可能有朋友会问为啥不用至强w9-3595x来对比?原因其实很简单,因为哪怕是“最新”的至强w9-3595x,使用的也依然是脱胎自12代酷睿的goldencove架构,在技术上落后intel自家的服务器端至强足足两代,落后普通消费端酷睿更是达到了三代之多,可见intel至少目前来说,对于hedt市场的诚意严重不足,压根就不值得拿来“对比”。
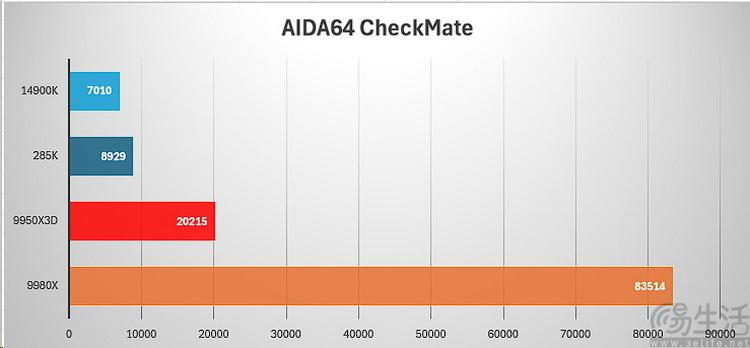
接下来,我们使用aida64测试了checkmate和photoworxx两个项目。前者主要反映cpu内部的指令命中率,体现的是指令预取和缓存效率。很显然,对于如今有着高带宽内部总线和超大缓存的amd zen5架构来说,这本就是它们的“主场”。但线程撕裂者9980x能在这个项目中,跑出比16核还带v-cache的9980x3d高出3倍以上的成绩,从某种程度上其实也反映出,8ccd的线程撕裂者的内部核间延迟表现相当“够用”。
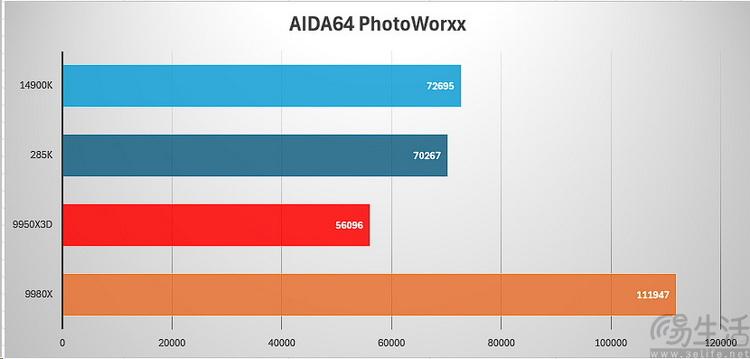
相比之下,photoworxx这个项目看似是考验cpu的avx浮点指令集性能,但实际上从我们以往的经验来看,它反而是更“吃”内存带宽胜过cpu核心数。所以这也是为何14900k在这个项目中得分会非常高的原因(因为它的内存控制器直连cpu,而9950x3d和285k的内存控制器都在io die上,与cpu之间会有更高延迟)。但很显然,在线程撕裂者“暴力”的四通道ddr5-6400面前,一切都成了浮云。
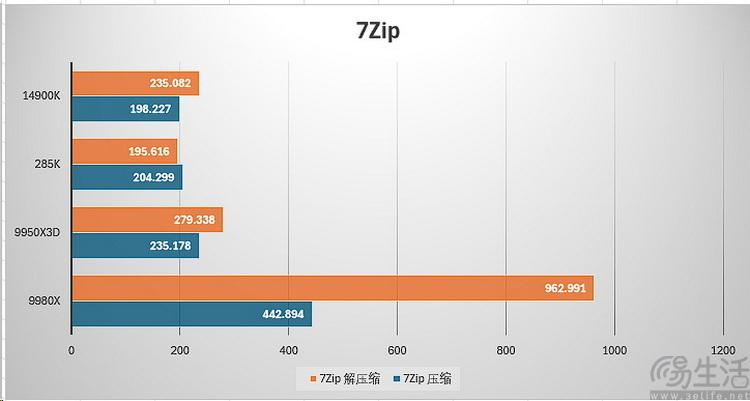
在7zip的测试中,线程撕裂者9980x继续无敌,它的压缩性能比其他高端家用cpu快一倍,解压缩速度更是达到了三倍甚至更多。大家不妨想象一下,同样一个巨大的压缩包,线程撕裂者9980x解压用20分钟,换成普通的“高端u”可能就要1个小时。这样的差距,难道还不够大吗?
