一、准备数据
-- 创建数据库
create database if not exists test001;
-- 切换数据库
use test001;
-- 删除数据表
drop table if exists student_course;
drop table if exists student;
drop table if exists course;
-- 1. 学生表(主表)
create table if not exists `student` (
student_id int not null auto_increment comment '学生id(主键)',
student_no varchar(20) not null comment '学号(唯一标识,如2024001)',
student_name varchar(50) not null comment '学生姓名',
gender char(1) not null comment '性别(男/女)',
birth_date date null comment '出生日期',
major varchar(50) not null comment '所属专业',
enroll_date date not null comment '入学时间',
create_time datetime not null default current_timestamp comment '记录创建时间',
-- 列级约束
primary key (student_id),
unique key uk_student_no (student_no), -- 学号唯一
check (gender in ('男', '女')) -- 限制性别只能是男或女
)
engine = innodb
default charset = utf8mb4
collate = utf8mb4_general_ci
auto_increment = 1001 -- 学生id从1001开始
comment = '学生信息表';
-- 2. 课程表(主表)
create table if not exists `course` (
course_id int not null auto_increment comment '课程id(主键)',
course_no varchar(20) not null comment '课程编号(如cs101)',
course_name varchar(100) not null comment '课程名称',
credit tinyint not null comment '学分(1-6分)',
teacher_name varchar(50) not null comment '授课教师',
course_hours int not null comment '课时数',
create_time datetime not null default current_timestamp comment '记录创建时间',
-- 列级约束
primary key (course_id),
unique key uk_course_no (course_no), -- 课程编号唯一
check (credit between 1 and 6), -- 学分范围限制
check (course_hours > 0) -- 课时必须为正数
)
engine = innodb
default charset = utf8mb4
collate = utf8mb4_general_ci
auto_increment = 101 -- 课程id从101开始
comment = '课程信息表';
-- 3. 选课表(关系表,关联学生表和课程表)
create table if not exists `student_course` (
id int not null auto_increment comment '选课记录id(主键)',
student_id int not null comment '学生id(外键关联学生表)',
course_id int not null comment '课程id(外键关联课程表)',
select_time datetime not null default current_timestamp comment '选课时间',
score decimal(5,2) null comment '课程成绩(0-100分,null表示未考试)',
is_valid tinyint not null default 1 comment '是否有效(1-有效,0-已退课)',
-- 表级约束
primary key (id),
-- 联合唯一约束:同一学生不能重复选同一门课
unique key uk_stu_course (student_id, course_id),
-- 外键约束:关联学生表
constraint fk_sc_student foreign key (student_id)
references `student`(student_id)
on delete cascade -- 学生记录删除时,关联的选课记录自动删除
on update cascade, -- 学生id更新时,选课记录同步更新
-- 外键约束:关联课程表
constraint fk_sc_course foreign key (course_id)
references `course`(course_id)
on delete cascade -- 课程记录删除时,关联的选课记录自动删除
on update cascade,
-- 检查约束:成绩范围限制(0-100分)
constraint chk_score check (score is null or (score between 0 and 100)),
-- 检查约束:is_valid只能是0或1
constraint chk_is_valid check (is_valid in (0, 1))
)
engine = innodb
default charset = utf8mb4
collate = utf8mb4_general_ci
comment = '学生选课关系表';
-- 插入 500 条学生数据
delimiter $$
create procedure insertstudents()
begin
declare i int default 1;
declare gender char(1);
declare year_start date;
declare birth date;
declare major_name varchar(50);
-- 常见专业列表
set @majors = '计算机科学与技术,软件工程,电子信息工程,数学与应用数学,物理学,化学,生物技术,机械工程,自动化,通信工程,'
'土木工程,环境工程,经济学,金融学,会计学,法学,汉语言文学,英语,新闻传播学,临床医学,护理学';
while i <= 500 do
set gender = if(rand() > 0.5, '男', '女');
-- 随机入学年份:2020 - 2024
set year_start = makedate(2020 + floor(rand() * 5), 1 + floor(rand() * 365));
-- 出生日期:入学时 17~23 岁
set birth = date_sub(year_start, interval floor(17 + rand() * 7) year);
-- 随机选择专业
set major_name = elt(ceiling(rand() * 21),
'计算机科学与技术','软件工程','电子信息工程','数学与应用数学','物理学',
'化学','生物技术','机械工程','自动化','通信工程',
'土木工程','环境工程','经济学','金融学','会计学',
'法学','汉语言文学','英语','新闻传播学','临床医学','护理学'
);
insert into `student` (student_no, student_name, gender, birth_date, major, enroll_date)
values (
concat('20', lpad(floor(rand() * 90 + 24), 2, '0'), lpad(i, 3, '0')), -- 如 2024001
concat(
elt(ceiling(rand() * 10), '张','李','王','刘','陈','杨','黄','赵','周','吴'),
elt(ceiling(rand() * 10), '伟','芳','敏','静','勇','磊','洋','娟','强','军')
),
gender,
birth,
major_name,
year_start
);
set i = i + 1;
end while;
end$$
delimiter ;
-- 执行并清理
call insertstudents();
drop procedure if exists insertstudents;
-- 插入 500 条课程数据
delimiter $$
create procedure insertcourses()
begin
declare i int default 1;
declare course_name_prefix varchar(50);
declare teacher_name varchar(50);
set @prefixes = '高等数学,线性代数,概率统计,c语言程序设计,java编程,python数据分析,数据结构,算法设计,操作系统,'
'计算机网络,数据库原理,软件工程,电路分析,模拟电子技术,数字逻辑,信号与系统,电磁场与波,自动控制原理,'
'大学物理,大学化学,马克思主义基本原理,中国近代史纲要,英语读写,体育健康,艺术鉴赏,心理学导论,经济学基础';
while i <= 500 do
set course_name_prefix = elt(ceiling(rand() * 27),
'高等数学','线性代数','概率统计','c语言程序设计','java编程','python数据分析','数据结构','算法设计','操作系统','计算机网络',
'数据库原理','软件工程','电路分析','模拟电子技术','数字逻辑','信号与系统','电磁场与波','自动控制原理',
'大学物理','大学化学','马克思主义基本原理','中国近代史纲要','英语读写','体育健康','艺术鉴赏','心理学导论','经济学基础'
);
set teacher_name = concat(
elt(ceiling(rand() * 10), '张','李','王','刘','陈','杨','黄','赵','周','吴'),
'老师'
);
insert into `course` (course_no, course_name, credit, teacher_name, course_hours)
values (
concat('cs', lpad(i, 3, '0')), -- cs001, cs002...
