引言:数据洪流时代的生存法则
当每秒百万级的交易数据席卷而来,当用户行为轨迹以毫秒级刷新,传统批处理架构在实时性悬崖边摇摇欲坠。某电商巨头曾因延迟10分钟的风险拦截,单日损失超$2m——实时数据流处理已成为数字企业的生死线。
本文将深入解剖基于python的实时处理黄金组合:kafka(分布式消息队列) 与 pyspark(分布式计算引擎) 的化学反应。通过工业级代码示例与底层原理解析,构建坚如磐石的处理流水线。
验证题目:请说明传统批处理架构在实时场景中的三大缺陷
答案:1. 高延迟(分钟级至小时级)2. 资源利用率波动大 3. 无法响应动态事件
实时数据处理的核心价值:
- 快速响应:实时处理用户行为数据,快速做出决策。
- 提升用户体验:根据用户的实时行为,提供个性化服务。
- 优化业务流程:通过实时数据分析,优化业务流程和资源配置。
第一章 kafka:数据世界的中央神经系统
消息引擎核心设计哲学
kafka采用发布-订阅模式解耦生产消费,其分布式提交日志架构使数据持久化能力突破传统mq瓶颈。核心组件:
producer:数据发射器(如用户行为采集sdk)
consumer:数据处理器(如spark消费集群)
broker:消息存储节点集群
topic:逻辑数据通道(如order_events)
# 导入kafka生产者模块
from confluent_kafka import producer
# 导入json处理模块(原代码缺失此导入)
import json
# 配置kafka集群连接参数(多个broker用逗号分隔)
conf = {'bootstrap.servers': 'kafka1:9092,kafka2:9092'}
# 创建kafka生产者实例
producer = producer(conf)
# 定义消息投递结果回调函数
def delivery_report(err, msg):
"""处理消息发送后的回调结果"""
# 如果发送失败则打印错误
if err is not none:
print(f'message delivery failed: {err}')
# 发送成功时打印消息元数据
else:
print(f'message delivered to: '
f'topic={msg.topic()} '
f'partition={msg.partition()} '
f'offset={msg.offset()}')
# 构造用户事件数据(python字典格式)
user_event = {
'user_id': 101,
'action': 'payment',
'amount': 299.9
}
# 使用生产者发送消息到指定主题
producer.produce(
topic='user_events', # 目标kafka主题名称
key=str(user_event['user_id']), # 设置消息键(按用户id分区)
value=json.dumps(user_event), # 将字典转为json字符串
callback=delivery_report # 指定投递结果回调函数
)
# 可选:在发送后立即轮询事件队列(处理回调)
# 确保在flush前处理已发送消息的回调
producer.poll(0)
# 强制刷新生产者缓冲区,确保所有消息完成传输
# 会阻塞直到所有消息得到broker确认或超时
producer.flush()
# 注意:实际生产环境通常不会每条消息都flush
# 可考虑批量发送或定时刷新以提高吞吐量高吞吐背后的工程魔法
kafka实现百万级tps的核心技术:
- 分区并行化:topic拆分为多个partition分散存储压力
- 零拷贝技术:通过sendfile系统调用绕过内核缓冲区
- 批量压缩:snappy压缩算法降低网络io达70%
- isr副本机制:in-sync replicas保障数据高可用
验证题目:若某topic配置3分区2副本,集群最少需要几台broker?
