一、正常记录链表
记录的头信息中的next_record属性组成一个单向链表,我们把这个链表称为正常记录链表。
二、垃圾链表
被删除的记录其实也会根据记录头信息中的next_record属性组成一个链表,只不过这个链表中的记录所占用的存储空间可以被重新利用,所以也称这个链表为垃圾链表。
三、page_free的作用
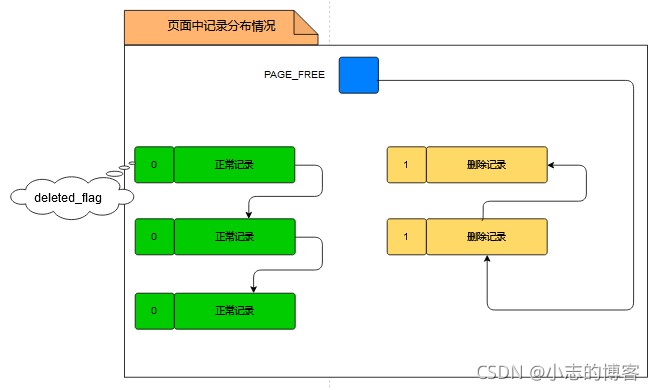
page header部分中有一个名为page_free的属性,它指向由被删除记录组成的垃圾链表中的头节点。每删除一条记录,则该记录都会插入到垃圾链表的头节点处。
示例:有3条正常记录和2条被删除记录,他们在页中的记录分布情况如下图所示:
注:在垃圾链表中,这些记录占用的存储空间可以被重新利用。
四、删除一条记录的步骤
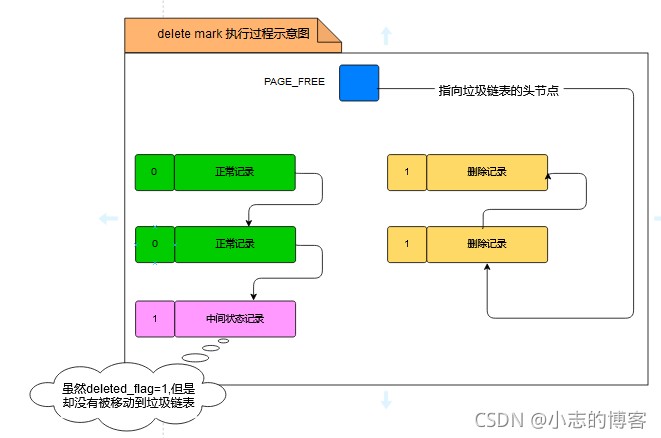
delete mark阶段
仅仅将记录的deleted_flag标识位设置为1,但是这条记录并没有加入到垃圾链表中。
也就是说,这条记录即不是正常记录,也不是已删除记录。
在删除语句所在的事务提交之前,被删除的记录一直都处于这种中间状态(其实主要是为了实现mvcc的功能才这样处理的)。
- 如下图所示:
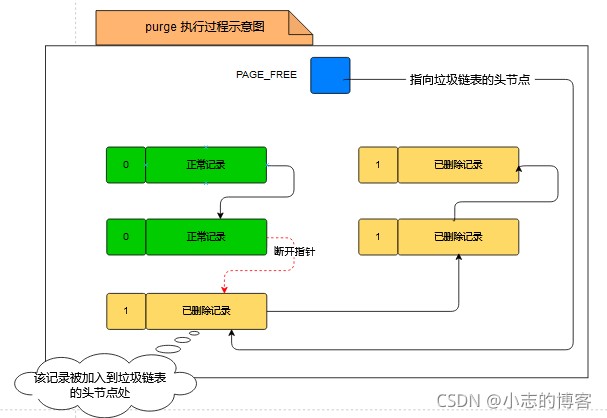
purge阶段
当该删除语句所在的事务提交后,会有专门的线程来把该记录从正常记录链表中移除,并加入到垃圾链表中作为头节点。
- 如下图所示:
五、关于垃圾链的重用空间的知识点了解
1、page_garbage是做什么的
page header部分有一个名为page_garbage的属性。该属性记录着当前页面中可重用存储空间占用的总字节数。
每当有已删除记录加入到垃圾链表后,都会把这个page_garbage属性的值加上已删除记录占用的存储空间大小。
2、如何重用垃圾链表的存储空间
- page_free指向垃圾链表的头节点,每当新插入数据的时候:
- 首先:判断垃圾链表头节点记录的存储空间是否足够容纳这条新插入的记录。如果可以容纳则直接重用这条已删除记录的存储空间。
- 其次:如果不能容纳,则直接向页面申请新的空间来存储这条记录。(是的,你没看错!并不会尝试遍历垃圾链表,以找到可以容纳新记录的节点)
3、如果新插入的那条记录记录小于重用的记录空间,那么会有一部分空间用不到,怎么处理?是否可以直接浪费掉?