concat(course_name_prefix, '(', ceiling(rand() * 10), '期)'),
ceiling(rand() * 6), -- 1~6 学分
teacher_name,
case ceiling(rand() * 5)
when 1 then 32
when 2 then 48
when 3 then 64
when 4 then 80
else 96
end
);
set i = i + 1;
end while;
end$$
delimiter ;
-- 执行并清理
call insertcourses();
drop procedure if exists insertcourses;
-- 插入 500 条不重复的选课记录
delimiter $$
create procedure insertstudentcourse()
begin
declare i int default 1;
declare sid int;
declare cid int;
declare retry_count int default 0;
declare max_retries int default 2000;
while i <= 500 do
-- 随机学生id:1001 ~ 1500
set sid = floor(1001 + rand() * 500);
-- 随机课程id:101 ~ 600
set cid = floor(101 + rand() * 500);
-- 尝试插入,跳过已存在的组合
begin
declare continue handler for 1062 begin end; -- 忽略重复键错误
insert into `student_course` (student_id, course_id, select_time, score, is_valid)
values (
sid,
cid,
now() - interval floor(rand() * 365) day, -- 近一年内选课
if(rand() > 0.2, round(40 + rand() * 60, 2), null), -- 80% 有成绩
if(rand() > 0.1, 1, 0) -- 90% 有效,10% 已退课
);
-- 成功插入才计数
set i = i + 1;
end;
set retry_count = retry_count + 1;
if retry_count > max_retries then
signal sqlstate '45000' set message_text = '插入失败:可能可用的 (student_id, course_id) 组合已耗尽';
end if;
end while;
end$$
delimiter ;
-- 执行并清理
call insertstudentcourse();
drop procedure if exists insertstudentcourse;
-- 检查每张表的数据量
