1. 引言:流数据时代的挑战与机遇
在当今的大数据时代,数据的产生方式发生了根本性的变化。传统的数据处理模式是批处理(batch processing),即定期(如每小时、每天)收集和处理大量静态数据。然而,随着物联网(iot)、社交媒体、实时监控、金融交易等应用的爆炸式增长,数据正以前所未有的速度和规模持续不断地生成。这种连续、无界、快速的数据序列被称为数据流(data stream)。
流处理(stream processing) 就是专门为应对这种持续数据流而设计的一种计算范式。它的核心目标是在数据产生后极短的时间内(通常是毫秒到秒级)对其进行处理、分析并得到见解,从而支持实时决策,而不是等待所有数据都到位后再进行事后分析。
与批处理相比,流处理带来了独特的挑战:
- 数据无界性(unbounded data):数据流理论上永无止境,没有明确的终点。
- 低延迟要求(low latency):处理结果的价值随时间迅速衰减,必须快速响应。
- 高性能与高吞吐(high performance & throughput):系统需要持续处理高速到达的数据。
- 容错性(fault tolerance):在长时间运行中,任何环节都可能出错,系统必须能优雅地处理故障并恢复,保证结果的正确性。
python,凭借其丰富的生态系统(如pandas, numpy, scikit-learn)和强大的库支持,在数据科学和快速原型开发中占据主导地位。虽然大规模、超低延迟的工业级流处理通常由java/scala构建的框架(如flink, spark streaming, kafka streams)承担,但python在中小规模数据流、概念验证(poc)、实时特征提取和在线机器学习等领域具有极大的敏捷性和优势。
本文将深入探讨如何使用python构建一个健壮的流处理实时分析系统,涵盖核心概念、技术选型、实现细节和最佳实践。
2. 流处理核心概念
在开始编码之前,理解以下几个核心概念至关重要。
2.1 流(stream)
流是一系列连续且无序的时间序列数据片段(或称为事件/消息)的抽象。例如,用户的点击日志、传感器的温度读数、股票市场的交易报价都是流。
2.2 时间(time)与窗口(window)
由于数据流是无界的,我们无法等待“所有”数据到来再进行计算。因此,我们需要一种机制来将无限流切分成有限的“块”进行处理,这就是窗口(window)。
窗口通常由时间来驱动,主要有以下几种类型:
- 滚动窗口(tumbling window):窗口大小固定且不重叠。例如,每5分钟统计一次访问量。windowsize=5mins
- 滑动窗口(sliding window):窗口大小固定,但窗口之间可以重叠。它有一个滑动步长的参数。例如,每1分钟统计一次过去5分钟内的访问量。windowsize=5mins,slideinterval=1min
- 会话窗口(session window):根据事件之间的活跃度(如超过一定时间无活动)来划分窗口,常用于用户行为分析。
时间本身也有两个重要概念:
- 事件时间(event time):事件实际发生的时间,通常嵌入在数据本身中。
- 处理时间(processing time):事件被流处理系统处理的时间。
处理基于事件时间的流数据是更准确的,但也更复杂,因为它需要处理乱序和延迟到达的事件。
2.3 状态(state)
许多流处理应用需要跨事件记录信息,例如计算一个小时内某个用户的点击次数。这个“次数”就是一种状态(state)。流处理框架必须能够高效、可靠地管理和持久化状态,以便在发生故障时能够恢复。
3. 技术栈与工具选型
一个典型的python流处理管道通常包含以下组件:
1.数据源(data source):产生或发送数据流的系统。我们通常使用消息队列来解耦数据生产者和消费者。
- apache kafka:行业标准的高吞吐分布式消息系统。使用
confluent-kafka或kafka-python库连接。 - redis pub/sub:简单轻量,适用于中小规模场景。
- mqtt:物联网(iot)领域的标准协议,非常轻量。
- 模拟数据源:对于学习和测试,我们可以用python代码模拟一个数据流。
2.流处理框架/库(processing framework/library):核心计算引擎。
- apache spark (structured streaming):通过
pyspark可以使用其强大的分布式流处理能力。 - faust:一个纯python的流处理库,借鉴了kafka streams的理念,api优雅。
- bytewax:一个新兴的、非常有潜力的python原生流处理框架。
- pandas / pure python:对于非常简单或低吞吐的场景,可以使用循环或定时器进行微批处理。
