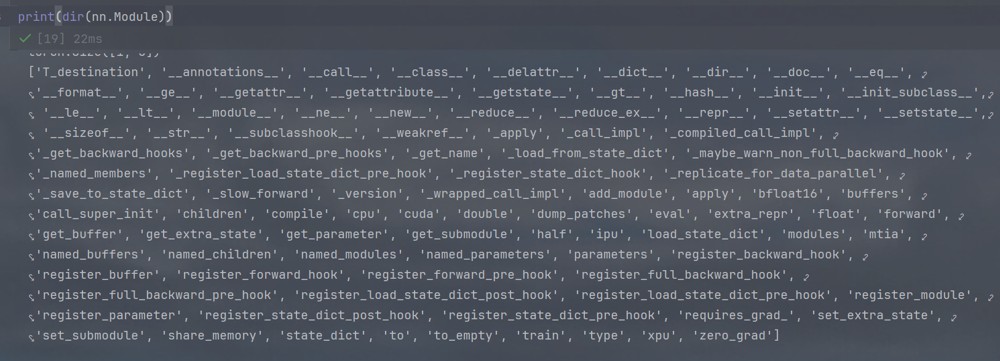
直接print(dir(nn.module)),得到如下内容:
一、模型结构与参数
parameters()- 用途:返回模块的所有可训练参数(如权重、偏置)。
- 示例:
for param in model.parameters(): print(param.shape)
named_parameters()- 用途:返回带名称的参数迭代器,便于调试和访问特定参数。
- 示例:
for name, param in model.named_parameters(): if 'weight' in name: print(name, param.shape)
children()- 用途:返回直接子模块的迭代器。
- 示例:
for child in model.children(): print(type(child))
modules()- 用途:递归返回所有子模块(包括自身)。
- 示例:
for module in model.modules(): if isinstance(module, nn.conv2d): print(module.kernel_size)
二、模型状态与模式
train()和eval()- 用途:切换训练/推理模式(影响dropout、batchnorm等层)。
- 示例:
model.train() # 训练模式 model.eval() # 推理模式
training- 用途:布尔属性,指示当前模式(
true为训练,false为推理)。 - 示例:
print(model.training) # 输出:true/false
- 用途:布尔属性,指示当前模式(
三、模型保存与加载
state_dict()- 用途:返回包含模型所有参数的字典(
ordereddict)。 - 示例:
torch.save(model.state_dict(), 'model.pth')
- 用途:返回包含模型所有参数的字典(
load_state_dict()- 用途:从字典加载模型参数。
- 示例:
model.load_state_dict(torch.load('model.pth'))
四、设备与数据类型
to()- 用途:将模型移动到指定设备(如gpu)或转换数据类型。
- 示例:
model.to('cuda') # 移动到gpu model.to(torch.float16) # 转换为半精度
cpu()和cuda()- 用途:快捷方法,分别将模型移动到cpu或gpu。
- 示例:
model.cuda() # 等价于 model.to('cuda')
五、前向传播与计算
forward()- 用途:定义模型的前向传播逻辑(需在自定义模块中重写)。
- 示例:
class mymodel(nn.module): def forward(self, x): return self.layer(x)
__call__()- 用途:调用模型实例时触发(内部调用
forward(),支持钩子函数)。 - 示例:
output = model(x) # 等价于 output = model.forward(x)
- 用途:调用模型实例时触发(内部调用
六、参数初始化与优化
zero_grad()- 用途:清空所有参数的梯度(通常在每个训练步骤前调用)。
- 示例:
optimizer.zero_grad() # 等价于 model.zero_grad()
requires_grad_()- 用途:设置参数是否需要梯度(用于冻结部分模型)。
- 示例:
for param in model.parameters(): param.requires_grad = false # 冻结所有参数
七、调试与信息
extra_repr()- 用途:自定义模块打印信息(需在子类中重写)。
- 示例:
class mymodel(nn.module): def extra_repr(self): return f"hidden_size={self.hidden_size}"
dump_patches()- 用途:打印模型的补丁信息(用于调试版本差异)。
八、其他实用方法
apply()- 用途:递归应用函数到所有子模块(如初始化权重)。
- 示例:
def init_weights(m): if isinstance(m, nn.conv2d): nn.init.kaiming_normal_(m.weight) model.apply(init_weights)
register_forward_hook()- 用途:注册前向传播钩子(用于捕获中间输出,调试或特征提取)。
总结
日常使用中,最频繁的方法包括:
- 模型构建:
parameters(),children(),modules() - 训练与推理:
train(),eval(),zero_grad(),forward() - 保存与加载:
state_dict(),load_state_dict() - 设备管理:
to(),cuda(),cpu()
其他方法根据具体需求选择使用,例如钩子函数用于高级调试,apply() 用于统一初始化。
与nn.sequential对比:
1. 继承关系与基础属性
nn.module- 是所有神经网络模块的基类,提供最基础的功能(如参数管理、钩子机制)。
- 包含核心属性:
_parameters,_modules,_buffers等。
nn.sequential- 是
nn.module的子类,继承了所有基础功能。 - 额外添加了与顺序执行相关的属性(如
__getitem__、append)。
- 是
2. 核心差异对比
| 功能类别 | nn.module | nn.sequential |
|---|---|---|
| 模块构建 | 需要手动实现 forward 方法 | 自动按顺序执行子模块,无需定义 forward |
| 子模块访问 | 通过属性名(如 self.conv1) | 通过索引或命名(如 model[0]) |
| 动态修改 | 需手动管理子模块 | 支持 append、extend、insert 等操作 |
| 适用场景 | 复杂网络结构(如resnet、u-net) | 简单顺序结构(如lenet卷积部分) |
3. 具体方法对比
3.1 公共方法(两者都有)
# 模型参数与结构 ['parameters', 'named_parameters', 'children', 'modules', 'named_children', 'named_modules'] # 模型状态 ['train', 'eval', 'training', 'zero_grad', 'requires_grad_'] # 设备与数据类型 ['to', 'cpu', 'cuda', 'float', 'double', 'half', 'bfloat16'] # 保存与加载 ['state_dict', 'load_state_dict'] # 钩子机制 ['register_forward_hook', 'register_backward_hook']
3.2nn.sequential特有的方法
# 列表操作(动态修改模块顺序) ['__getitem__', '__setitem__', '__delitem__', '__len__', 'append', 'extend', 'insert', 'pop'] # 索引相关 ['_get_item_by_idx']
3.3nn.module特有的方法
# 自定义实现 ['forward', 'extra_repr'] # 高级管理 ['add_module', 'register_module', 'register_parameter', 'register_buffer']
4. 示例对比
4.1 创建模型
# nn.module(需自定义 forward)
class custommodel(nn.module):
def __init__(self):
super().__init__()
self.conv = nn.conv2d(3, 64, 3)
self.relu = nn.relu()
def forward(self, x):
return self.relu(self.conv(x))
# nn.sequential(自动按顺序执行)
seq_model = nn.sequential(
nn.conv2d(3, 64, 3),
nn.relu()
)4.2 访问子模块
# nn.module custom_model.conv # 通过属性名访问 # nn.sequential seq_model[0] # 通过索引访问 seq_model.append(nn.maxpool2d(2)) # 动态添加模块
5. 总结
| 特性 | nn.module | nn.sequential |
|---|---|---|
| 灵活性 | 高(自定义任意逻辑) | 低(仅支持顺序执行) |
| 代码复杂度 | 较高(需手动实现 forward) | 低(自动处理前向传播) |
| 动态修改 | 不支持直接操作(需手动管理) | 支持 append、insert 等操作 |
| 适用场景 | 复杂网络、分支结构、自定义操作 | 简单堆叠模块(如cnn的卷积部分) |
建议:
- 对于简单的顺序网络,优先使用
nn.sequential以减少代码量。 - 对于包含复杂逻辑(如残差连接、多输入输出)的网络,使用
nn.module自定义实现。
到此这篇关于pytorch中nn.module详解的文章就介绍到这了,更多相关pytorch nn.module内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论