select 'student' as table_name, count(*) as count from student
union all
select 'course' as table_name, count(*) as count from course
union all
select 'student_course' as table_name, count(*) as count from student_course;二、查询语法及解释
1. 基础查询语法(单表 / 多表逗号连接)
select [all distinct] <字段名> [as 别名1] [, <字段名2> [as 别名2]] from <表名1> [as 表1别名] [, <表名2> [as 表2别名], ...] [where <检索条件>] [group by <列名1> [having <条件表达式>]] [order by <列名2> [asc desc]];
2. join连接查询语法(多表关联)
select [all distinct] 字段名1 [as 别名1], 字段名2 [as 别名2], ... from 表名1 [as 表1别名] [inner left right [outer] cross] join 表名2 [as 表2别名] on 条件;
| 类别 | 细分项 | 作用/说明 | 关键特征 |
|---|---|---|---|
| from 与 join 子句 | - 左表(表名1) | 连接的基础表,作为查询的"基准"数据源 | 在 left join 中会保留所有记录;在 inner join 中仅保留匹配记录 |
| - 右表(表名2) | 需与左表关联的表,提供补充数据 | 在 right join 中会保留所有记录;在 inner join 中仅保留匹配记录 | |
| - 连接方式 | 定义两表记录的匹配规则,决定结果集中包含哪些记录 | 不同连接类型直接影响结果集的范围(如交集、左表全量、右表全量等) | |
| 连接类型 | inner join(内连接) | 返回两表中同时满足 on 条件的记录 | 仅保留交集,无匹配的记录不显示 |
| left [outer] join(左外连接) | 返回左表所有记录 + 右表中满足 on 条件的匹配记录 | 左表无匹配时,右表字段显示 null;右表不影响左表记录的完整性 | |
| right [outer] join(右外连接) | 返回右表所有记录 + 左表中满足 on 条件的匹配记录 | 右表无匹配时,左表字段显示 null;左表不影响右表记录的完整性 | |
| cross join(交叉连接) | 返回两表的笛卡尔积(所有可能的记录组合) | 无需 on 条件,结果行数 = 左表行数 × 右表行数,通常需配合 where 过滤冗余数据 | |
| on 子句 | 关联条件 | 定义两表记录的匹配规则(如 表1.字段a = 表2.字段b) | 过滤无效组合,仅保留逻辑关联的记录;join 必须配合 on 条件(除 cross join 外) |
