用python做pdf压缩
虽然现在有很多成熟的工具了,但是就是想自己捣鼓一下
在网上找了一圈,发现实现方法有两种,一种是需要联网上传(tinypng的api)压缩的,一种是本地用python算法
这里采用的是本地,基本的思路是
- 1、提取pdf内容,保存成图片
- 2、压缩图片
- 3、图片合成pdf
- 4、新增加入多进程和队列的方式,加快压缩
联网上传的我觉得直接用i love pdf这个网页,挺好用的,就不知道安不安全。。。
但是感觉压缩出来的图片不是很理想,就想找一个图片压缩算法替换上去
在网上找到一个python的图片压缩算法,说是**“可能是最接近微信朋友圈的图片压缩算法”**
依赖安装
先安装库 fitz,再安装库pymupdf,地址:https://github.com/pymupdf/pymupdf/
pip install fitz pip install pymupdf pip install easygui # 用来弹出文件选择框的,thinker的话会弹出两个窗口怪怪的
缝合修改
cv大法用上
# -*- coding:utf-8 -*-
# author: peng
# file: mypdf.py
# time: 2021/9/8 17:47
# desc:压缩pdf,对纯图片的pdf效果效果较好,有文字内容的可能会比较模糊,推荐高质量的压缩
import fitz
from pil import image
import os
from shutil import copyfile, rmtree
from math import ceil
from time import strftime, localtime, time
import easygui as g
from functools import wraps
# 时间计数装饰器,func如果有return值,必须返回才能有值
def runtime(func):
@wraps(func)
def wrapper(*args, **kwargs):
print(strftime("%y-%m-%d %h:%m:%s", localtime()))
start = time()
func_return = func(*args, **kwargs)
end = time()
print(func.__name__, args[-1], args[-2], " spend time ", end - start, " sec")
return func_return
return wrapper
class luban(object):
def __init__(self, quality, ignoreby=102400):
self.ignoreby = ignoreby
self.quality = quality
def setpath(self, path):
self.path = path
def settargetdir(self, foldername="target"):
self.dir, self.filename = os.path.split(self.path)
self.targetdir = os.path.join(self.dir, foldername)
if not os.path.exists(self.targetdir):
os.makedirs(self.targetdir)
self.targetpath = os.path.join(self.targetdir, "c_" + self.filename)
def load(self):
self.img = image.open(self.path)
if self.img.mode == "rgb":
self.type = "jpeg"
elif self.img.mode == "rgba":
self.type = "png"
else: # 其他的图片就转成jpeg
self.img = self.img.convert("rgb")
self.type = "jpeg"
def computescale(self):
# 计算缩小的倍数
srcwidth, srcheight = self.img.size
srcwidth = srcwidth + 1 if srcwidth % 2 == 1 else srcwidth
srcheight = srcheight + 1 if srcheight % 2 == 1 else srcheight
longside = max(srcwidth, srcheight)
shortside = min(srcwidth, srcheight)
scale = shortside / longside
if (scale <= 1 and scale > 0.5625):
if (longside < 1664):
return 1
elif (longside < 4990):
return 2
elif (longside > 4990 and longside < 10240):
return 4
else:
return max(1, longside // 1280)
elif (scale <= 0.5625 and scale > 0.5):
return max(1, longside // 1280)
else:
return ceil(longside / (1280.0 / scale))
def compress(self):
self.settargetdir()
# 先调整大小,再调整品质
if os.path.getsize(self.path) <= self.ignoreby:
copyfile(self.path, self.targetpath)
else:
self.load()
scale = self.computescale()
srcwidth, srcheight = self.img.size
cache = self.img.resize((srcwidth // scale, srcheight // scale),
image.antialias)
cache.save(self.targetpath, self.type, quality=self.quality)
# 提取成图片
def covert2pic(doc, totaling, zooms=none):
'''
:param totaling: pdf的页数
:param zooms: 值越大,分辨率越高,文件越清晰,列表内两个浮点数,每个尺寸的缩放系数,默认为分辨率的2倍
:return:
'''
if zooms is none:
zooms = [2.0, 2.0]
if os.path.exists('.pdf'): # 临时文件,需为空
rmtree('.pdf')
os.mkdir('.pdf')
print(f"pdf页数为 {totaling} \n创建临时文件夹.....")