内存测试:384gb、四通道,速度和容量全满足
接下来,我们来看看江波龙ddr5 rdimm内存套装在这套平台上的表现。
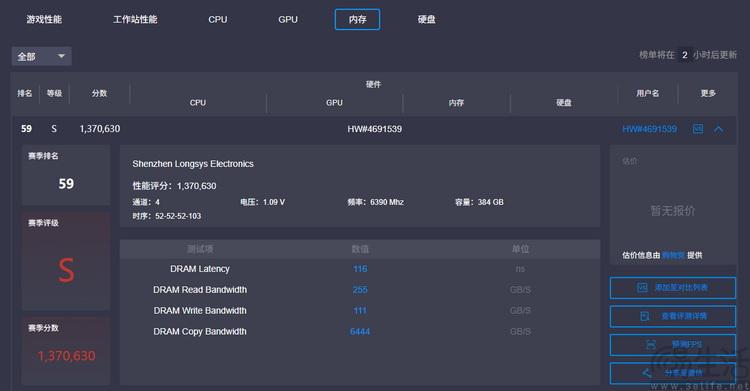
相信很多朋友最关注的一个问题,是四通道的内存到底能比常见的双通道快多少?从相关软件的测试结果来看,搭配线程撕裂者9980x后,这套江波龙的rdimm内存在读取带宽上高达255gb/s,确实达到了双通道内存方案的两倍。而它的写入带宽则与常见的双通道平台差别不大,116ns的延迟水准,与常见的非超频内存也没什么区别。
但对于四通道、高达384gb的内存配置来说,考虑到线程撕裂者平台的“常见用途”,我们首先要考察、关于内存的第一个问题,还是它究竟能不能保证高负载下的持续稳定性。
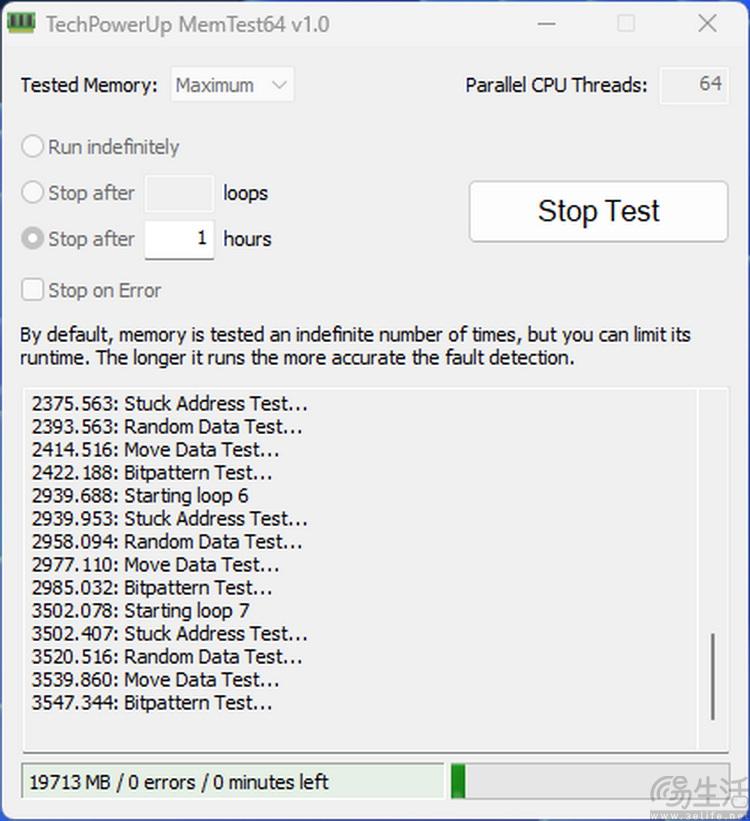