答案:2台(副本不能全部位于同一broker)
第二章 pyspark:分布式计算的终极形态
pyspark的核心功能
pyspark是spark的python api,支持使用python进行大规模数据处理。其核心功能包括:
- 弹性分布式数据集(rdd):分布式的数据集合,支持并行操作。
- dataframe和dataset:结构化的数据处理api,支持高效的数据操作。
- 流处理:通过structured streaming进行实时数据处理。
弹性分布式数据集(rdd)革命
spark核心抽象rdd(resilient distributed dataset) 具备:
- 不可变性:每次操作生成新rdd(函数式编程范式)
- 血缘关系:lineage机制实现故障重算(非数据复制)
- 延迟计算:action触发dag执行计划优化
# 导入必要的pyspark模块
from pyspark import sparkconf, sparkcontext
# 初始化spark配置(实际应用中可配置集群参数)
conf = sparkconf().setappname("wordcount") # 设置应用名称
sc = sparkcontext(conf=conf) # 创建sparkcontext实例
# 从hdfs分布式文件系统加载文本数据创建初始rdd
# 参数:hdfs文件路径(假设为访问日志)
text_rdd = sc.textfile("hdfs://logs/access.log") # 返回rdd[string]类型
# ===== 转换操作(transformations)=====
# 惰性操作:仅定义计算逻辑,不立即执行
# 扁平化操作:将每行文本分割成单词
# flatmap: 每行输入 -> 多个输出元素(单词)
words_rdd = text_rdd.flatmap(lambda line: line.split(" "))
# 映射操作:将每个单词转换为(单词, 1)键值对
# map: 每个单词 -> (word, 1) 二元组
pairs_rdd = words_rdd.map(lambda word: (word, 1))
# 按键聚合:对相同单词的计数值进行累加
# reducebykey: 对相同key的值执行聚合函数(这里是加法)
counts_rdd = pairs_rdd.reducebykey(lambda a, b: a + b)
# ===== 行动操作(action)=====
# 触发实际计算并返回结果到驱动程序
# 获取词频最高的10个单词(按词频降序)
# takeordered: 返回按指定键排序的前n个元素
# key=lambda x: -x[1]: 按计数值(元组第二项)降序排列
top10 = counts_rdd.takeordered(10, key=lambda x: -x[1])
# 打印结果到控制台
print("top10高频词:", top10)
# 可选:关闭sparkcontext释放资源
# 在长时间运行的spark应用(如spark streaming)中可能不立即关闭
sc.stop()structured streaming:流处理的范式转移
相比传统微批次处理,structured streaming实现:
无限表模型:流数据视为持续增长的表
事件时间处理:基于watermark处理乱序事件
端到端exactly-once:通过检查点+幂等写入保障
# 导入必要的pyspark模块
from pyspark.sql import sparksession
from pyspark.sql.functions import col, from_json, window
from pyspark.sql.types import structtype, structfield, stringtype, integertype, timestamptype, doubletype
# 创建sparksession实例(流处理程序的入口点)
spark = sparksession.builder \
.appname("kafkapaymentmonitor") \ # 设置应用名称
.config("spark.sql.shuffle.partitions", "4") \ # 优化小规模数据处理
.getorcreate() # 获取或创建会话实例
# 定义json事件的结构化模式
# 对应kafka消息中的json格式:{'user_id':101, 'action':'payment', 'amount':299.9, 'timestamp':'2023-01-01t12:00:00z'}
event_schema = structtype([
structfield("user_id", integertype(), true), # 用户id整型字段
structfield("action", stringtype(), true), # 行为类型字符串字段
structfield("amount", doubletype(), true), # 支付金额双精度字段