for pg in range(totaling):
page = doc[pg]
print(f"\r{page}", end="")
trans = fitz.matrix(*zooms).prerotate(0) # 0为旋转角度
pm = page.getpixmap(matrix=trans, alpha=false)
lurl = '.pdf/%s.jpg' % str(pg + 1)
pm.writepng(lurl) #保存
doc.close()
# 图片合成pdf
def pic2pdf(obj, ratio, totaling):
doc = fitz.open()
compressor = luban(quality=ratio)
for pg in range(totaling):
path = '.pdf/%s.jpg' % str(pg + 1)
compressor.setpath(path)
compressor.compress()
print(f"\r 插入图片 {pg + 1}/{totaling} 中......", end="")
img = '.pdf/target/c_%s.jpg' % str(pg + 1)
imgdoc = fitz.open(img) # 打开图片
pdfbytes = imgdoc.converttopdf() # 使用图片创建单页的 pdf
os.remove(img)
imgpdf = fitz.open("pdf", pdfbytes)
doc.insertpdf(imgpdf) # 将当前页插入文档
if os.path.exists(obj): # 若pdf文件存在先删除
os.remove(obj)
doc.save(obj) # 保存pdf文件
doc.close()
@runtime
def pdfz(doc, obj, ratio, totaling):
covert2pic(doc, totaling)
pic2pdf(obj, ratio, totaling)
def pic_quality():
print("输入压缩等级1~3:")
comp_level = input("压缩等级(1=高画质50%,2=中画质70%,3=低画质80%):(输入数字并按回车键)")
# 用字典模拟switch分支,注意输入的值是str类型
ratio = {'1': 40, '2': 20, '3': 10}
# 字典中没有则默认 低画质压缩
return ratio.get(comp_level, 10)
if __name__ == "__main__":
print("请选择需要压缩的pdf文件")
while true:
'''打开选择文件夹对话框'''
filepath = g.fileopenbox(title=u"选择pdf", filetypes=['*.pdf'])
if filepath == none:
input("还未选择文件,输入任意键继续.......")
continue
else:
filedir, filename = os.path.split(filepath)
print(u'已选中文件【%s】' % (filename))
if filename.endswith(".pdf") == false:
input("选择的文件类型不对,输入任意键继续.......")
continue
ratio = pic_quality()
obj = "new_" + filename
doc = fitz.open(filepath)
totaling = doc.pagecount
pdfz(doc, obj, ratio, totaling)
rmtree('.pdf')
oldsize = os.stat(filepath).st_size
newsize = os.stat(obj).st_size
print('压缩结果 %.2f m >>>> %.2f m'%(oldsize/(1024 * 1024),newsize/(1024 * 1024)))
input(f"压缩已完成,文件保存在改程序目录下{filedir},如需继续压缩请按任意键")
效果
压缩出来的结果:
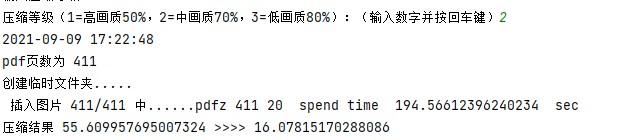
当然,不是所有的pdf压缩都会变小。。。本身pdf文件小的,处理出来后可能会变大,原因应该是图片提取保存的时候图片文件变大,所有压缩进去的时候也会变大。
新增多进程
别的博客中说到:“需要注意的是队列中queue.queue是线程安全的,但并不是进程安全,所以多进程一般使用线程、进程安全的multiprocessing.queue(),而使用这个queue如果数据量太大会导致进程莫名卡住(绝壁大坑来的),需要不断地消费。”
这里对代码的修改部分有几个小地方,提取图片的参数变为pdf路径(因为doc参数在进程调用时会出错),队列转pdf内部加入判断队列为空和取操作,这样就简单实现了生产者-消费者模式
from multiprocessing import process, queue
# 提取成图片
def covert2pic(filepath, qpaper, zooms=none):
'''
:param filepath: pdf文件的位置
:param qpaper: 数据页的队列
:param zooms: 值越大,分辨率越高,文件越清晰,列表内两个浮点数,每个尺寸的缩放系数,默认为分辨率的2倍
:return:
'''
doc = fitz.open(filepath)
totaling = doc.pagecount
if zooms is none:
zooms = [2.0, 2.0]
if path.exists('.pdf'): # 临时文件,需为空
rmtree('.pdf')
mkdir('.pdf')
print(f"pdf页数为 {totaling} \n创建临时文件夹.....")
