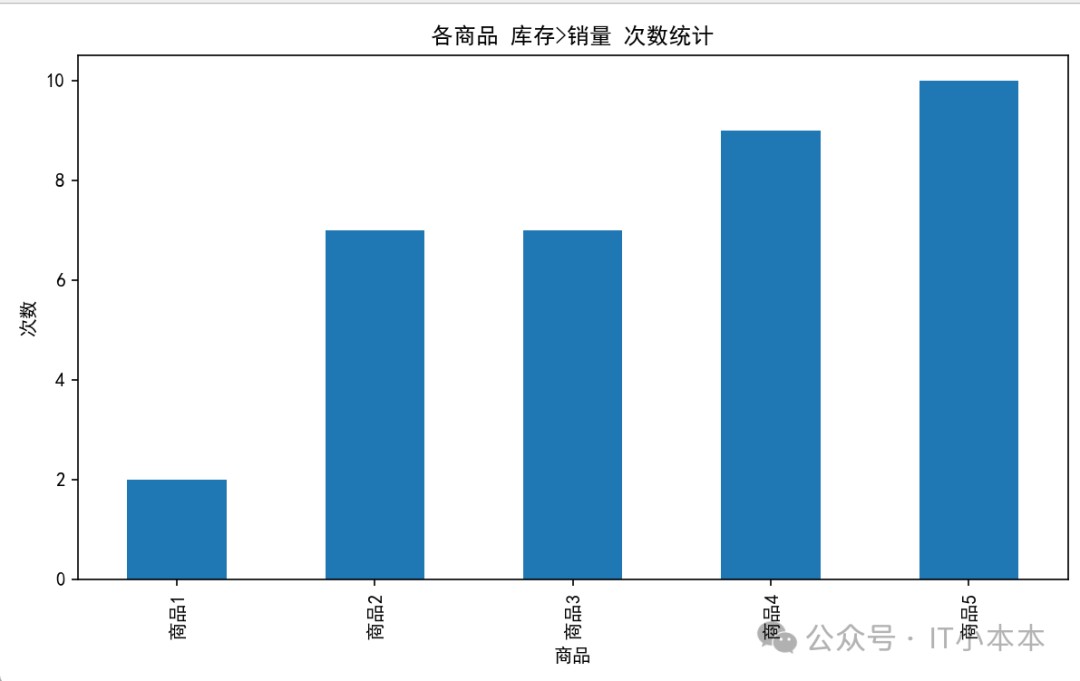
图表 2:每个商品库存>销量出现次数(条形图)
product_count = result_df.groupby("商品").size()
plt.figure(figsize=(8,5))
product_count.plot(kind='bar')
plt.title("各商品 库存>销量 次数统计")
plt.xlabel("商品")
plt.ylabel("次数")
plt.tight_layout()
plt.show()
用于发现:哪些商品容易滞销。
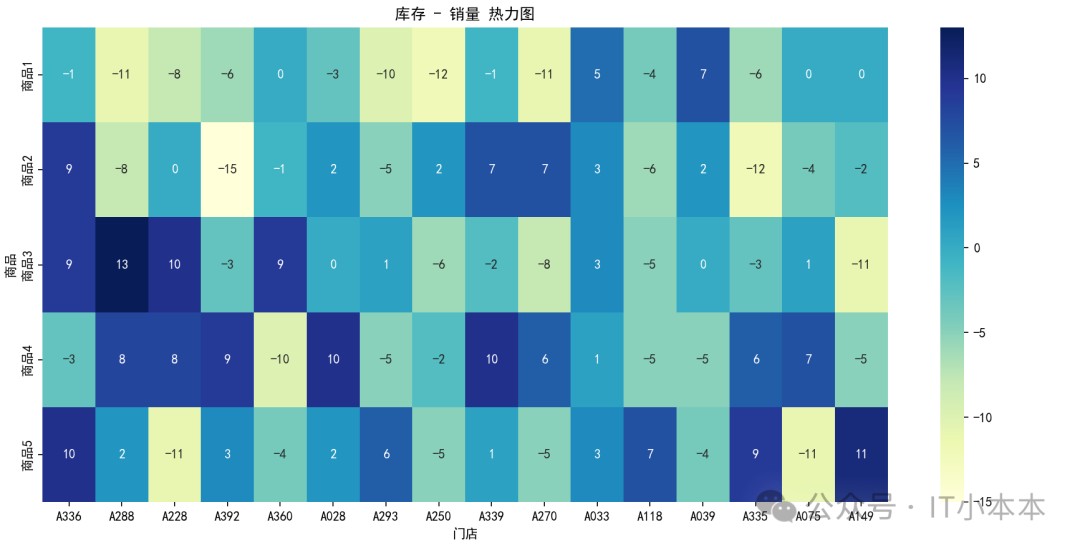
图表 3:库存 - 销量 热力图(直观查看差异)
import seaborn as sns
matrix = {}
for index, row in df.iterrows():
store = row['门店编码']
diff_list = []
for i in range(1, 6):
diff = row[f"商品{i}-库存"] - row[f"商品{i}-销量"]
diff_list.append(diff)
matrix[store] = diff_list
heat_df = pd.dataframe(matrix, index=[f"商品{i}" for i in range(1, 6)])
plt.figure(figsize=(12,6))
sns.heatmap(heat_df, annot=true, fmt="d", cmap="ylgnbu")
plt.title("库存 - 销量 热力图")
plt.xlabel("门店")
plt.ylabel("商品")
plt.tight_layout()
plt.show()
热力图能够一眼看到:
- 哪些门店库存偏高
- 哪些商品表现更好或更差
是库存分析中非常有价值的图。
到此这篇关于python实现轻松处理两行表头excel并可视化分析(附完整代码)的文章就介绍到这了,更多相关python处理两行表头excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论