3.数据接收端(data sink):处理结果的输出目的地。
- 数据库:如postgresql, mysql, influxdb(时序数据库), redis。
- 数据仓库:如google bigquery, amazon redshift。
- 消息队列:如另一个kafka topic。
- 可视化仪表盘:如grafana, kibana。
- 文件系统:如csv, parquet文件。
本文选择的技术栈:
考虑到普及性和易于理解,我们将使用kafka作为消息队列,并使用纯python(confluent-kafka + pandas) 来实现一个微批处理(micro-batch)的示例。这种模式简单直观,足以阐明流处理的核心思想,并且易于扩展和修改。
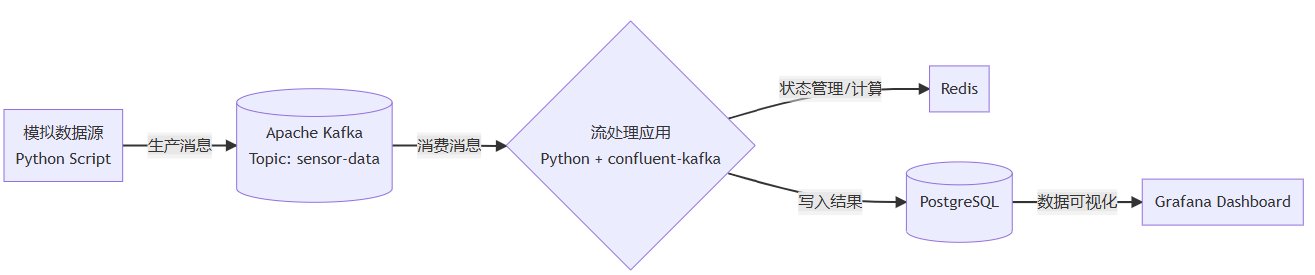
4. 实战:构建一个实时传感器数据分析系统
4.1 场景描述
假设我们有一个温度传感器网络,每个传感器每秒上报一次数据。我们需要实时监控这些数据:
- 实时计算每个传感器最近1分钟的平均温度(滚动窗口)。
- 实时检测异常值(例如,温度瞬间飙升或跌落超过一定阈值)。
4.2 系统架构与数据流
我们的系统架构和数据流如下所示:

4.3 环境准备与依赖安装
首先,确保已安装kafka并成功启动zookeeper和kafka server。然后安装必要的python库:
pip install confluent-kafka pandas numpy datetime
4.4 实现步骤
步骤一:模拟传感器数据生产者(kafka producer)
我们首先创建一个python脚本来模拟传感器,源源不断地向kafka topic发送数据。
# sensor_simulator.py
from confluent_kafka import producer
import json
import time
import random
import logging
# 配置日志
logging.basicconfig(level=logging.info)
logger = logging.getlogger(__name__)
# kafka配置
conf = {'bootstrap.servers': 'localhost:9092'}
# 创建producer实例
producer = producer(conf)
# 回调函数,确认消息是否成功发送
def delivery_report(err, msg):
if err is not none:
logger.error(f'message delivery failed: {err}')
else:
logger.info(f'message delivered to {msg.topic()} [{msg.partition()}]')
# 模拟的传感器id列表
sensor_ids = [f'sensor_{i}' for i in range(1, 4)]
try:
while true:
for sensor_id in sensor_ids:
# 模拟温度数据:基础值20°c,加上随机波动
base_temp = 20.0
fluctuation = random.uniform(-2, 2)
# 小概率模拟一个异常峰值
if random.random() < 0.02:
fluctuation += random.choice([15, -15])
logger.warning(f"simulating anomaly for {sensor_id}")
temperature = base_temp + fluctuation
# 构造消息内容:传感器id、温度值、时间戳
message = {
'sensor_id': sensor_id,
'temperature': round(temperature, 2),
'timestamp': int(time.time() * 1000) # 毫秒时间戳
}
# 将消息转换为json字符串并发送到kafka
message_json = json.dumps(message)
producer.produce(
'sensor-readings-raw',
key=sensor_id, # 使用sensor_id作为key,确保同一传感器的数据进入同一分区
value=message_json,
callback=delivery_report
)
# 立即轮询以触发回调
producer.poll(0)
# 每秒发送一轮所有传感器的数据
time.sleep(1)
except keyboardinterrupt:
logger.info("producer interrupted by user.")