structfield("timestamp", timestamptype(), true) # 事件时间戳字段(关键用于窗口计算)
])
# ===== 定义kafka流源 =====
# 创建流式dataframe,从kafka持续读取数据
df = spark.readstream \ # 创建流式读取器
.format("kafka") \ # 指定kafka数据源格式
.option("kafka.bootstrap.servers", "kafka1:9092") \ # kafka集群地址
.option("subscribe", "user_events") \ # 订阅的主题名称
.option("startingoffsets", "latest") \ # 从最新偏移量开始(可选:earliest)
.option("failondataloss", "false") \ # 容忍数据丢失(生产环境推荐)
.load() # 加载流数据源
# ===== 数据处理管道 =====
# 步骤1:解析json并过滤支付事件
payments = df.select(
# 解析value字段(二进制转为字符串,再按schema解析为结构化数据)
from_json(col("value").cast("string"), event_schema).alias("data"),
# 保留kafka消息自带的时间戳(可选,通常使用事件时间)
col("timestamp").alias("kafka_timestamp")
).filter("data.action = 'payment'") # 过滤出支付事件
# 步骤2:实时窗口聚合(每5分钟窗口按用户统计支付次数)
windowed_count = payments.groupby(
# 基于事件时间创建5分钟滚动窗口
window(col("data.timestamp"), "5 minutes"), # 使用事件时间字段
col("data.user_id") # 按用户id分组
).count() # 计算每个(窗口,用户)组合的支付次数
# ===== 输出结果 =====
# 创建流式查询,将聚合结果输出到控制台
query = windowed_count.writestream \
.outputmode("complete") \ # 完整输出模式(更新整个结果集)
.format("console") \ # 输出到控制台(生产环境可用kafka/文件系统)
.option("truncate", "false") \ # 显示完整内容(不截断)
.option("numrows", 20) \ # 每次触发显示20行
.trigger(processingtime="1 minute") \ # 每分钟触发一次计算
.start() # 启动流处理作业
# 等待查询终止(实际应用可添加优雅停止逻辑)
query.awaittermination()验证题目:列举spark中三个transformation操作和两个action操作
答案:
transformation: map, filter, reducebykey
action: collect, count
第三章 流处理引擎的深度集成
精准一次消费的工程实现
kafka + spark的exactly-once保障机制:
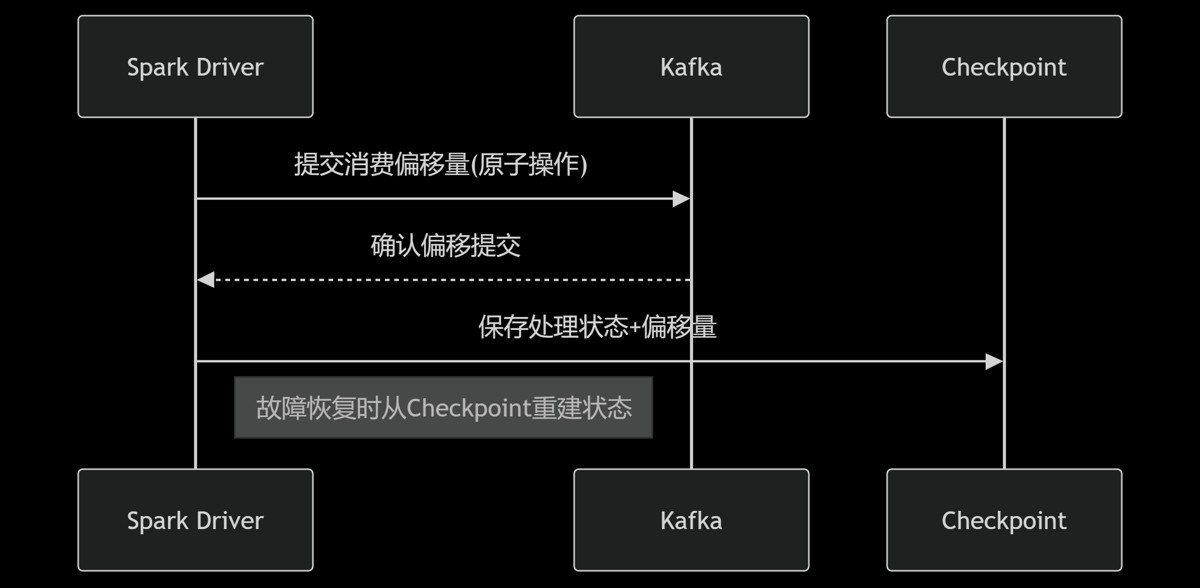
动态负载均衡策略
通过kafka的消费者组协议实现:
分区再均衡(rebalance)自动分配
消费者心跳检测(session.timeout.ms)
偏移量提交(enable.auto.commit=false)
# 导入必要的pyspark模块
from pyspark.sql import sparksession
from pyspark.sql.functions import col, from_json
from pyspark.sql.types import structtype, structfield, stringtype, doubletype, timestamptype
# 创建sparksession实例(流处理程序的入口点)
# 使用builder模式配置并创建spark会话
spark = sparksession.builder \
.appname("kafkaiotstreamprocessor") \ # 设置应用名称
.config("spark.sql.shuffle.partitions", "8") \ # 设置shuffle分区数(根据集群规模调整)
.config("spark.streaming.backpressure.enabled", "true") \ # 启用背压机制(动态调整接收速率)
.getorcreate() # 获取或创建会话实例
# 定义iot设备遥测数据的结构化模式
# 假设json格式:{"device_id": "sensor-001", "temperature": 23.5, "humidity": 45.2, "timestamp": "2023-01-01t12:00:00z"}
iot_schema = structtype([