三、数据连接查询
1. 内连接查询
内连接(inner join)只会返回两表中同时满足连接条件的记录,相当于两个表的交集。
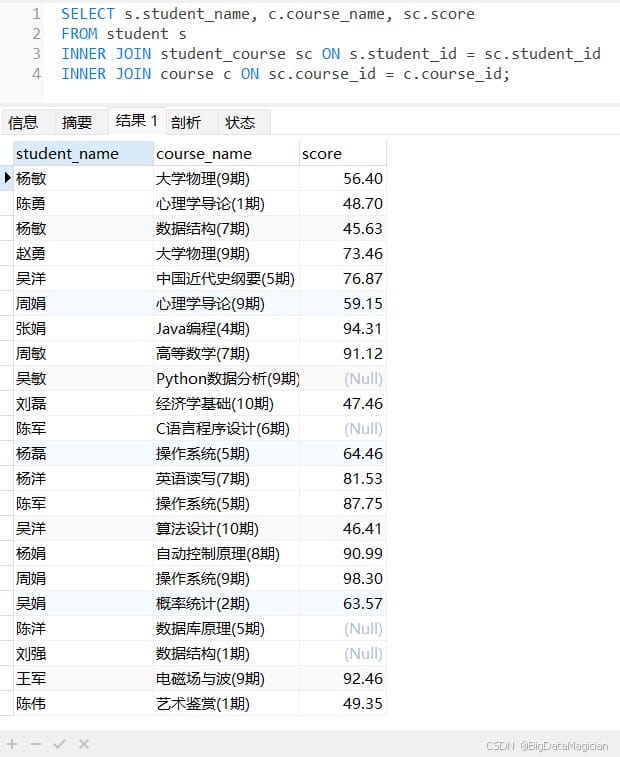
示例1:查询所有学生的选课信息,包括学生姓名、课程名称和成绩
select s.student_name, c.course_name, sc.score from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id;
或
select s.student_name, c.course_name, sc.score from student s, student_course sc, course c where s.student_id = sc.student_id and sc.course_id = c.course_id;
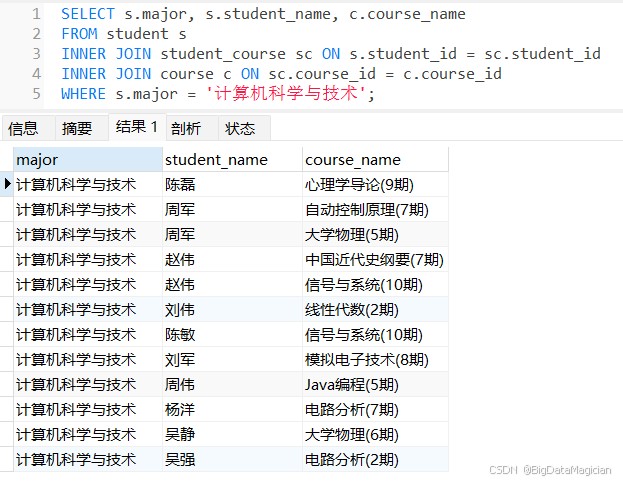
示例2:查询选修了“计算机科学与技术”专业课程的学生姓名和课程名称
select s.student_name, c.course_name from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id where s.major = '计算机科学与技术';
或
select s.major, s.student_name, c.course_name from student s, student_course sc, course c where s.student_id = sc.student_id and sc.course_id = c.course_id and s.major = '计算机科学与技术';
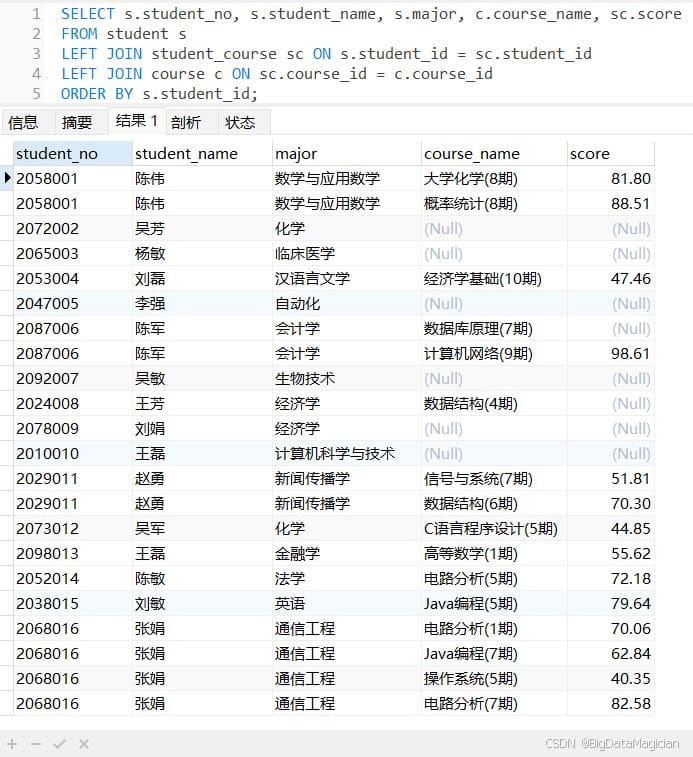
2. 左外连接查询
左外连接(left outer join / left join)以左表为基准,返回左表的所有记录,同时匹配右表中满足条件的记录。若右表无匹配,右表字段用 null 填充。
示例1:查询所有学生的基本信息及他们的选课成绩(含没选课的学生)。
select s.student_no, s.student_name, s.major, c.course_name, sc.score from student s left join student_course sc on s.student_id = sc.student_id left join course c on sc.course_id = c.course_id order by s.student_id;
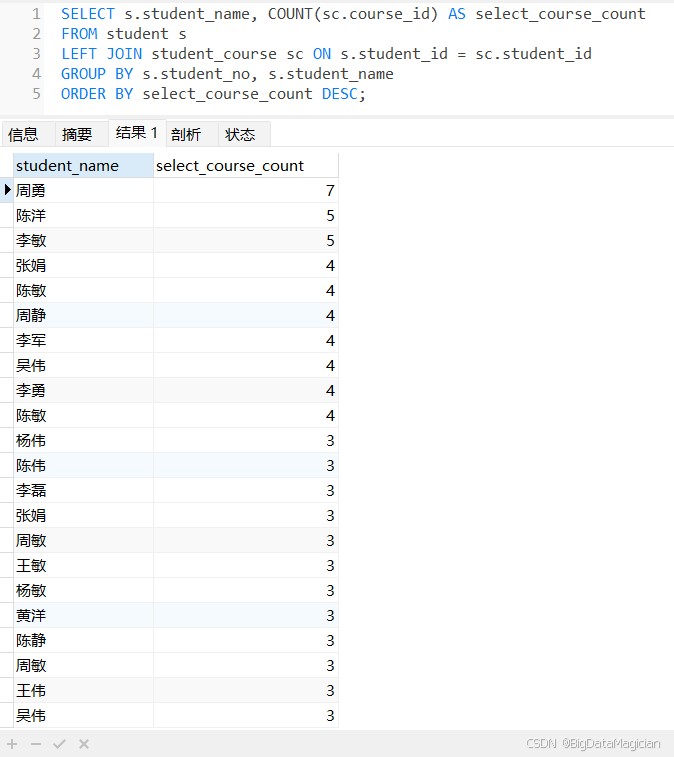
示例2:统计每个学生的选课数量(没选课的学生计数为 0)。