finally:
# 等待所有未完成的消息被发送
producer.flush()
步骤二:实现流处理消费者(kafka consumer + 窗口计算)
这是流处理的核心。我们将创建一个消费者,从kafka拉取消息,并进行微批处理(例如每10秒处理一次),计算每个传感器在过去1分钟(60秒)内的平均温度。
# stream_processor.py
from confluent_kafka import consumer, kafkaerror
import pandas as pd
import json
import time
from collections import defaultdict
import logging
# 配置日志
logging.basicconfig(level=logging.info, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getlogger(__name__)
# kafka消费者配置
consumer_conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'sensor-stream-processor',
'auto.offset.reset': 'earliest' # 如果没有偏移量,从最早的消息开始读
}
# 创建consumer实例
consumer = consumer(consumer_conf)
consumer.subscribe(['sensor-readings-raw'])
# 初始化一个字典来存储未处理的数据
# 结构: {sensor_id: list_of_(timestamp, temperature)_tuples}
raw_data_store = defaultdict(list)
# 窗口大小(毫秒)
window_size_ms = 60 * 1000 # 1分钟
# 微批处理间隔(秒)
batch_interval = 10
def process_window(sensor_id, data_list):
"""
处理一个传感器的一个窗口内的数据。
计算平均值,并返回结果。
"""
if not data_list:
return none
# 将数据列表转换为pandas dataframe以便计算
df = pd.dataframe(data_list, columns=['timestamp', 'temperature'])
# 计算统计量
avg_temp = df['temperature'].mean()
max_temp = df['temperature'].max()
min_temp = df['temperature'].min()
count = len(df)
# 获取窗口的时间范围
window_end = max(df['timestamp'])
window_start = window_end - window_size_ms
result = {
'sensor_id': sensor_id,
'window_start': window_start,
'window_end': window_end,
'avg_temperature': round(avg_temp, 2),
'max_temperature': round(max_temp, 2),
'min_temperature': round(min_temp, 2),
'count': count,
'processing_time': int(time.time() * 1000)
}
logger.info(f"processed window for {sensor_id}: {result}")
return result
def check_anomaly(current_value, previous_value, threshold=5.0):
"""
简单的异常检测:检查当前值与前一个值的变化是否超过阈值。
在实际应用中,可以使用更复杂的算法(如z-score, isolation forest)。
"""
if previous_value is none:
return false
return abs(current_value - previous_value) > threshold
# 用于记录每个传感器上一个已知的值(用于简单异常检测)
last_values = {}
try:
last_batch_time = time.time()
logger.info("starting stream processing...")
while true:
# 等待消息,超时时间为1秒
msg = consumer.poll(1.0)
if msg is none:
# 没有收到消息
pass
elif msg.error():
if msg.error().code() == kafkaerror._partition_eof:
# end of partition event
logger.info(f'reached end of partition {msg.partition()}')
else:
logger.error(f'consumer error: {msg.error()}')
else:
# 成功收到消息
try:
# 解析消息
message_json = msg.value().decode('utf-8')
data = json.loads(message_json)
sensor_id = data['sensor_id']
temperature = data['temperature']
timestamp = data['timestamp']
# 将数据存入临时存储
raw_data_store[sensor_id].append((timestamp, temperature))
# --- 简单实时异常检测(逐条检测) ---
previous_value = last_values.get(sensor_id)
if check_anomaly(temperature, previous_value):
logger.warning(f"anomaly detected! sensor: {sensor_id}, "
f"current: {temperature}, previous: {previous_value}")
last_values[sensor_id] = temperature
# ----------------------------------
except (json.jsondecodeerror, keyerror, unicodedecodeerror) as e:
logger.error(f"error processing message: {e}, raw value: {msg.value()}")
# 检查是否到达微批处理时间
current_time = time.time()
if current_time - last_batch_time >= batch_interval:
logger.info(f"--- starting micro-batch processing ---")
results = []
# 获取当前时间(毫秒),作为窗口的结束边界
now_ms = int(current_time * 1000)
window_start_boundary = now_ms - window_size_ms
# 处理每个传感器的数据
for sensor_id, data_list in raw_data_store.items():
# 过滤出在最近1分钟窗口内的数据
window_data = [(ts, temp) for (ts, temp) in data_list if ts >= window_start_boundary]
# 更新存储,只保留窗口内的数据(防止内存无限增长)
raw_data_store[sensor_id] = window_data
# 如果窗口内有数据,则进行处理
if window_data:
result = process_window(sensor_id, window_data)
if result:
results.append(result)
# 在这里,可以将results写入数据库、另一个kafka topic或发布出去
# 例如: write_to_database(results)
# 或者: produce_to_kafka('sensor-readings-aggregated', results)
logger.info(f"micro-batch completed. processed {len(results)} sensor windows.")