for pg in range(totaling):
page = doc[pg]
print(f"\r{page}", end="")
trans = fitz.matrix(*zooms).prerotate(0) # 0为旋转角度
pm = page.getpixmap(matrix=trans, alpha=false)
lurl = '.pdf/%s.jpg' % str(pg + 1)
pm.writepng(lurl) # 保存
qpaper.put(pg)
doc.close()
# 图片合成pdf
def pic2pdf(obj, ratio, qpaper, totaling):
doc2 = fitz.open()
compressor = luban(quality=ratio)
for pg in range(totaling):
picpath = '.pdf/%s.jpg' % str(pg + 1)
compressor.setpath(picpath)
while qpaper.empty():
# 如果队列为空,则循环等待
pass
qpaper.get()
compressor.compress()
print(f"\r 插入图片 {pg + 1}/{totaling} 中......", end="")
img = '.pdf/target/c_%s.jpg' % str(pg + 1)
imgdoc = fitz.open(img) # 打开图片
pdfbytes = imgdoc.converttopdf() # 使用图片创建单页的 pdf
remove(img)
imgpdf = fitz.open("pdf", pdfbytes)
doc2.insertpdf(imgpdf) # 将当前页插入文档
if path.exists(obj): # 若pdf文件存在先删除
remove(obj)
doc2.save(obj) # 保存pdf文件
doc2.close()
@runtime
def pdfz(filepath, obj, ratio, totaling):
# 参数传递变为filepath
qpaper = queue() # 创建队列
threads = []
#read_thread = threading.thread(target=covert2pic, args=(doc, totaling, qpaper))
read_thread = process(target=covert2pic, args=(filepath, qpaper))
'''
多进程这里传参数不一定成功,参数需要可以序列化才行,这里如果传doc的变量,会报错weakvaluedictionary.__init__.<locals>.remove
'''
threads.append(read_thread)
#write_thread = threading.thread(target=pic2pdf, args=(obj, ratio, totaling, qpaper))
write_thread = process(target=pic2pdf, args=(obj, ratio, qpaper, totaling))
threads.append(write_thread)
for th in threads:
th.start() # 开始执行线程
for th in threads:
th.join()
print("结束")
最终多进程会比单进程节约大约30%的时间(节约了处理图片和生成pdf的时间,就是函数pic2pdf)
缺点
使用的不是gui界面,没那么美观,感觉也没必要吧哈哈哈
提取文件的时候比较慢,想着多线程但是不会,可能要对文件分块,还是算了
用pyinstaller(本人在conda创建的虚拟环境下python2.6打包出来小一点)打包出来,文件大小差不多30m,而且打包之后运行就没那么流畅了,而且有个坑点
执行过程在cmd黑窗口中打印信息时,有时,一不小心鼠标点到了黑窗口里,程序就会暂停,要回车才能继续,网上的说法是
“或许是cmd启用了快速编辑模式导致的问题。在快速编辑模式,鼠标点击cmd窗口时,可以直接选择窗口里的文本,如果此时cmd中运行的进程需要在cmd窗口中输出信息,这个进程就会被暂停,直到按下回车。”
方法补充
python实现pdf文件压缩
1. 原理pdf切分为图片,根据压缩率zoom压缩图片后保存本地;图片合成pdf
2. 依赖pymupdf包
pip install pymupdf
3. 代码
import fitz
import os
def covert2pic(zoom):
if os.path.exists('.pdf'): # 临时文件,需为空
os.removedirs('.pdf')
os.mkdir('.pdf')
for pg in range(totaling):
page = doc[pg]
zoom = int(zoom) #值越大,分辨率越高,文件越清晰
rotate = int(0)
print(page)
trans = fitz.matrix(zoom / 100.0, zoom / 100.0).prerotate(rotate)
pm = page.getpixmap(matrix=trans, alpha=false)
lurl='.pdf/%s.jpg' % str(pg+1)
pm.writepng(lurl)
doc.close()
def pic2pdf(obj):
doc = fitz.open()
for pg in range(totaling):
img = '.pdf/%s.jpg' % str(pg+1)
imgdoc = fitz.open(img) # 打开图片
pdfbytes = imgdoc.converttopdf() # 使用图片创建单页的 pdf
os.remove(img)
imgpdf = fitz.open("pdf", pdfbytes)
doc.insertpdf(imgpdf) # 将当前页插入文档
if os.path.exists(obj): # 若文件存在先删除
os.remove(obj)
doc.save(obj) # 保存pdf文件
doc.close()
def pdfz(sor, obj, zoom):
covert2pic(zoom)
pic2pdf(obj)
if __name__ == "__main__":
sor = "source.pdf" # 需要压缩的pdf文件
obj = "new" + sor
doc = fitz.open(sor)
totaling = doc.pagecount
zoom = 200 # 清晰度调节,缩放比率
pdfz(sor, obj, zoom)
os.removedirs('.pdf')
4. 使用
- 脚本和要压缩的pdf需在同一路径下
- sor变量为需要压缩的文件
- zoom用于调整压缩率
- 压缩后使用pdf打印功能导出能够进一步压缩
python从pdf中提取图片、压缩pdf
安装必要的库
先安装库 fitz,再安装库pymupdf,地址:https://github.com/pymupdf/pymupdf/