select s.student_name, count(sc.course_id) as select_course_count from student s left join student_course sc on s.student_id = sc.student_id group by s.student_no, s.student_name order by select_course_count desc;
3. 右外连接查询
右外连接(right outer join / right join)以右表为基准,返回右表的所有记录,同时匹配左表中满足条件的记录。若左表无匹配,左表字段用 null 填充。
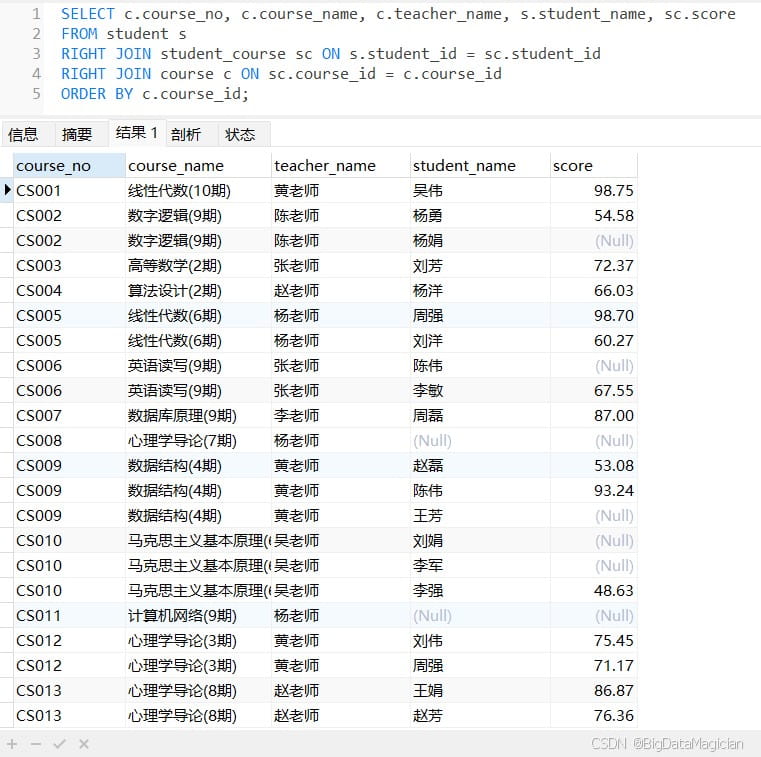
示例1:查询所有课程的信息及选该课的学生成绩(含没被选的课程)。
select c.course_no, c.course_name, c.teacher_name, s.student_name, sc.score from student s right join student_course sc on s.student_id = sc.student_id right join course c on sc.course_id = c.course_id order by c.course_id;
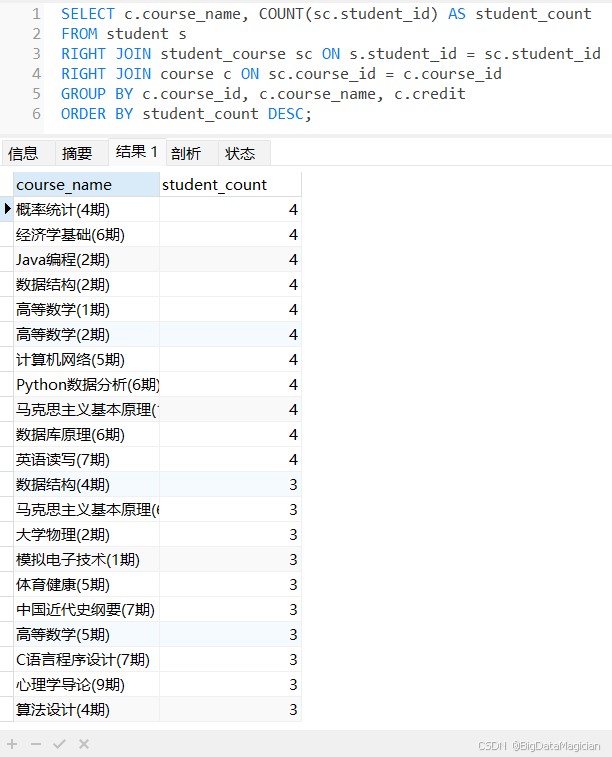
示例2:统计每门课程的选课人数(没被选的课程计数为 0)。
select c.course_name, count(sc.student_id) as student_count from student s right join student_course sc on s.student_id = sc.student_id right join course c on sc.course_id = c.course_id group by c.course_id, c.course_name, c.credit order by student_count desc;
4. 交叉连接查询
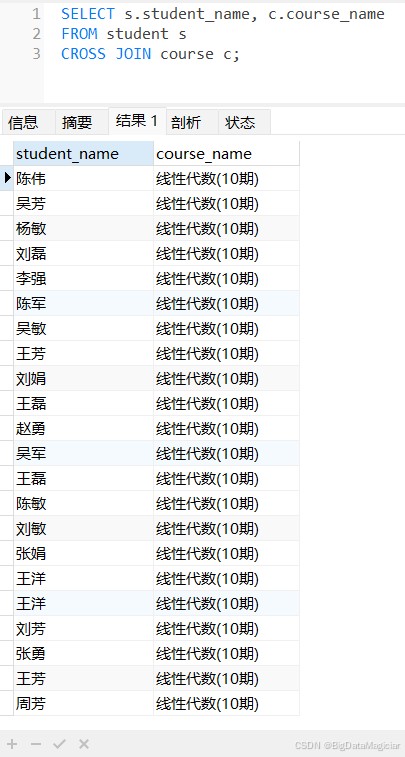
交叉连接(cross join) 用于返回两个表的笛卡尔积,即左表的每一行与右表的每一行都形成一条记录,结果集的行数 = 左表行数 × 右表行数。 交叉连接本身不使用 on 条件过滤,通常需要配合 where 子句筛选有效数据,否则结果可能包含大量冗余记录。
示例1:生成“所有学生与所有课程的组合”(例如:用于初始化选课系统的可选列表)。
select s.student_name, c.course_name from student s cross join course c;
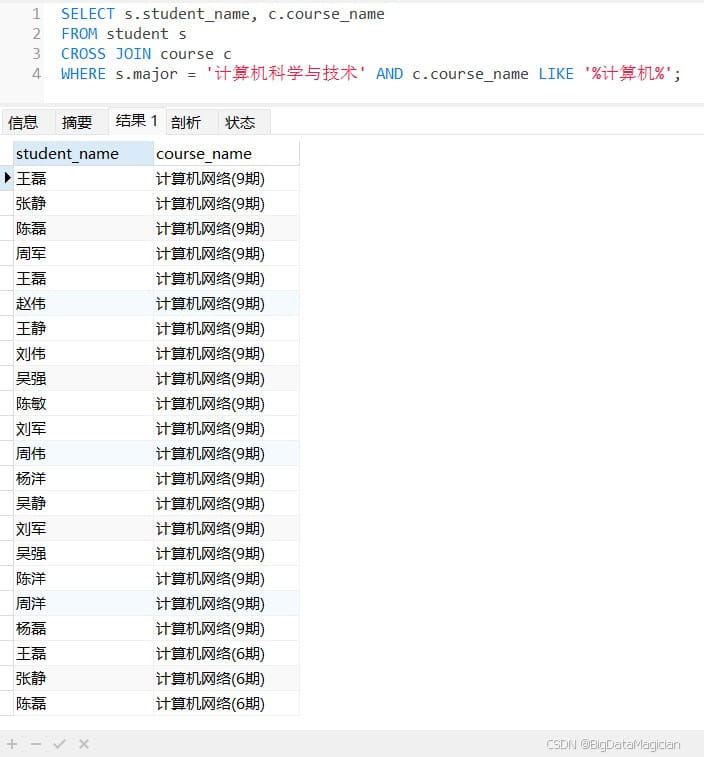
示例2:在特定条件下筛选交叉组合(例如:为“计算机科学与技术”专业的学生匹配所有“计算机类”课程(课程名含“计算机”))。