为此,我们用memtest进行了64线程、长达1小时的内存满载稳定性测试,它会不断填满内存里的全部地址,并反复进行。对于常见的家用电脑来说,能够保证半小时不报错,通常就可以认为足以应对日常使用的稳定性需求了。而我们手头这套线程撕裂者9980x搭配江波龙ddr5 rdimm内存套装,在运行1小时的内存压力测试后,没有出现一次报错的现象。


同时从热像仪里来看,由于使用了高密度的颗粒排布,再加上ddr5内存本身自带pmic供电,这导致江波龙的这套rdimm内存在持续高负载情况下,自身的温度并不算低。在我们使用的开放平台里,它的表面温度可以接近60摄氏度。当然,这个温度对于企业级内存来说确实也不算什么。况且在有风道的工作站或发烧级台式机箱里,内存的散热情况也会更好一些。
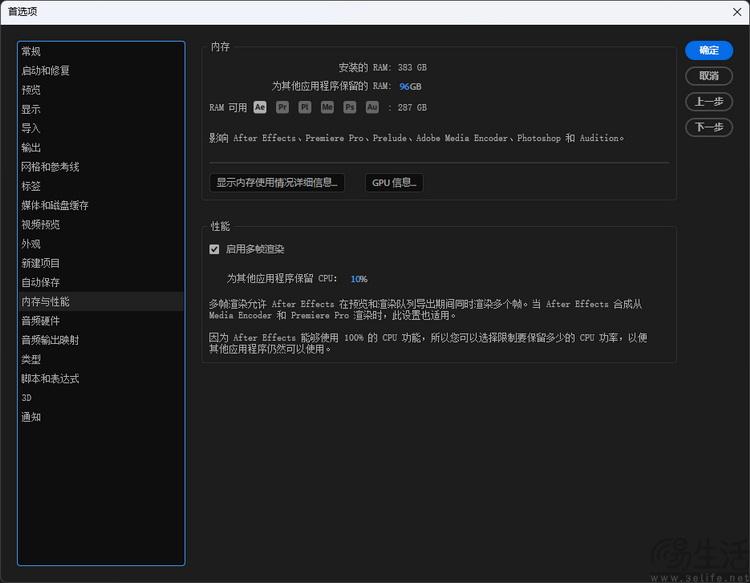
有的朋友可能会问,这么大内存有啥用呢?很简单,因为有些软件对于内存的“渴望”是多多益善的。
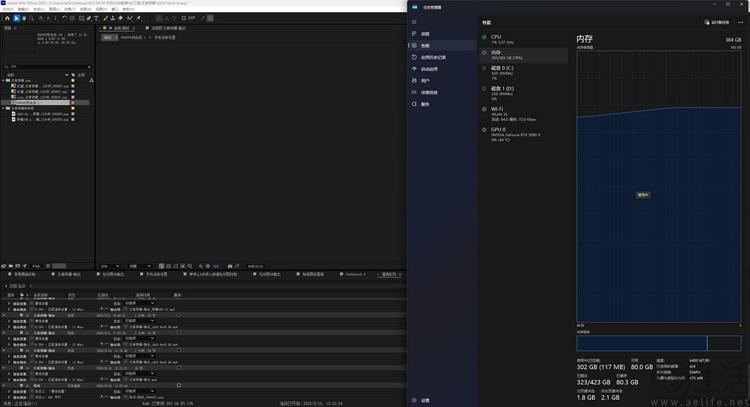