structfield("device_id", stringtype(), true), # 设备id字符串
structfield("temperature", doubletype(), true), # 温度值(双精度浮点)
structfield("humidity", doubletype(), true), # 湿度值(双精度浮点)
structfield("timestamp", timestamptype(), true) # 数据采集时间戳
])
# ===== 创建kafka流源 =====
# 定义从kafka读取数据的结构化流
stream = spark.readstream \ # 创建流式读取器
.format("kafka") \ # 指定kafka数据源格式
.option("kafka.bootstrap.servers", "kafka1:9092") \ # kafka集群地址(逗号分隔多个broker)
.option("subscribe", "iot_telemetry") \ # 订阅的主题名称(可逗号分隔多个主题)
.option("group.id", "spark-streaming-group") \ # 消费者组id(用于偏移量管理)
.option("startingoffsets", "earliest") \ # 从最早偏移量开始(可选:latest, 或指定json偏移量)
.option("failondataloss", "false") \ # 容忍数据丢失(kafka主题删除或偏移量超出范围时不失败)
.option("maxoffsetspertrigger", 10000) \ # 每批处理的最大消息数(控制批处理大小)
.option("kafka.security.protocol", "sasl_ssl") \ # 安全协议(生产环境需要)
.option("kafka.sasl.mechanism", "plain") \ # sasl机制(生产环境需要)
.load() # 加载流数据源
# ===== 数据处理管道 =====
# 解析json数据并转换为结构化格式
parsed_data = stream.select(
col("key").cast("string").alias("device_key"), # 可选:转换消息键
from_json(col("value").cast("string"), iot_schema).alias("data"), # 解析json值
col("topic").alias("kafka_topic"), # 原始kafka主题
col("partition").alias("kafka_partition"), # kafka分区
col("offset").alias("kafka_offset"), # 消息偏移量
col("timestamp").alias("kafka_timestamp") # kafka消息时间戳
).select("device_key", "data.*", "kafka_topic", "kafka_partition", "kafka_offset", "kafka_timestamp") # 展平嵌套结构
# 过滤异常值(示例:温度在合理范围内)
filtered_data = parsed_data.filter(
(col("temperature") >= -40) &
(col("temperature") <= 100) &
(col("humidity") >= 0) &
(col("humidity") <= 100)
)
# ===== 输出结果 =====
# 创建流式查询,将处理后的数据写入控制台(用于调试)
# 生产环境通常会写入其他系统(如hdfs、kafka、数据库等)
query = filtered_data.writestream \
.outputmode("append") \ # 追加模式(只输出新数据)
.format("console") \ # 输出到控制台(开发/调试用)
.option("truncate", "false") \ # 显示完整内容(不截断)
.option("numrows", 100) \ # 每次触发显示100行
.trigger(processingtime="30 seconds") \ # 每30秒触发一次微批处理
.option("checkpointlocation", "/checkpoints/iot_stream") \ # 检查点目录(保证容错性)
.start() # 启动流处理作业
# 等待流查询终止(通常持续运行直到手动停止)
# 实际应用中可添加优雅停止逻辑(如响应终止信号)
query.awaittermination()
# 可选:在程序退出时停止spark会话
spark.stop()验证题目:如何避免spark处理过程中kafka消息重复消费?