select s.student_name, c.course_name from student s cross join course c where s.major = '计算机科学与技术' and c.course_name like '%计算机%';
5. 自连接查询
自连接是表与自身的连接,即把一张表当作两张不同的表(通过别名区分),用于查询表中“具有关联关系的记录”。
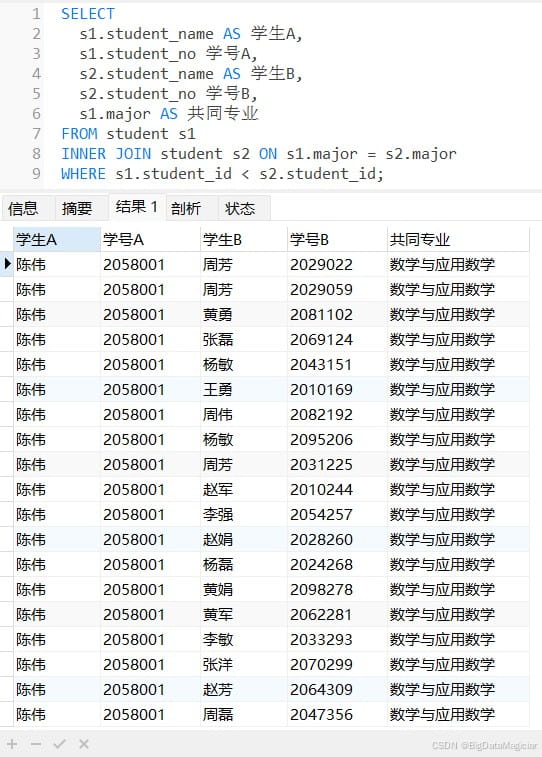
示例:查找同专业的学生。
select s1.student_name as 学生a, s1.student_no 学号a, s2.student_name as 学生b, s2.student_no 学号b, s1.major as 共同专业 from student s1 inner join student s2 on s1.major = s2.major where s1.student_id < s2.student_id;
或
select s1.student_name as 学生a, s1.student_no 学号a, s2.student_name as 学生b, s2.student_no 学号b, s1.major as 共同专业 from student s1, student s2 where s1.major = s2.major and s1.student_id < s2.student_id;
四、子查询
子查询指嵌套在主查询中的查询语句,通常用于为主查询提供“条件值”或“数据集”,可放在 select、from、where 等子句中。
1. 子查询语法
子查询需用 括号 () 包裹,按返回结果可分为三类,语法结构对应不同场景:
| 子查询类型 | 返回结果 | 适用场景 | 语法示例片段 |
|---|---|---|---|
| 标量子查询 | 单个值(1行1列) | 为主查询提供单个条件值(如对比、赋值) | where 主表字段 = (select 字段 from 子表 where 条件) |
| 列子查询 | 单个列的多个值(n行1列) | 配合 in/not in/any/all 筛选 | where 主表字段 in (select 字段 from 子表 where 条件) |
| 表子查询 | 多个列的数据集(n行m列) | 作为主查询的“临时表”,需起别名 | from (select 字段1,字段2 from 子表 where 条件) as 临时表名 |
2. 子查询示例
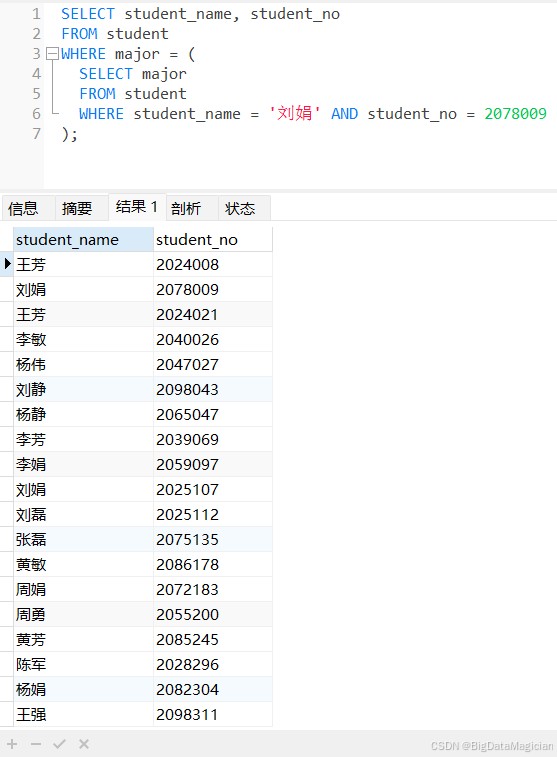
示例1:标量子查询,查询与“刘娟”同专业的所有学生姓名和学号。
select student_name, student_no from student where major = ( select major from student where student_name = '刘娟' and student_no = 2078009 );
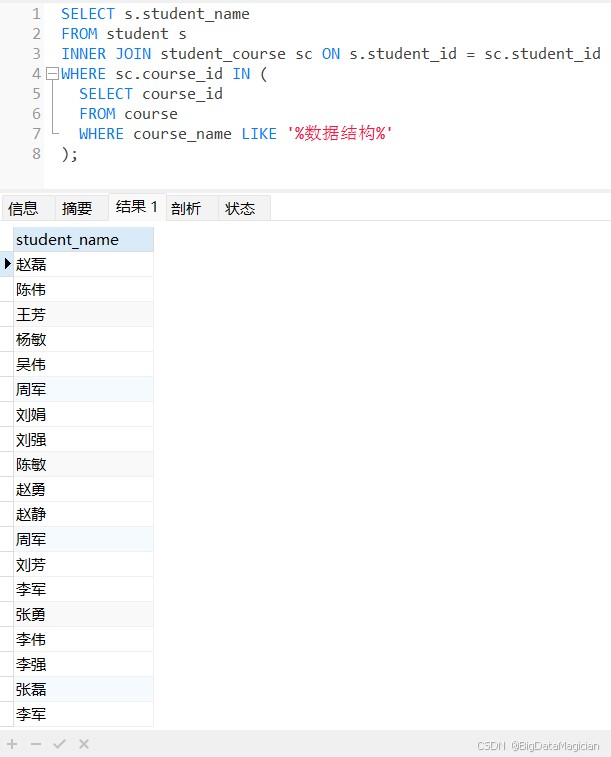