# 重置批处理计时器
last_batch_time = current_time
except keyboardinterrupt:
logger.info("consumer interrupted by user.")
finally:
# 关闭消费者,释放资源
consumer.close()
5. 关键组件深入解析
5.1 窗口化处理
我们的process_window函数实现了基于处理时间的滚动窗口。它每隔batch_interval秒,会计算每个传感器在过去window_size_ms毫秒内所有数据的聚合值(平均值、最大值等)。
- 优点:实现简单。
- 缺点:如果数据延迟到达(处理时间 > 事件时间),它将被错误地排除在窗口之外,导致计算结果不准确。要实现更准确的基于事件时间的窗口,需要引入水印(watermark)机制来处理乱序数据,这在纯python中实现较为复杂,通常需借助flink或spark等框架。
5.2 状态管理
在本例中,我们使用内存中的字典raw_data_store来缓存原始数据。这是一种易失性状态。
缺点:如果处理程序崩溃,所有内存中的状态都会丢失,重新启动后将从kafka的当前偏移量开始消费,可能导致数据丢失或重复计算。
改进方案:
- 使用外部数据库:将状态(如每个传感器的上一个值、窗口数据)存储在redis或postgresql中。处理消息前先加载状态,处理后再更新状态。
- 使用kafka streams / faust / bytewax:这些框架内置了持久化、容错的状态存储,并支持定期将状态备份到kafka topic中,故障恢复时可以自动重建状态。
- 定期提交偏移量:在处理完一批消息并成功更新状态后,再手动提交kafka消费偏移量(
consumer.commit()),这样可以保证“至少一次”的处理语义。
5.3 异常检测
我们实现了一个极其简单的异常检测:比较当前值和前一个值的差异。在实际工业场景中,可能会使用:
- 统计方法:z-score(z=(x−μ)/σ)或移动平均/标准差。
- 机器学习:使用隔离森林(isolation forest)或自动编码器(autoencoder)等无监督学习模型进行在线异常检测。
6. 生产环境考量与优化
性能与并行性:
- kafka分区:kafka的并行单元是分区。确保topic有足够的分区,并启动多个消费者实例(在同一消费者组内)来并行处理。我们的代码使用
sensor_id作为消息键,确保了同一传感器的数据总是进入同一分区,从而保证了每个传感器窗口计算的正确性。 - 异步处理:使用
asyncio等异步库来处理i/o密集型操作(如读写数据库)。
容错性与交付语义:
- 至少一次(at-least-once):确保消息在处理成功后偏移量才被提交。这是最常见的语义。
- 精确一次(exactly-once):需要框架级别的支持(如kafka transactions),保证计算和偏移量提交是原子性的。python原生实现极其困难。
监控与可观测性:
- 记录详细的日志。
- 集成prometheus、statsd等工具上报 metrics(如消息吞吐量、处理延迟、窗口数据量)。
- 使用grafana等工具绘制仪表盘监控系统健康状态。
资源清理:
- 我们的代码实现了
finally块来确保消费者正确关闭。 - 对于长时间运行的窗口状态,需要实现ttl(生存时间)机制,自动清理长时间不活跃的传感器数据,防止内存泄漏。
7. 完整代码
以下是整合后的核心流处理代码,增加了注释和部分优化。
# comprehensive_stream_processor.py
"""
一个完整的流处理示例:消费kafka中的传感器数据,进行窗口聚合计算和简单异常检测。
注意:这是一个示例,生产环境需考虑状态持久化、容错、并行性等更多因素。
"""
from confluent_kafka import consumer, producer, kafkaerror
import pandas as pd
import json
import time
from collections import defaultdict
import logging
from datetime import datetime
# 配置日志
logging.basicconfig(
level=logging.info,
format='%(asctime)s - %(name)s - %(levelname)s - [%(filename)s:%(lineno)d] - %(message)s'
)
logger = logging.getlogger('streamprocessor')
# #################### 配置参数 ####################
kafka_bootstrap_servers = 'localhost:9092'
kafka_raw_topic = 'sensor-readings-raw'
kafka_agg_topic = 'sensor-readings-aggregated'
kafka_alert_topic = 'sensor-alerts'
consumer_group_id = 'sensor-stream-processor-v1'
window_size_ms = 60 * 1000 # 聚合窗口大小:1分钟
batch_processing_interval = 10 # 微批处理间隔:10秒
anomaly_threshold = 5.0 # 异常检测阈值:温度变化超过5°c
# #################### kafka 客户端配置 ####################
consumer_conf = {
'bootstrap.servers': kafka_bootstrap_servers,
'group.id': consumer_group_id,
'auto.offset.reset': 'earliest',
