1. 引言
在数据处理、内容提取、网页归档等任务中,经常需要将 html 转换为纯文本 txt。常见需求包括去除 html 标签,保留文本内容,保留段落、列表等基本结构。
本文将介绍如何用 python 和 free spire.doc 库完成 html 到 txt 的转换。
2. 转换原理
html 转 txt 的本质是解析 html 文档对象模型(dom),提取其中的文本节点,再按需要的格式输出。
常用方法有两类:
- 纯解析器(如
beautifulsoup、lxml):快速、轻量,但需要自己处理换行和缩进。 - 文档模型类库(如 free spire.doc):加载 html 到文档对象,再导出为 txt,结构保留更好。
3. 环境准备
安装 free spire.doc for python:
pip install spire.doc.free
注意点击查看免费版的限制
4. 基本实现
4.1 html 文件 → txt 文件
下面是一个将 html 文件转换为 txt 文本的简单示例:
from spire.doc import *
from spire.doc.common import *
# 加载html文件
document = document()
document.loadfromfile("e:\input.html", fileformat.html, xhtmlvalidationtype.none)
# 另存为txt文件
document.savetofile("html文件转txt.txt", fileformat.txt)
document.close()
核心代码:
loadfromfile():加载 html 文件。fileformat.html表示文件格式为 html。savetofile():将文档保存为 txt 格式。fileformat.txt表示保存为纯文本。
输出结果:
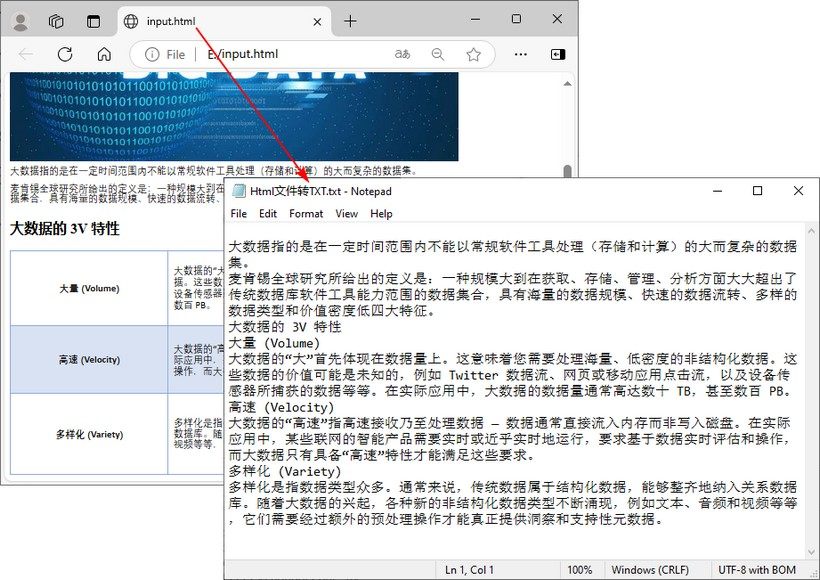
4.2 html 字符串 → txt 文件
若 html 内容已在内存中(如接口返回、爬虫抓取结果),可使用该方法:
from spire.doc import *
from spire.doc.common import *
# 指定html字符串
sample_html = """
<html>
<head><title>示例页面</title></head>
<body>
<h1>欢迎来到我的网站</h1>
<p>这是一个段落文本。</p>
<ul>
<li>项目1</li>
<li>项目2</li>
<li>项目3</li>
</ul>
</body>
</html>
"""
# 创建文档
document = document()
# 在段落中插入字符串
section = document.addsection()
section.addparagraph().appendhtml(sample_html)
# 另存为txt
document.savetofile("html字符串转txt.txt", fileformat.txt)
document.close()
输出结果:
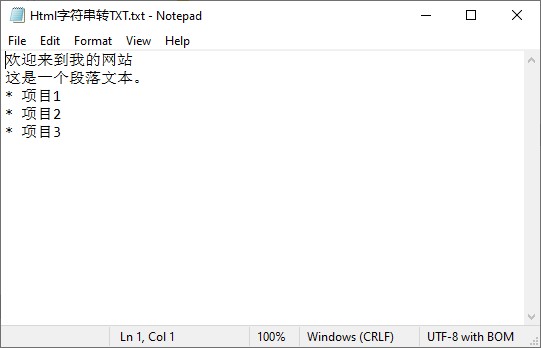
5. 注意事项
- 格式保留:转换后的 txt 会保留 html 的段落结构(换行、列表等),但不保留颜色、字体等样式。
- 性能:对于超大型 html 文件,建议分段处理以避免内存占用过高。
- 复杂 html:对于包含大量 javascript、css 或复杂布局的 html,建议先用对文件进行预处理再转换。
使用 free spire.doc for python 转换 html 到 txt 非常方便,只需几行代码即可完成,并且能够较好地保留原有的文本结构。相比正则表达式或简单的标签剥离方法,这种方式更稳定可靠。
到此这篇关于python实现html文件或字符串转换为纯文本txt的文章就介绍到这了,更多相关python html转txt内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论