一、为什么redis选string作为基础类型?
redis中的所有key是字符串,所有value本质上也是字符串,比如 集合set中的每一个 成员 都是一个独立的字符串对象,列表中的每一个 元素 都是一个独立的字符串对象,整个hash是一个对象,它内部的每一个 字段(field) 和一个字段值(value) 都是一个独立的字符串对象
redis是通过c语言来实现的,但是没有直接使用c语言中的字符串,有几下几点原因
- 获取字符串长度需要通过运算:c字符串以
\0(空字符)结尾,要获取长度必须遍历整个数组直到遇到\0,时间复杂度为o(n),这在高性能数据库如redis中效率低下。 - 非二进制安全:c字符串不能存储任意二进制数据,因为它依赖于
\0作为结束符。如果数据中包含\0(如一些二进制文件),会被错误截断,破坏数据完整性。 - 不可修改:c语言字符串常量(如
char* s = "hello")是只读的,无法直接扩展或修改其长度,这在动态数据存储中不灵活。
redis的解决方案:redis因此构建了自己的字符串结构——sds(简单动态字符串),它通过设计一个智能结构来支持查找、二进制安全性和动态修改。
二、sds底层数据结构
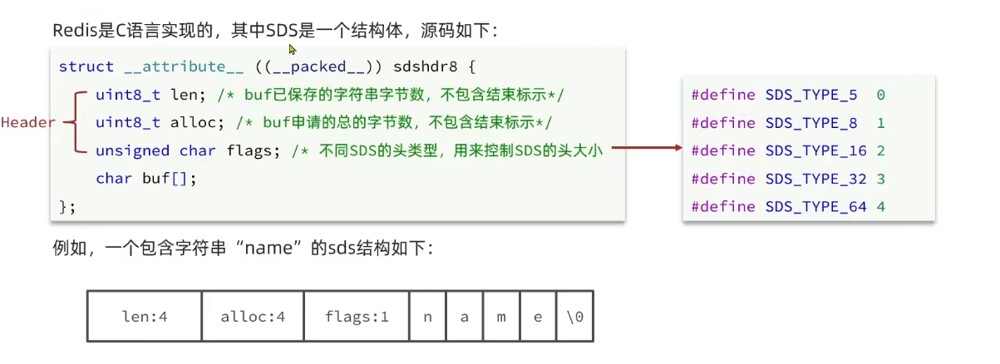
uint8_t (8位无符号整数),可表示的最大值是 255 (因为 2^8 - 1 = 255),因此 len 最多记录 255 字节 的长度,否则会溢出,如果一个 sds 字符串的实际长度超过 255 字节,redis 会自动选择更大容量的结构体(如 sdshdr16/sdshdr32)。
三、redisobject是什么
通常我们了解的数据结构有字符串、双端链表、字典、压缩列表、整数集合等,但是redis为了加快读写速度,并没有直接使用这些数据结构,而是在此基础上又包装了一层称之为redisobject。
redisobject 有五种对象:字符串对象(string)、列表对象(list)、哈希对象(hash)、集合对象(set)和有序集合对象(zset)。
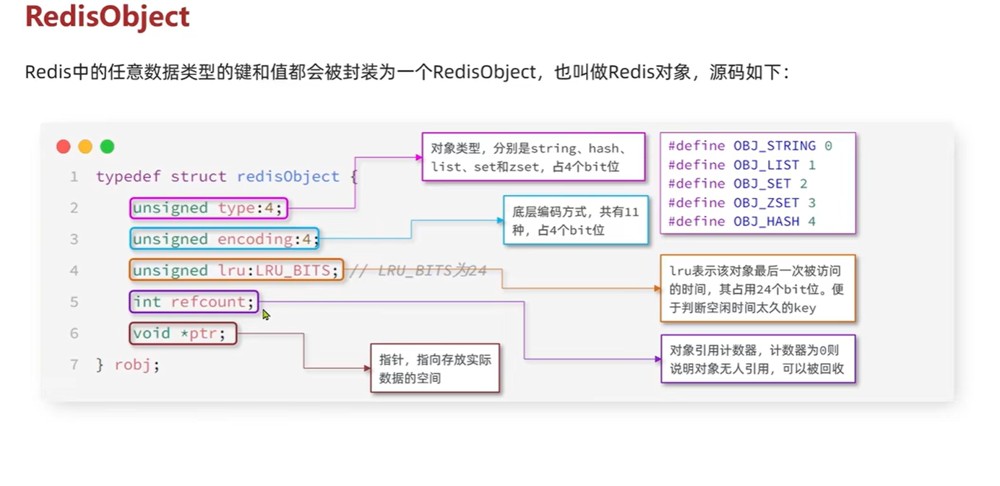
1.type:数据类型标识(4 bit)就是redis基本类型
| 类型常量 | 值 | 对应数据结构 |
|---|---|---|
| obj_string | 0 | 字符串 |
| obj_list | 1 | 列表 |
| obj_set | 2 | 集合 |
| obj_zset | 3 | 有序集合 |
| obj_hash | 4 | 哈希表 |
2.encoding:内部编码(4 bit)
同一数据类型可对应不同底层实现:
| 编码常量 | 值 | 适用类型 | 底层结构 |
|---|---|---|---|
| obj_encoding_int | 0 | string | 整数存储 |
| obj_encoding_embstr | 1 | string | 短字符串优化 |
| obj_encoding_raw | 2 | string | sds动态字符串 |
| obj_encoding_ht | 3 | hash/set | 哈希表 |
| obj_encoding_ziplist | 4 | list/hash/zset | 压缩列表 |
| obj_encoding_quicklist | 5 | list | 快速列表 |
