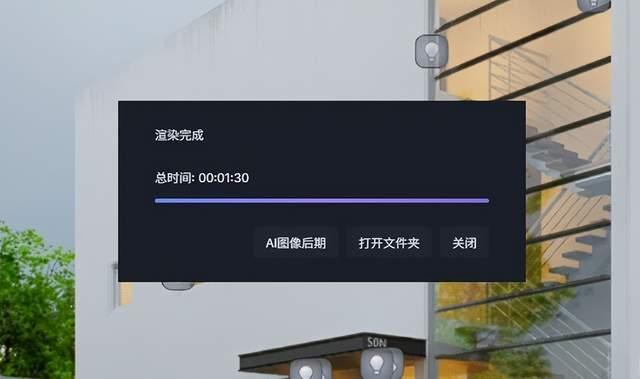

在超凡的生产力效率之外,锐龙ai ma×+ pro 395最为惊艳的还是极其优异的ai算力支持。往前倒1-2年,我们都很难想像能够在即使是最顶级的集成显卡平台上去跑ai,这就是为什么锐龙ai ma×+系列是真正具备革命意义本地ai硬件平台,它为很多面向ai本地部署、aigc、ai专业内容创意、科学计算、软件开发等应用场景的企业用户、开发者和个人用户提供了经济又实用的低成本解决方案,同时兼容运行众多软件,通过了多种isv认证。
同时,amd与amuse ai合作,还为锐龙aipc打造了专门的aigc工具amuse,通过它你可以快速部署适配amd锐龙平台的aigc大模型,除了可以做文生图、图生图,还可以做文生视频,而且支持调用amd npu进行超分辨率辅助或独立采用npu来完成图像生成,是目前非常好用且易用的aigc应用。
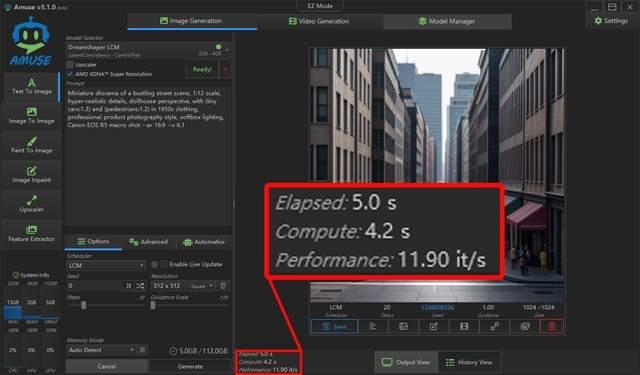
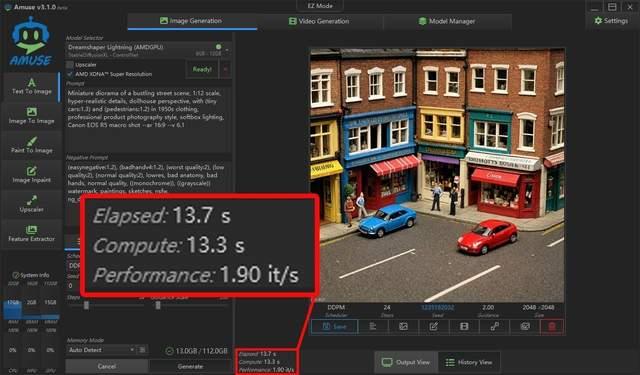
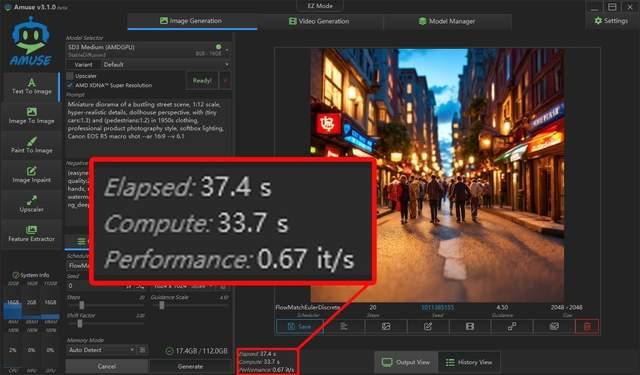
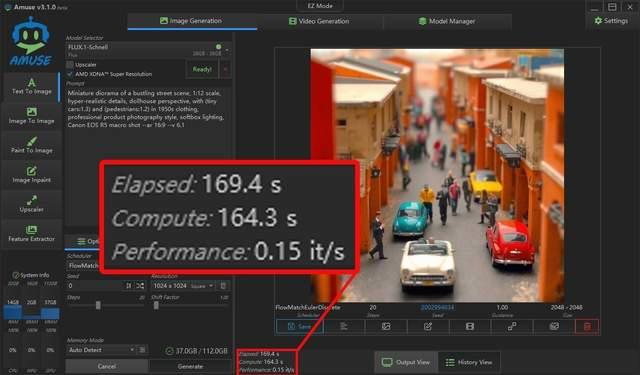
这里我们使用同样的一段提示词,分别在不同的大模型中做了文生图体验,精度不高的模型最快5秒钟就能生成一张图片,而高精度模型也只需37.4秒就能生成一张1024×1024规格的图片。
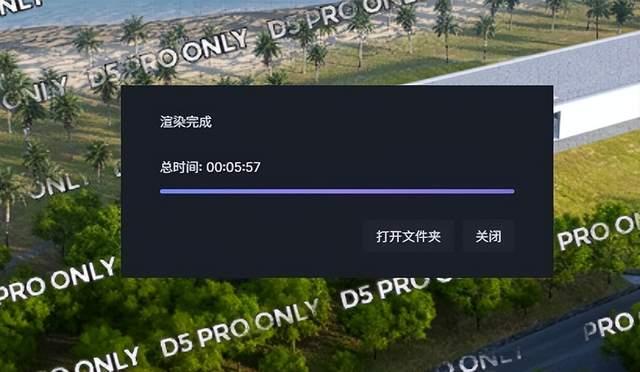
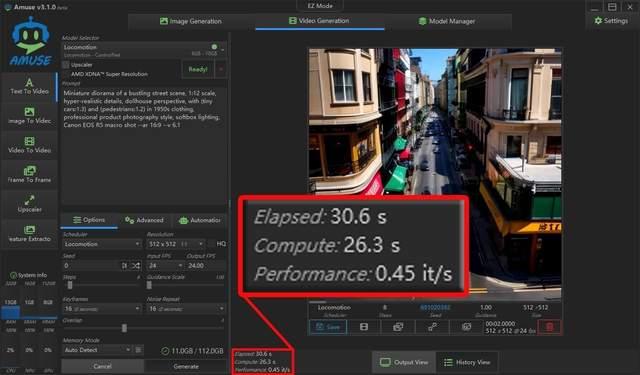
另外我们还使用locomotion模型体验了文生视频,耗时30.6秒钟完成了下面gif图所示的一段视频素材,整体效果说实话还是相当让人满意的。