这种情况会频繁发生,也就会随着记录越插越多而产生越来越多的空间碎片。只有当页面块满的时候,如果再插入一条新记录,无法分配一条完整的记录空间时,会先查看page_garbage的空间和剩余空间相加是否可以容纳这条新的记录,如果可以,innodb则会尝试重新组织页内的记录。即:先开辟一个临时页面,把原页面内的记录依次挨着插入一遍到临时页,之后,再把临时页的内容复制到本页面,这样就可以把那些碎片空间都释放出来了。但是该操作比较耗费性能。
由于一旦事务提交,我们也就不需要再回滚这个事务了,所以在设计undo日志时,只需要考虑delete mark这个阶段所做的影响进行回滚就可以了。
- trx_undo_del_mark_rec类型的undo日志结构如下图所示:

上图解释:
info bits:记录头信息的前4个比特的值。trx_id:旧记录的trx_id值。roll_pointer:旧记录的roll_pointer值。len of index_col_info:也就是下边的【索引列各列信息】部分和本部分占用的存储空间总和。- 索引列各列信息
<pos, len, value>列表:凡是被索引的列的各列信息。
4、什么trx_undo_del_mark_rec类型的undo日志保存旧记录的trx_id值和roll_pointer值
保存旧记录的trx_id值——为了采用事务id作为版本号,记录每个undo日志所对应的版本是多少。
保存旧记录的roll_pointer值——可以通过undo日志的roll_pointer属性找到上一次对该记录进行改动时产生的undo日志,因此可以将日志串成链表。这个链表就是版本链。
- 示例:新增一条记录,然后再删除这条记录的完整操作过程,如下所示:
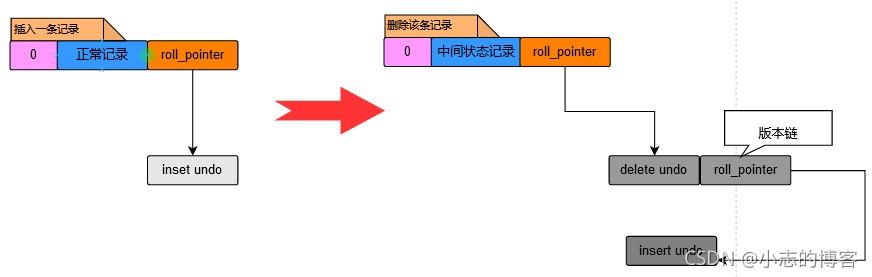
六、删除操作生成undo日志的示例
1、 先插入两条记录
begin; # 显示开启一个事务,假设该事务的事务id为100 # 插入两条记录 insert into sys_user(id, name, city) values(1, 'xz','北京市'), (2, 'tom','天津市'); # 删除一条记录 delete from sys_user where id = 1;

2、上图字段说明
(1)、索引列各列信息 <pos, len, value>列表<0, 4, 1>:
- 由于id列是主键,所以pos=0;
- 由于id列的类型是int,所以len=4;
- 由于id=1,所以value=1;
(2)、索引列各列信息 <pos, len, value>列表<3, 4, ‘xz’>:
- 由于name列是二级索引,它排在id列、trx_id列、roll_pointer列之后,所以pos=3;
- 由于id列的类型是int,所以len=4;
- 由于name=‘xz’,所以value=‘xz’;
(3)、len of index_col_info
- pos使用1字节来存储。
- len使用1字节来存储。
- value根据具体值,来判断。比如:id=1,主键是int占4个字节,所以value使用4字节存储。name=‘xz’,varchar类型,所以value用4字节存储。
- len of index_col_info本身占2个字节。
(4)、综上所述,<0, 4, 1><3, 4, ‘xz’>占用空间等于:(1+1+4)+(1+1+4) =12,如下图所示:
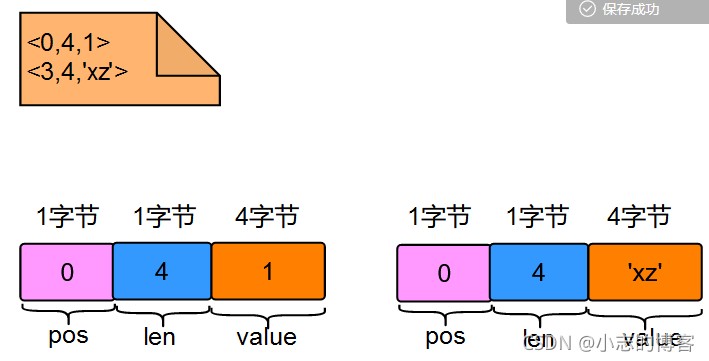
(5)、最后,再加上len of index_col_info属性本身占2个字节,所以总共14字节。即:len of index_col_info=14。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论