'enable.auto.commit': false # 禁用自动提交,改为手动提交
}
producer_conf = {'bootstrap.servers': kafka_bootstrap_servers}
# #################### 初始化客户端 ####################
consumer = consumer(consumer_conf)
producer = producer(producer_conf)
consumer.subscribe([kafka_raw_topic])
# #################### 状态存储 ####################
# 存储原始数据:{sensor_id: [(timestamp_ms, temperature), ...]}
raw_data_store = defaultdict(list)
# 存储上一个值,用于异常检测:{sensor_id: last_temperature}
last_values = {}
# #################### 工具函数 ####################
def delivery_report(err, msg):
""" producer消息发送回调函数 """
if err is not none:
logger.error(f'message delivery failed ({msg.topic()}): {err}')
else:
logger.debug(f'message delivered to {msg.topic()} [{msg.partition()}]')
def produce_to_kafka(topic, key, value):
""" 发送消息到kafka """
try:
producer.produce(
topic,
key=key,
value=json.dumps(value),
callback=delivery_report
)
producer.poll(0) # 轮询以服务回调队列
except buffererror as e:
logger.error(f'producer buffer error: {e}')
producer.poll(10) # 等待一些空间
def process_window(sensor_id, data_list, window_end_ms):
"""
处理一个传感器的一个窗口内的数据,计算聚合统计量。
args:
sensor_id: 传感器id
data_list: 窗口内的数据列表,元素为(timestamp, temperature)
window_end_ms: 窗口结束时间戳(毫秒)
returns:
dict: 聚合结果字典
"""
if not data_list:
return none
df = pd.dataframe(data_list, columns=['timestamp', 'temperature'])
window_start_ms = window_end_ms - window_size_ms
result = {
'sensor_id': sensor_id,
'window_start_utc': window_start_ms,
'window_end_utc': window_end_ms,
'avg_temperature': round(df['temperature'].mean(), 2),
'max_temperature': round(df['temperature'].max(), 2),
'min_temperature': round(df['temperature'].min(), 2),
'count_readings': len(df),
'processing_time_utc': int(time.time() * 1000)
}
logger.info(f"aggregation complete for {sensor_id}: avg={result['avg_temperature']}°c")
return result
def check_anomaly(sensor_id, current_temp, threshold):
"""
简单异常检测:检查当前温度与上一次温度的变化是否超过阈值。
returns:
bool: 是否是异常
float: 变化量
"""
last_temp = last_values.get(sensor_id)
if last_temp is none:
return false, 0.0
change = abs(current_temp - last_temp)
return change > threshold, change
def cleanup_old_data(current_time_ms):
""" 清理所有传感器中超出当前窗口的旧数据,防止内存无限增长 """
cutoff = current_time_ms - window_size_ms
for sensor_id in list(raw_data_store.keys()):
# 只保留在时间窗口内的数据点
raw_data_store[sensor_id] = [
(ts, temp) for (ts, temp) in raw_data_store[sensor_id] if ts >= cutoff
]
# 如果某个传感器的数据列表为空,可选择删除该键以节省空间
if not raw_data_store[sensor_id]:
del raw_data_store[sensor_id]
# #################### 主处理循环 ####################
def main():
logger.info("starting kafka stream processing application...")