最后我们通过lm studio部署了七款不同参数规模的常用大语言模型,以下gif图为1倍速录制,运行的大模型是openai旗下的gpt-oss-120b,大约45 token/s左右的生成速度,非常快,足够满足用户的本地化ai助手应用需求了。由于是本地化部署,自然没有网络延迟,也不用付费购买tokens流量,还不用担心数据隐私泄露的问题。
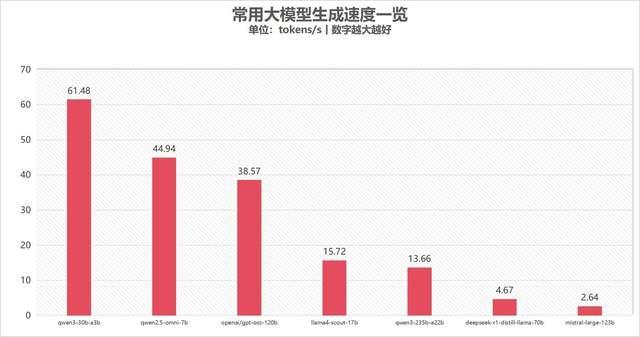
另外我们还统计了七款大模型的生成速度,qwen3-30b-a3b混合专家模型生成速度达到了61.48tokens/s,接下来是qwen2.5-omni-7b和openai/gpt-oss-120b,生成速度分别为44.94 tokens/s和38.57 tokens/s;llama4-scout-17b和qwen3-235b-a22b生成速度分别为15.72 tokens/s和13.66 tokens/s,也能很好地满足日常应用需求。要知道受限于单卡显存,常见顶级独显也都只有24或32gb显卡,是很难部署和流畅运行这类超大参数的大模型的,而锐龙ai ma×+ pro 395平台不仅能顺利部署和加载,甚至真正能够跑得动、跑得快。
评测总结
惠普迷你pc一直以来都给人以非常踏实和可靠的感觉,出色的稳定性、可靠性以及性能表现,让不少企业级用户、专业用户从中受益。在ai时代到来之后,amd推出的锐龙ai ma×+ pro 395平台可谓是技惊四座,它与惠普z2 mini g1a ai图形工作站的强强联手,可以说是给想要研究ai、学习ai、实用ai的企业用户、开发者和个人用户提供了相当靠谱的硬件平台,用户无需花费数万甚至数十万元去购买ai一体机,只需要一台搭载锐龙ai ma×+ pro 395的惠普z2 mini g1a,两万左右的价格即可解决普通的ai算力部署需求。

amd也在联合诸多ai解决方案生态伙伴,用mini ai工作站这一新形态产品赋能千行百业的ai建设和转型的最后一公里,让ai真正为每个人/每个家庭/每个组织拓展能力边界,升级生产力,成就业务创新。
此外,锐龙ai ma×+ pro 395的优势不仅仅只局限于ai,通过测试可以看到,这一平台有着极大的内存容量,出色的图形性能,优异的异构计算性能,因此在应对科学计算、视频剪辑、图片处理、3d渲染、工业设计、金融分析等不同领域和类型的应用时,都能够提供足够出色的性能支持。因此对目前整体预算紧张,要求更高投入产出比的企业采购需求来说,这种一机多用的设备相比单一的ai私有化算力设备来说,具有更高的回报价值。



发表评论