比如,这个一打开就直接“吃掉”300gb内存的ae。
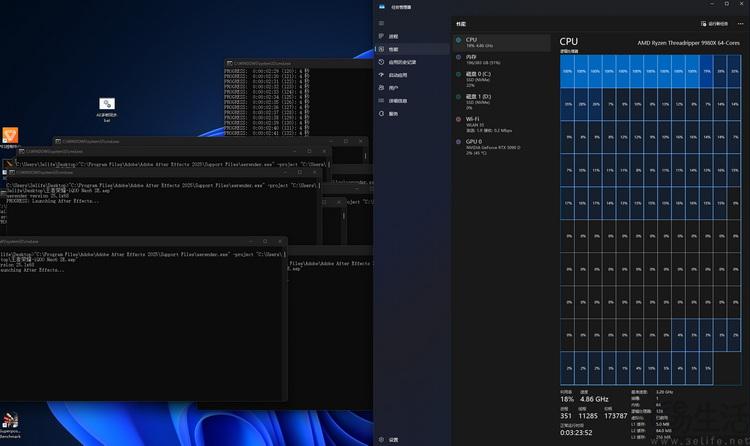
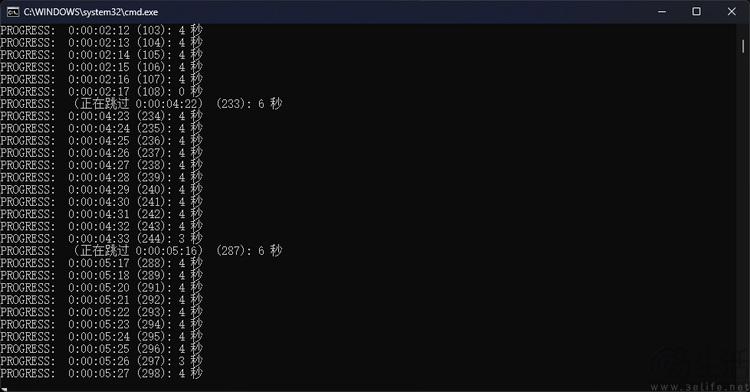
又比如说,我们还尝试使用自动脚本让ae强行进行8k视频的多线程渲染。可以看到,此时cpu核心“只不过”吃满了10个核而已,但内存需求已接近200gb。换句话说,如果换成只有32gb、64gb内存的“普通高端家用平台”,还真做不了这件事。
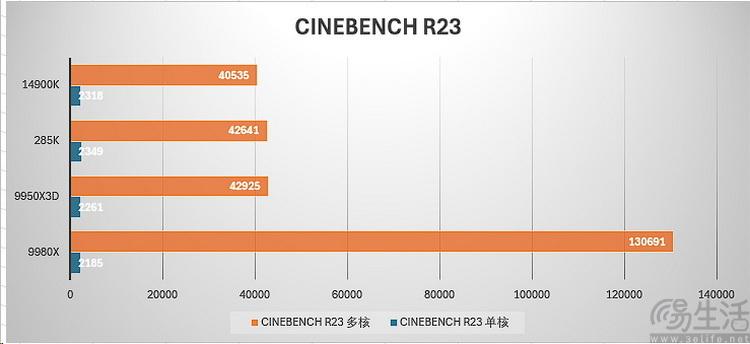
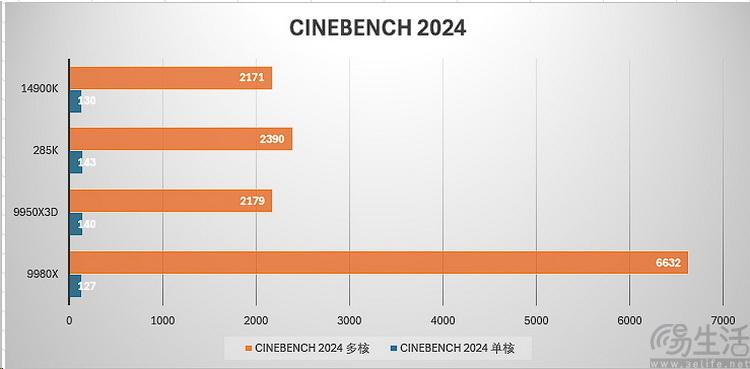
生产力测试:大模型性能秒杀显卡,64核胜过前代96核
我们相信大多数对于线程撕裂者平台(不管x还是wx)感兴趣的朋友,都和我们一样,主要是想知道它究竟能带来多高的生产力、或者说拿来“赚钱”到底有多厉害。
发表评论