一、概述
docx2markdown是基于python开发的文档格式双向转换工具,支持microsoft word(.docx)与markdown(.md)格式的相互转换。该工具专注于保留基础文档结构,适用于技术文档、简单报告等格式转换场景。docx2markdown是pypandoc的一个替代方案。
二、技术原理
1. 架构设计

2. 核心组件
python-docx: 处理word文档的读写操作
markdown: 解析和生成markdown语法
lxml: xml处理引擎
pil: 图像格式处理(可选)
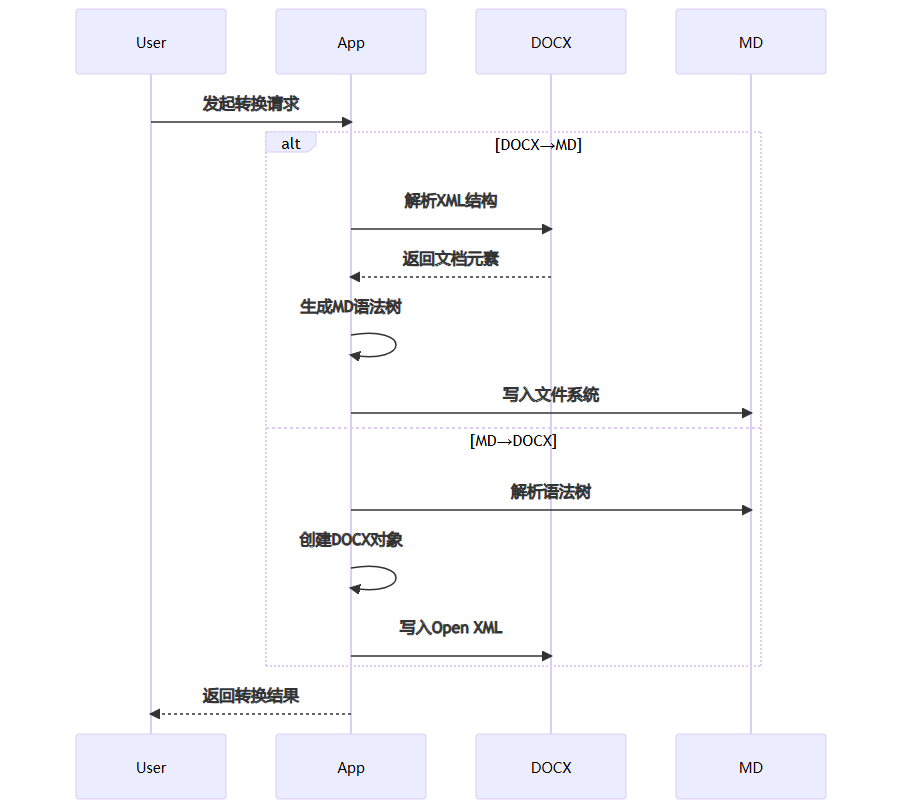
3. 转换逻辑
docx → markdown
1. 解析.docx文件的xml结构
2. 提取段落、样式、列表、表格等元素
3. 转换为对应的markdown语法元素
4. 处理内嵌图片(转换为base64或文件存储)
markdown → docx
1. 解析markdown语法树
2. 创建word文档对象
3. 应用样式映射(标题→heading样式等)
4. 生成标准.docx文件结构
三、功能特性
| 功能 | 支持程度 | 备注 |
|---|---|---|
| 段落文本 | ✔️ | 保留基本段落结构 |
| 标题样式 | ✔️ | 支持h1-h6 |
| 无序列表 | ✔️ | 支持嵌套列表 |
| 有序列表 | ✔️ | 数字序列自动生成 |
| 表格 | ✔️ | 基础表格结构 |
| 超链接 | ✔️ | 保留链接文本和url |
| 图片嵌入 | ✔️ | 需配置存储路径 |
| 代码块 | ✔️ | 支持```语法 |
| 粗体/斜体 | ✔️ | bold和italic |
| 混合格式 | ⚠️ | 部分复杂样式可能丢失 |
四、安装方法
# 基础安装 pip install docx2markdown # 包含测试依赖 pip install docx2markdown[testing]
使用uv:
# 基础安装 uv add docx2markdown # 包含测试依赖 uv add docx2markdown[testing]
五、使用示例
1. python api
import docx2markdown
from pathlib import path
def convert_docx_to_md(input_path, output_path):
"""word转markdown示例"""
try:
if not path(input_path).exists():
raise filenotfounderror(f"输入文件不存在: {input_path}")
docx2markdown.docx_to_markdown(
input_path,
output_path
)
print(f"转换成功: {output_path}")
except exception as e:
print(f"转换失败: {str(e)}")
def convert_md_to_docx(input_path, output_path):
"""markdown转word示例"""
try:
docx2markdown.markdown_to_docx(
input_path,
output_path
)
print(f"转换成功: {output_path}")
except exception as e:
print(f"转换失败: {str(e)}")
# 使用示例
convert_docx_to_md("./data/docx2markdown技术说明文档.docx", "./data/docx2markdown技术说明文档.md")
convert_md_to_docx("readme.md", "documentation.docx")
2. 命令行工具
# docx转markdown docx2markdown input.docx output.md # markdown转docx docx2markdown input.md output.docx
六、注意事项
1. 复杂格式限制
- 不支持word文档中的分栏布局
- 表格合并单元格可能转换异常
- 数学公式需要特殊处理
2. 性能建议
- 单个文档建议不超过50页
- 图片数量超过20张时建议启用独立存储目录
3. 兼容性说明
- 基于office open xml标准
- 推荐使用microsoft word 2016+验证结果
附:典型转换流程
到此这篇关于python使用docx2markdown转换docx和markdown文件的文章就介绍到这了,更多相关python docx2markdown使用内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论