前言
在日常的数据库运维或系统迁移过程中,我们经常会遇到这样的问题:
数据库和表的字符集不统一,或者需要统一升级到更合适的字符集(例如 utf8mb4)以支持更多字符。
手动逐个表、逐个字段修改字符集不仅耗时,还容易遗漏。本文将通过一段 sql 脚本,向大家介绍如何批量替换 mysql 数据库的字符集,从而简化操作并降低风险。
为什么要批量修改字符集?
- 统一性:确保所有表和字段的字符集一致,避免查询或插入时出现乱码。
- 兼容性:例如
utf8在 mysql 实际上只支持最多 3 字节,而utf8mb4才是真正的 utf-8,可以支持 emoji 等四字节字符。 - 可维护性:统一的标准字符集让团队协作和后期维护更加方便。
整体脚本
-- 替换为你的数据库名
set @db_name = '你的数据库名';
set @charset = 'utf8mb4';
set @collation = 'utf8mb4_unicode_520_ci';
-- 生成修改表默认字符集的语句
select concat(
'alter table `', table_name, '` default character set ', @charset, ' collate ', @collation, ';'
) as alter_table_sql
from information_schema.tables
where table_schema = @db_name
and table_type = 'base table'; -- 只处理用户表,排除视图等
-- 生成修改所有字符串字段的语句
select concat(
'alter table `', c.table_name, '` modify column `', c.column_name, '` ',
c.data_type,
if(c.character_maximum_length is not null, concat('(', c.character_maximum_length, ')'), ''),
' character set ', @charset, ' collate ', @collation,
if(c.is_nullable = 'no', ' not null', ' null'),
if(c.column_default is not null, concat(' default ', quote(c.column_default)), ''),
' comment ', quote(c.column_comment), ';'
) as alter_column_sql
from information_schema.columns c
join information_schema.tables t on c.table_name = t.table_name and c.table_schema = t.table_schema
where c.table_schema = @db_name
and t.table_type = 'base table'
and c.data_type in ('varchar', 'char', 'text', 'tinytext', 'mediumtext', 'longtext') -- 所有字符串类型
and (c.character_set_name is null or c.character_set_name != @charset or c.collation_name != @collation);
脚本逻辑解析
以下脚本分为两部分,分别用于生成修改 表的默认字符集 和 字段字符集 的 sql 语句。
1. 设置目标参数
-- 替换为你的数据库名 set @db_name = '你的数据库名'; set @charset = 'utf8mb4'; set @collation = 'utf8mb4_unicode_520_ci';
@db_name:要操作的数据库名。@charset:目标字符集。这里我们指定为utf8mb4。@collation:排序规则,推荐使用utf8mb4_unicode_520_ci,兼容性和排序效果更好。
2. 生成修改表默认字符集的语句
select concat(
'alter table `', table_name, '` default character set ', @charset, ' collate ', @collation, ';'
) as alter_table_sql
from information_schema.tables
where table_schema = @db_name