| obj_encoding_skiplist | 6 | zset | 跳表 |
| obj_encoding_stream | 7 | stream | 流数据结构 |
动态编码转换示例:
- 当 hash 的元素超过
hash-max-ziplist-entries时 obj_encoding_ziplist→obj_encoding_ht
3.lru:缓存淘汰信息(24 bit)
- lru模式:记录对象最后访问时间戳(精度:秒级)
- lfu模式(redis 4.0+):
16 bits 8 bits +------------+------+ | 访问时间戳 | 频率 | +------------+------+
- 频率(logc):基于概率递增的访问计数器
- 时间戳:解决冷数据滞留问题
4.refcount:引用计数(4字节)
- 内存回收:
refcount=0时自动释放内存 - 对象共享:相同数据复用对象(如
set key 100共享整数对象) - 多客户端引用:同一 key 被多个客户端连接引用
5.ptr:数据指针(8字节)
指向实际数据结构,如:
obj_encoding_int→ 直接存储整数(void *强转为long)obj_encoding_raw→ 指向sds结构obj_encoding_ht→ 指向dict哈希表
四、string类型数据结构
string类型在redis中有三种编码方式
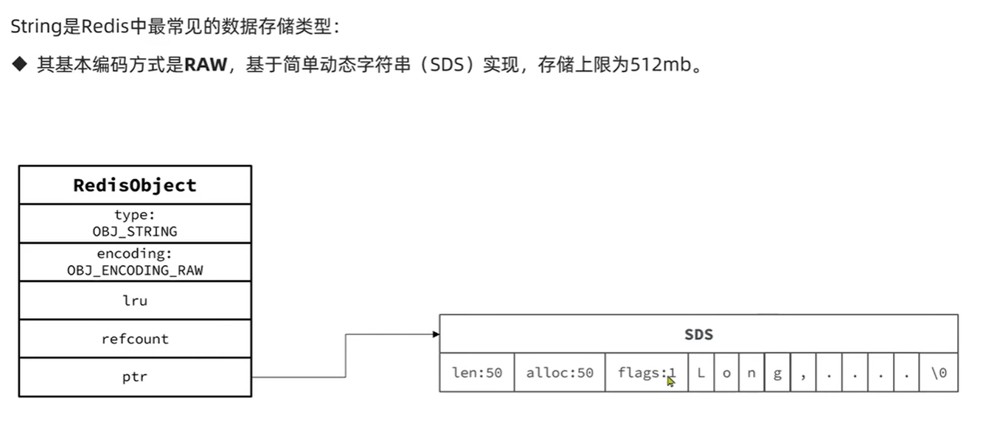
raw编码
分配两次内存 redisobject和sds的内存不连续 两个数据结构申请了两片内存区域
embstr编码

int编码

为什么分界线是44字节?
44字节的临界值源于内存分配器的优化策略,具体计算如下:
1. 内存分配器的最小单位
- redis 默认使用 jemalloc 或 glibc malloc
- 这些分配器的最小分配单元通常是 64字节(cpu缓存行对齐)
2. embstr 的总内存占用公式
总大小 = redisobject(16字节) + sds头部(3字节) + 字符串内容(n字节) + 结束符\0(1字节)
- 最大允许占用:64字节(分配器最小单元)
- 固定开销:16(robj) + 3(sds) + 1(\0) = 20字节
- 可用空间:64 - 20 = 44字节
| 编码类型 | obj_encoding_int | obj_encoding_embstr | obj_encoding_raw |
|---|---|---|---|
| 触发条件 | 数值类型且值在 [long_min, long_max] | 字符串长度 ≤ 44字节 | 字符串长度 > 44字节 |
| 内存分配次数 | 1次(redisobject内联存储) | 1次(连续内存块) | 2次(redisobject + sds分开) |
| 适用场景 | 计数器(如 incr 操作) | 短字符串(如json片段、短url) | 长文本、二进制数据 |
| 修改时的行为 | 直接替换整数值 | 自动转换为 raw 编码 | 原地修改或重新分配 |
| 内存占用示例 | 存储 100:16字节(redisobject) | 存储 "hello":16+6=22字节 | 存储1kb文本:16+1024+9=1049字节 |
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论