答案:1. 手动管理偏移量 2. 启用spark检查点 3. 下游写入幂等操作
第四章 实战:实时风控系统构建
架构拓扑

异常行为检测模型
# 导入必要的pyspark模块
from pyspark.sql import sparksession
from pyspark.sql.functions import expr, window, count, col
from pyspark.sql.types import structtype, structfield, stringtype, timestamptype, integertype
# 创建sparksession实例(流处理程序的入口点)
spark = sparksession.builder \
.appname("realtimeriskengine") \ # 设置应用名称
.config("spark.sql.shuffle.partitions", "6") \ # 优化分区数
.getorcreate() # 获取或创建会话实例
# 假设事件数据模式(实际应用中根据业务定义)
event_schema = structtype([
structfield("user_id", stringtype(), true), # 用户id
structfield("event_type", stringtype(), true), # 事件类型(登录、支付等)
structfield("ip_address", stringtype(), true), # ip地址
structfield("device_id", stringtype(), true), # 设备id
structfield("location_city", stringtype(), true), # 城市位置
structfield("event_time", timestamptype(), true) # 事件时间戳
])
# ===== 创建事件流源 =====
# 假设从kafka读取事件数据(实际源可能是kafka、kinesis等)
events_df = spark.readstream \
.format("kafka") \ # 数据源格式
.option("kafka.bootstrap.servers", "kafka-risk:9092") \ # kafka集群
.option("subscribe", "user_events") \ # 订阅主题
.load() \
.select(
from_json(col("value").cast("string"), event_schema).alias("data") # 解析json
).select("data.*") # 展平结构
# 添加水印处理延迟数据(基于事件时间)
events_df = events_df.withwatermark("event_time", "10 minutes")
# ===== 特征工程 =====
# 计算设备变更次数(基于用户会话)
device_change_df = events_df.groupby(
"user_id",
window("event_time", "1 hour") # 1小时滚动窗口
).agg(
count("device_id").alias("device_count"), # 设备使用次数
expr("count(distinct device_id)").alias("distinct_devices") # 不同设备数
).withcolumn(
"device_change",
expr("case when distinct_devices > 1 then 1 else 0 end") # 设备变更标志
)
# 计算城市变更次数(类似设备变更)
city_change_df = events_df.groupby(
"user_id",
window("event_time", "1 hour")
).agg(
expr("count(distinct location_city)").alias("distinct_cities")
).withcolumn(
"city_change",
expr("case when distinct_cities > 1 then 1 else 0 end")
)
# 计算登录次数(1小时内)
login_count_df = events_df.filter("event_type = 'login'") \ # 仅登录事件
.groupby(
"user_id",
window("event_time", "1 hour")
).agg(count("*").alias("login_count"))
# 合并特征数据集
feature_df = device_change_df.join(
city_change_df,
["user_id", "window"],
"left_outer" # 左外连接确保所有用户
).join(
login_count_df,
["user_id", "window"],
"left_outer"
).fillna(0) # 填充空值为0
# ===== 规则引擎 =====
# 定义风险规则集(业务逻辑)
# 格式:条件 -> 风险等级
risk_rules = [
"(device_change = 1 and city_change = 1) -> 'high_risk'", # 规则1:设备+城市同时变更
"(login_count > 5) -> 'medium_risk'", # 规则2:1小时内登录超过5次
# 默认规则(无匹配时)
"1 = 1 -> 'low_risk'" # 默认低风险
]
# 构建case表达式
case_expr = "case "
for rule in risk_rules:
# 分割规则为条件和风险等级
condition, risk_level = rule.split("->")
# 添加到case表达式
case_expr += f"when {condition.strip()} then '{risk_level.strip()}' "