and table_type = 'base table'; -- 只处理用户表,排除视图等
这段 sql 会从 information_schema.tables 中读取所有用户表,并生成相应的 alter table 语句。
作用是修改表的默认字符集和排序规则,这样以后新建字段时会自动使用指定的字符集。
3. 生成修改所有字符串字段的语句
select concat(
'alter table `', c.table_name, '` modify column `', c.column_name, '` ',
c.data_type,
if(c.character_maximum_length is not null, concat('(', c.character_maximum_length, ')'), ''),
' character set ', @charset, ' collate ', @collation,
if(c.is_nullable = 'no', ' not null', ' null'),
if(c.column_default is not null, concat(' default ', quote(c.column_default)), ''),
' comment ', quote(c.column_comment), ';'
) as alter_column_sql
from information_schema.columns c
join information_schema.tables t on c.table_name = t.table_name and c.table_schema = t.table_schema
where c.table_schema = @db_name
and t.table_type = 'base table'
and c.data_type in ('varchar', 'char', 'text', 'tinytext', 'mediumtext', 'longtext') -- 所有字符串类型
and (c.character_set_name is null or c.character_set_name != @charset or c.collation_name != @collation);
这段 sql 主要针对已有的字符串字段,逐一生成 alter table ... modify column 语句:
- 只选择了 字符串类型字段(
varchar,char,text等)。 - 保留了原有的字段长度(
character_maximum_length)。 - 保留了字段是否可为空(
is_nullable)。 - 保留了默认值(
column_default)。 - 保留了字段注释(
column_comment)。 - 仅在字段字符集或排序规则与目标不一致时才生成语句,避免重复修改。
使用步骤
替换数据库名
将脚本中的set @db_name = '你的数据库名';修改为实际要操作的数据库名。执行脚本
在 mysql 客户端或工具(如 navicat、dbeaver)中运行以上 sql。复制结果并执行
脚本本身不会直接修改数据库,而是生成一批 alter 语句。
你需要将结果导出或复制出来,再次执行这些alter语句,才能真正完成修改。
示例输出
假设数据库 test_db 有一张 users 表,里面有一个 name 字段:
执行脚本后可能会生成如下语句:
alter table `users` default character set utf8mb4 collate utf8mb4_unicode_520_ci; alter table `users` modify column `name` varchar(255) character set utf8mb4 collate utf8mb4_unicode_520_ci not null comment '用户名';
结果1替换表的字符集,结果2替换字段的字符集
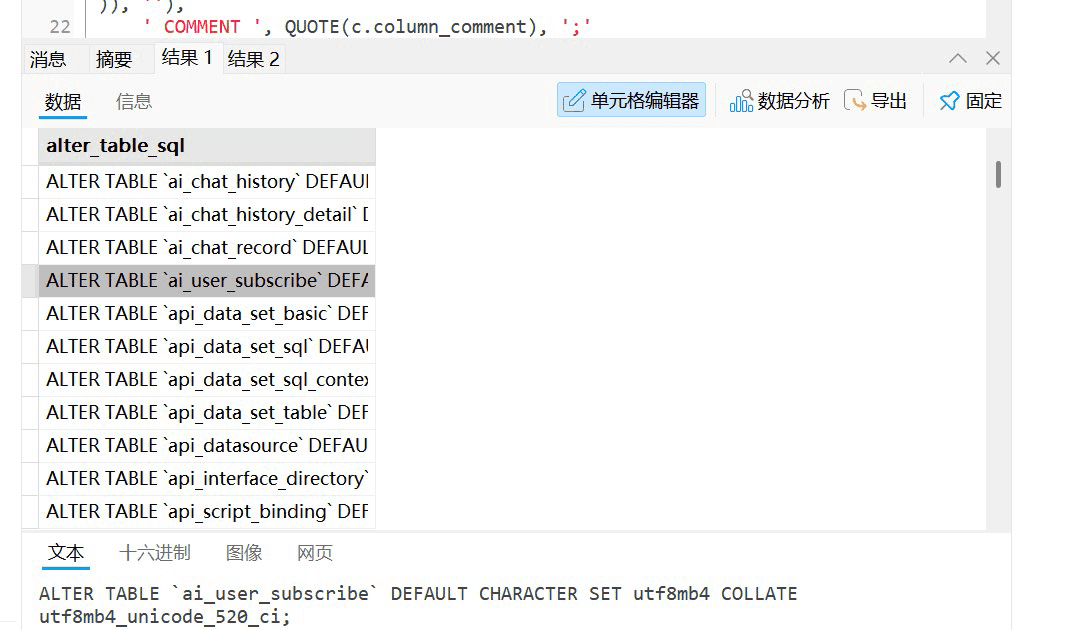
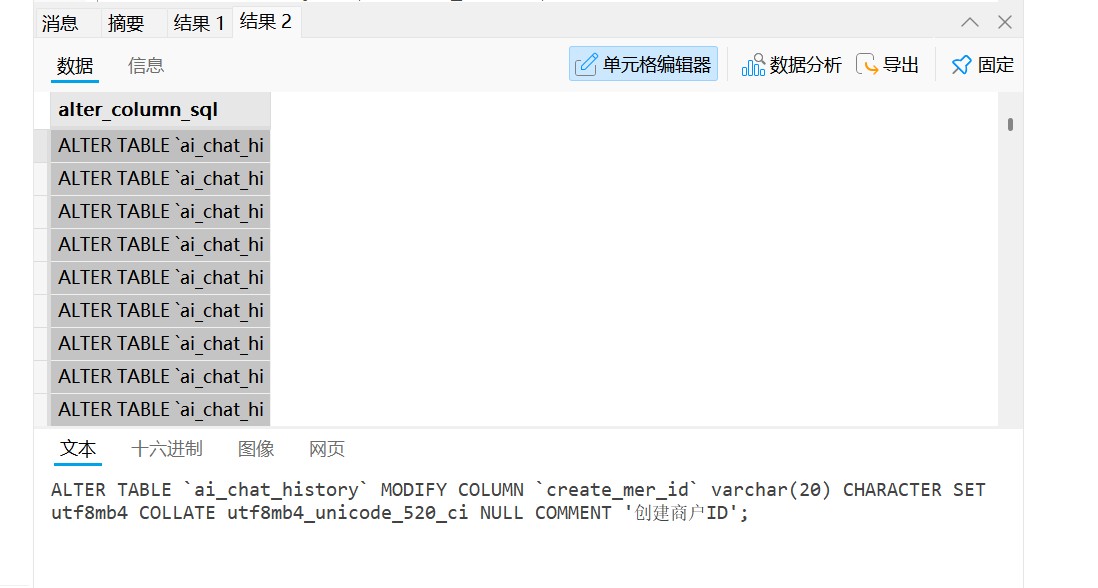
注意事项
- 备份数据:在批量修改前,一定要做好数据库备份,以防万一。
- 锁表风险:
alter table会对表加锁,大表执行时可能会阻塞业务,建议在业务低峰期操作。 - 兼容性验证:部分排序规则在 mysql 版本之间可能有所差异,请确认目标环境支持。
总结
到此这篇关于mysql批量替换数据库字符集的实用方法的文章就介绍到这了,更多相关mysql批量替换数据库字符集内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论