示例2:列子查询,查询“数据结构”课程的所有选课学生姓名。
select s.student_name from student s inner join student_course sc on s.student_id = sc.student_id where sc.course_id in ( select course_id from course where course_name like '%数据结构%' );
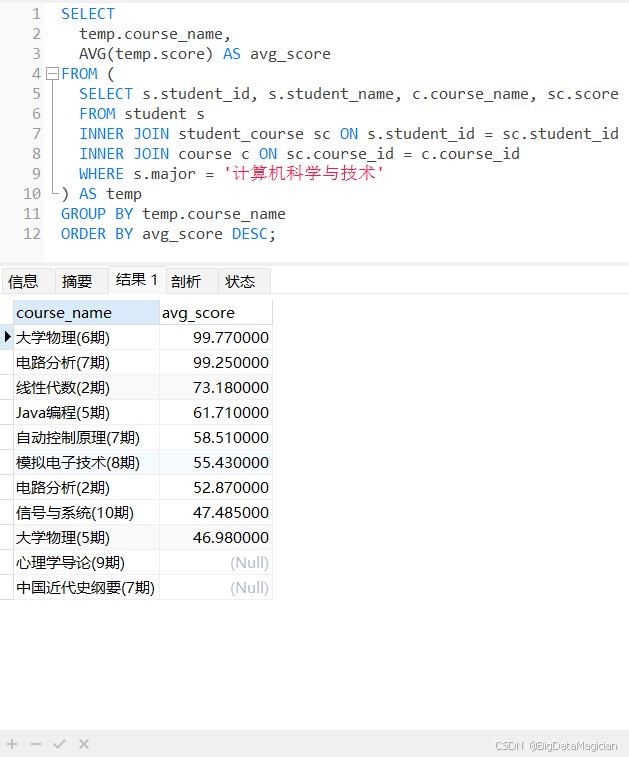
示例3:表子查询,查询“计算机科学与技术”专业学生的平均成绩作为临时表,查询每门课程的平均成绩。
select temp.course_name, avg(temp.score) as avg_score from ( select s.student_id, s.student_name, c.course_name, sc.score from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id where s.major = '计算机科学与技术' ) as temp group by temp.course_name order by avg_score desc;
示例4:exists 子查询(判断是否存在记录),查询“至少选了1门课且成绩≥90分”的学生姓名。
用 exists 判断子查询是否返回结果(无需关注具体值,只看“有无”),效率比 in 更高。
select student_name from student s where exists ( select 1 from student_course sc where sc.student_id = s.student_id and sc.score >= 90 );
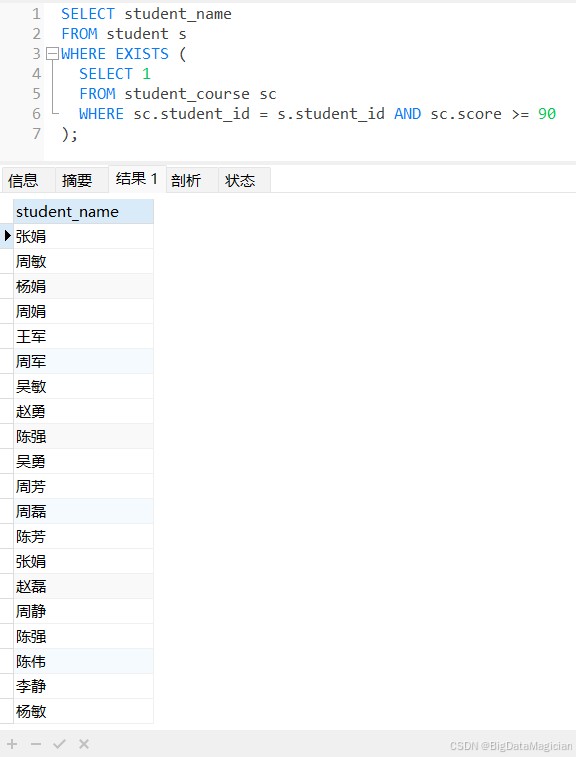
五、集合运算查询
集合运算用于将两个或多个查询结果集进行组合,主要包括 union、union all、intersect 和 except 四种,它们的核心是对结果集进行"合并"或"筛选"操作。
| 运算类型 | 语法格式 | 作用说明 | 关键特性 |
|---|---|---|---|
| union | 查询1 union 查询2 | 合并两个查询结果,自动去除重复记录 | 结果集列数和数据类型必须一致;会进行去重操作,性能略低 |
| union all | 查询1 union all 查询2 | 合并两个查询结果,保留所有记录(包括重复) | 列要求同上;不去重,性能优于 union |
| intersect | 查询1 intersect 查询2 | 返回两个结果集的交集(同时存在于两个结果集的记录) | mysql 不直接支持,需用 join 替代 |
| except | 查询1 except 查询2 | 返回两个结果集的差集(在查询1中但不在查询2中的记录) | mysql 不直接支持,需用 left join + is null 替代 |