case_expr += "end"
# 应用风险规则引擎
risk_df = feature_df.withcolumn(
"risk_level", # 新增风险等级列
expr(case_expr) # 执行规则引擎
).select( # 选择关键字段
"user_id",
"window.start",
"window.end",
"device_change",
"city_change",
"login_count",
"risk_level"
)
# ===== 输出到风险数据库 =====
# 将风险评估结果写入elasticsearch
risk_query = risk_df.writestream \
.outputmode("update") \ # 更新模式(只输出变更记录)
.format("org.elasticsearch.spark.sql") \ # elasticsearch连接器
.option("es.nodes", "es1:9200,es2:9200") \ # es集群节点
.option("es.resource", "risk_events") \ # es索引/类型(es7+使用索引名)
.option("es.mapping.id", "user_id") \ # 文档id字段(基于用户id)
.option("es.write.operation", "upsert") \ # 更新插入模式
.option("checkpointlocation", "/checkpoints/risk_engine") \ # 检查点目录(容错)
.trigger(processingtime="1 minute") \ # 每分钟触发
.start() # 启动流处理
# 同时输出到控制台用于调试
console_query = risk_df.writestream \
.outputmode("update") \
.format("console") \
.option("truncate", "false") \
.start()
# 等待流处理终止
spark.streams.awaitanytermination()
# 生产环境应添加优雅停止逻辑验证题目:设计一个检测同ip高频注册的spark流处理逻辑
答案:
# 导入必要的pyspark模块
from pyspark.sql import sparksession
from pyspark.sql.functions import window, count, col
from pyspark.sql.types import structtype, structfield, stringtype, timestamptype
# 初始化spark会话(配置反压和检查点)
spark = sparksession.builder \
.appname("ipregistrationfrauddetection") \
.config("spark.sql.shuffle.partitions", "8") \ # 根据集群规模调整
.config("spark.streaming.backpressure.enabled", "true") \ # 启用反压
.config("spark.streaming.kafka.maxrateperpartition", "1000") \ # 每分区最大速率
.getorcreate()
# 定义注册事件的数据结构
registration_schema = structtype([
structfield("user_id", stringtype(), true), # 注册用户id
structfield("ip", stringtype(), true), # 注册ip地址
structfield("device_id", stringtype(), true), # 设备标识
structfield("event_time", timestamptype(), true) # 事件时间(必须时间戳类型)
])
# ===== 数据源配置 =====
# 从kafka读取注册事件流(生产环境配置)
registrations = spark.readstream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092") \
.option("subscribe", "user_registrations") \ # 订阅注册主题
.option("startingoffsets", "latest") \ # 从最新位置开始
.option("failondataloss", "false") \ # 容忍数据丢失
.load() \
.select(
from_json(col("value").cast("string"), registration_schema).alias("data")
).select("data.*") # 提取结构化数据
# 添加水印处理延迟数据(10分钟延迟)
registrations = registrations.withwatermark("event_time", "10 minutes")
# ===== 核心检测逻辑 =====
# 每10分钟窗口统计每个ip的注册次数
ip_registration_counts = registrations.groupby(
window("event_time", "10 minutes"), # 10分钟滚动窗口
"ip" # 按ip分组
).agg(
count("*").alias("registration_count") # 计算注册次数
)
# 过滤出异常ip(10分钟内注册超过20次)
suspicious_ips = ip_registration_counts.filter(
col("registration_count") > 20 # 阈值可根据业务调整
).select(
col("window.start").alias("window_start"), # 窗口开始时间