last_batch_time = time.time()
running = true
try:
while running:
# 1. 轮询kafka获取新消息
msg = consumer.poll(1.0) # 超时时间1秒
if msg is none:
continue
if msg.error():
if msg.error().code() == kafkaerror._partition_eof:
logger.debug('reached end of partition')
else:
logger.error(f'consumer error: {msg.error()}')
continue
# 2. 处理单条消息
try:
message_value = msg.value().decode('utf-8')
data = json.loads(message_value)
sensor_id = data['sensor_id']
temperature = data['temperature']
timestamp_ms = data['timestamp'] # 假设数据中自带事件时间戳
# 2.1 将数据存入窗口缓存
raw_data_store[sensor_id].append((timestamp_ms, temperature))
# 2.2 实时异常检测(逐条处理)
is_anomaly, delta = check_anomaly(sensor_id, temperature, anomaly_threshold)
if is_anomaly:
alert_message = {
'sensor_id': sensor_id,
'current_temperature': temperature,
'previous_temperature': last_values[sensor_id],
'delta': round(delta, 2),
'threshold': anomaly_threshold,
'timestamp': timestamp_ms,
'alert_time': int(time.time() * 1000)
}
logger.warning(f"anomaly alert: {alert_message}")
# 将警报发送到另一个kafka topic
produce_to_kafka(kafka_alert_topic, sensor_id, alert_message)
# 更新上一个值的状态
last_values[sensor_id] = temperature
except (keyerror, json.jsondecodeerror, valueerror, unicodedecodeerror) as e:
logger.error(f"failed to process message: {e}. raw value: {msg.value()}")
# 3. 微批处理:检查是否到达处理间隔
current_time = time.time()
if current_time - last_batch_time >= batch_processing_interval:
logger.info("--- starting micro-batch window aggregation ---")
batch_processing_time_ms = int(current_time * 1000)
window_end_boundary = batch_processing_time_ms # 以处理时间作为窗口结束
# 3.1 清理旧数据
cleanup_old_data(batch_processing_time_ms)
aggregated_results = []
# 3.2 处理每个传感器的窗口
for sensor_id, data_list in raw_data_store.items():
if data_list: # 确保有数据
result = process_window(sensor_id, data_list, window_end_boundary)
if result:
aggregated_results.append(result)
# 将聚合结果发送到kafka
produce_to_kafka(kafka_agg_topic, sensor_id, result)
logger.info(f"micro-batch completed. aggregated {len(aggregated_results)} windows.")
# 3.3 手动提交偏移量!确保在成功处理一批消息后再提交。
# 注意:这里是简单提交,生产环境应更谨慎,例如确保producer的消息也已发送。
consumer.commit(async=false) # 同步提交,更安全
logger.debug("kafka consumer offsets committed.")
last_batch_time = current_time
except keyboardinterrupt:
logger.info("shutdown signal received.")
running = false
except exception as e:
logger.exception(f"unexpected error occurred: {e}")
running = false
finally:
logger.info("shutting down...")
consumer.close()
producer.flush() # 确保所有producer消息都已发送
logger.info("shutdown complete.")
if __name__ == '__main__':
main()
8. 总结与展望
本文演示了如何使用python构建一个基本的流处理实时分析系统。我们利用kafka作为数据总线,使用confluent-kafka库进行数据的生产和消费,并实现了基于处理时间的滚动窗口聚合计算和简单的实时异常检测。
核心要点回顾:
- 流处理的核心是对无界数据进行持续计算,关键在于窗口化和状态管理。
- python的优势在于其生态和开发效率,非常适合原型设计、中小规模数据流和在线机器学习任务。
- 纯python实现的局限性在于容错性、状态管理和精确一次语义等方面。对于要求极高的生产环境,建议使用faust、bytewax或将pyspark与structured streaming结合使用。
- 一个健壮的流系统必须考虑性能、容错、监控和资源管理。
未来探索方向:
- 使用更强大的框架:尝试用faust或bytewax重写本例,体验其内置的状态管理和容错机制。
- 引入事件时间与水印:实现更准确的、基于事件时间的窗口处理。
- 复杂的在线机器学习:在流上实时更新模型,实现实时预测或异常检测。
- 与云原生技术结合:将应用容器化(docker)并在kubernetes上运行,实现弹性伸缩。
- 丰富的可视化:将聚合结果写入数据库(如influxdb),并使用grafana构建实时监控仪表盘。
流处理是一个复杂而有趣的领域,希望本文能为您使用python进入这一领域提供一个坚实的起点。
到此这篇关于从理论到实践详解python构建一个健壮的流处理实时分析系统的文章就介绍到这了,更多相关python流处理实时分析内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论