pip install fitz pip install pymupdf
源代码
第一个pdf2pic从pdf中提取jpg文件的部分引用了别人的代码
以下两行doc.引用的注意了,不然会报错
lenxref = doc.xref_length() text = doc.xref_object(i) # 定义对象字符串
另外加入了重新调整过大的照片尺寸,和保存照片的质量,这里有个变量comp_ratio
im = im.resize((1376, y_s), image.antialias) im.save(pic_path_d, quality=comp_ratio)
import fitz
import re
import os
from pil import image
from tkinter import filedialog
def pdf2pic(path, pic_path, comp_ratio):
checkxo = r"/type(?= */xobject)" # 使用正则表达式来查找图片
checkim = r"/subtype(?= */image)"
doc = fitz.open(path) # 打开pdf文件
imgcount = 0 # 图片计数
lenxref = doc.xref_length() # 获取对象数量长度
# 打印pdf的信息
print("文件名:{}, 页数: {}, 对象: {}".format(path, len(doc), lenxref - 1))
# 遍历每一个对象
for i in range(1, lenxref):
text = doc.xref_object(i) # 定义对象字符串
isxobject = re.search(checkxo, text) # 使用正则表达式查看是否是对象
isimage = re.search(checkim, text) # 使用正则表达式查看是否是图片
if not isxobject or not isimage: # 如果不是对象也不是图片,则continue
continue
imgcount += 1
pix = fitz.pixmap(doc, i) # 生成图像对象
new_name = "pic{}.jpg".format(imgcount) # 生成图片的名称
print(new_name)
if pix.n < 5: # 如果pix.n<5,可以直接存为png
pic_path_d = os.path.join(pic_path, new_name)
pix.writeimage(os.path.join(pic_path, new_name))
im = image.open(pic_path_d)
x, y = im.size
if x > 1376:
y_s = int(y * 1376 / x)
im = im.resize((1376, y_s), image.antialias)
im.save(pic_path_d, quality=comp_ratio)
else: # 否则先转换cmyk
pix0 = fitz.pixmap(fitz.csrgb, pix)
pix0.writeimage(os.path.join(pic_path, new_name))
pix0 = none
pix = none # 释放资源
print("提取了{}张图片".format(imgcount))
os.startfile(pic_path)
下面这个rea是用来将文件夹内的照片重新组合为pdf文件
def rea(path, pdf_name):
file_list = os.listdir(path)
pic_name = []
im_list = []
for x in file_list:
if "jpg" in x or 'png' in x or 'jpeg' in x:
pic_name.append(x)
pic_name.sort()
new_pic = []
for x in pic_name:
if "jpg" in x:
new_pic.append(x)
for x in pic_name:
if "png" in x:
new_pic.append(x)
print("hec", new_pic)
im1 = image.open(os.path.join(path, new_pic[0]))
new_pic.pop(0)
for i in new_pic:
img = image.open(os.path.join(path, i))
# im_list.append(image.open(i))
if img.mode == "rgba":
img = img.convert('rgb')
im_list.append(img)
else:
im_list.append(img)
im1.save(pdf_name, "pdf", resolution=100.0, save_all=true, append_images=im_list)
print("输出文件名称:", pdf_name)
def pdf_out():
print('功能完善中')
主程序中随意加了一些判断,如压缩等级1、2、3等。
if __name__ == '__main__':
print("hello world!请先输入压缩等级1~3,然后在弹出的对话框中选择需要压缩的文件")
comp_level = input("压缩等级(1=高画质,2=中画质,3=低画质):(输入数字并按回车键)")
ratio = 10
if comp_level == "1":
ratio = 20
elif comp_level == "2":
ratio = 10
elif comp_level == "3":
ratio = 5
'''打开选择文件夹对话框'''
filepath = filedialog.askopenfilename() # 获得选择好的文件
print('选择的pdf地址:', filepath)
if os.path.exists("./pdf_output"):
pass
else:
os.mkdir("./pdf_output")
pic_path = str(os.getcwd()) + "\pdf_output"
print('提取图片的输出地址:', pic_path )
pdf2pic(filepath, pic_path, comp_ratio=ratio)
pdf_name = 'compressed.pdf'
if ".pdf" in pdf_name:
rea(pic_path, pdf_name=pdf_name)
else:
rea(pic_path, pdf_name="{}.pdf".format(pdf_name))
print("压缩完成,请关闭窗口。若压缩等级不合适,请先删除图片和文件并重新打开程序。")到此这篇关于使用python实现pdf本地化压缩的文章就介绍到这了,更多相关python pdf压缩内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论