col("window.end").alias("window_end"), # 窗口结束时间
col("ip"), # 嫌疑ip
col("registration_count") # 注册次数
)
# ===== 输出配置 =====
# 方案1:输出到控制台(调试用)
console_query = suspicious_ips.writestream \
.outputmode("complete") \ # 完整模式(显示所有结果)
.format("console") \
.option("truncate", "false") \
.option("numrows", 100) \
.trigger(processingtime="1 minute") \ # 每分钟触发一次
.start()
# 方案2:输出到elasticsearch(生产环境)
es_query = suspicious_ips.writestream \
.outputmode("complete") \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "es1:9200") \
.option("es.resource", "fraud_ips") \ # 索引名称
.option("es.mapping.id", "ip") \ # 使用ip作为文档id
.option("es.write.operation", "upsert") \
.option("checkpointlocation", "/checkpoints/ip_fraud") \ # 检查点目录
.start()
# 方案3:输出到kafka告警主题(生产环境)
alert_query = suspicious_ips.selectexpr(
"cast(ip as string) as key",
"to_json(struct(*)) as value"
).writestream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka1:9092") \
.option("topic", "fraud_alerts") \
.option("checkpointlocation", "/checkpoints/ip_fraud_kafka") \
.start()
# 等待任意流查询终止
spark.streams.awaitanytermination()
# 生产环境应添加信号捕获和优雅关闭逻辑第五章 性能调优:从百级到百万级的跨越
kafka优化黄金参数
kafka是一个高吞吐量、低延迟的分布式流处理平台。其核心功能包括:
- 生产者(producer):将数据发送到kafka主题(topic)。
- 消费者(consumer):从kafka主题中读取消息。
- 主题(topic):消息的分类目录。
- 分区(partition):主题的逻辑划分,支持并行处理。
# server.properties num.network.threads=16 # 网络线程池 num.io.threads=32 # 磁盘io线程 log.flush.interval.messages=10000 socket.send.buffer.bytes=1024000 # 发送缓冲区
spark资源分配公式
# 集群资源配置示例
spark-submit --master yarn \
--num-executors 16 \ # 执行器数量
--executor-cores 4 \ # 每执行器内核
--executor-memory 8g \ # 执行器内存
--conf spark.sql.shuffle.partitions=128 \ # 并行度
--conf spark.streaming.backpressure.enabled=true # 反压压测指标解读
| 指标 | 健康阈值 | 优化方向 |
|---|---|---|
| 批处理延迟 | < 1s | 增加executor |
| gc时间占比 | < 10% | 调整内存比例 |
| kafka lag | < 1000 | 提升消费并行度 |
验证题目:当观察到spark任务gc时间占比超30%,应如何调整?
答案:1. 增加executor-memory 2. 调整内存分数(spark.memory.fraction)3. 改用g1垃圾回收器
结语:实时智能决策的未来
随着flink等新一代引擎崛起,pyspark+kafka架构持续进化。2023年databricks推出delta live tables,实现流批一体新范式。但核心原则不变:
“实时数据系统的价值不在于速度本身,而在于决策链路的闭环效率”
无论架构如何演进,掌握分布式系统核心原理、理解数据流动的本质,才是工程师应对技术洪流的终极铠甲。
终极挑战:设计支持动态规则更新的实时风控系统架构
参考答案:
- 规则存储在redis/配置中心
- spark streaming通过
broadcast机制加载规则 - 规则变更时触发广播变量更新
- 结合cep引擎(如flink)处理复杂事件序列
通过本文的讲解,你已经掌握了pyspark和kafka在实时数据处理中的核心原理和实战技巧。pyspark提供了强大的分布式数据处理能力,而kafka则为实时数据传输提供了高效的解决方案。通过两者的结合,可以构建一个高效、可靠的实时数据处理系统。
在实际开发中,合理使用这些技术可以显著提升系统的性能和稳定性。通过pyspark和kafka的结合,可以实现更复杂的数据处理场景,满足企业对实时数据分析的需求。
实践建议:
- 在实际项目中根据需求选择合适的pyspark和kafka配置。
- 学习和探索更多的实时数据处理技巧,如流式机器学习和复杂事件处理(cep)。
- 阅读和分析优秀的实时数据处理项目,学习如何在实际项目中应用这些技术。
到此这篇关于python利用pyspark和kafka实现流处理引擎构建指南的文章就介绍到这了,更多相关python kafka流处理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论