1. 合并结果集(union 与 union all)
查询"计算机科学与技术"专业的学生和"数据库原理"课程的选课学生,合并结果并去重。
select student_id, student_name, '计算机专业学生' as type from student where major = '计算机科学与技术' union select s.student_id, s.student_name, '数据库选课学生' as type from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id where c.course_name like '%数据库原理%';
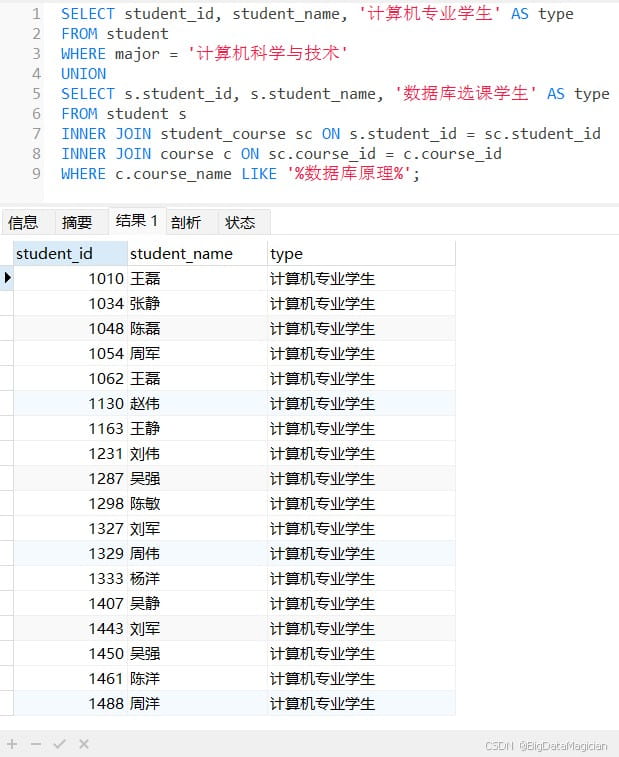
2. 求交集(intersect )
查询既选了"数据库"又选了"计算机"的学生姓名。
select s1.student_name from ( select s.student_id, s.student_name from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id where c.course_name like '%数据库%' ) s1 inner join ( select s.student_id from student s inner join student_course sc on s.student_id = sc.student_id inner join course c on sc.course_id = c.course_id where c.course_name like '%计算机%' ) s2 on s1.student_id = s2.student_id;
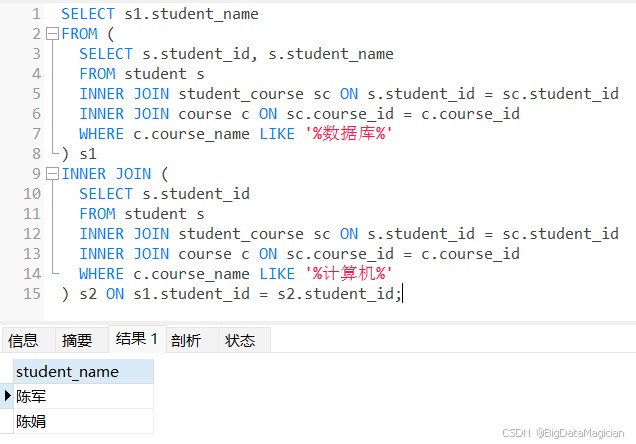
3. 求差集(except)
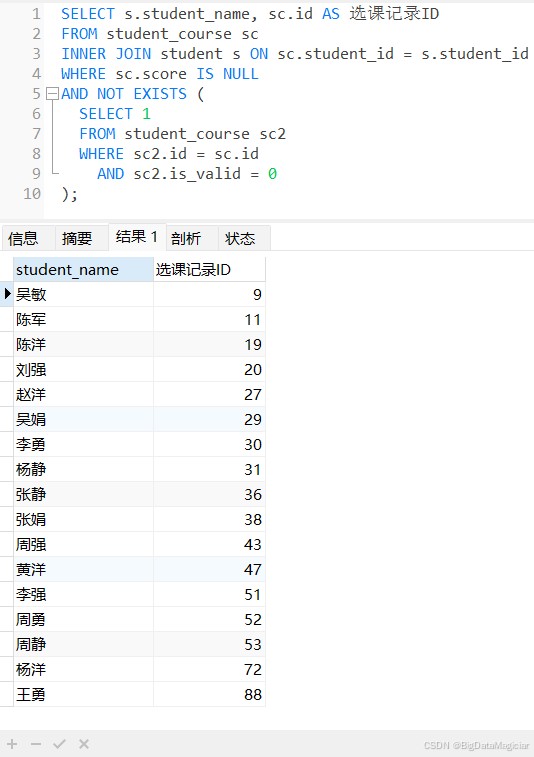
查询选了课但成绩未录入(score为null)的学生,排除已经退课的(is_valid=0)。
select s.student_name, sc.id as 选课记录id
from student_course sc
inner join student s on sc.student_id = s.student_id
where sc.score is null
and not exists (
select 1
from student_course sc2
where sc2.id = sc.id
and sc2.is_valid = 0
);
到此这篇关于mysql数据连接查询和子查询操作的文章就介绍到这了,更多相关mysql连接查询与子查询内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论