引言:当大语言模型遇见html
想象一下,你邀请了一位学识渊博的教授来家里做客,结果他进门后径直走向你的书架——但书架被透明保鲜膜裹得严严实实!这就是大语言模型(llm)面对html内容时的窘境。html就像这层保鲜膜,包裹着宝贵的内容,却让llm无从下口。别担心,langchain就是你的"html开箱刀"!
在这篇全面指南中,我们将深入探索如何用langchain优雅地处理html内容。准备好迎接代码、原理和实用技巧的盛宴吧!
一、html加载器
为什么需要专门的html加载器
- 标签污染:html中60%的内容是标签而非有效文本
- 结构信息:标题、段落等语义结构对理解至关重要
- 动态内容:现代网页大量依赖javascript渲染
- 资源分离:css/js文件与内容分离
langchain提供多种加载器应对这些挑战:
from langchain.document_loaders import (
unstructuredhtmlloader,
bshtmlloader,
webbaseloader,
asynchtmlloader
)
核心加载器对比表
| 加载器 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| unstructuredhtmlloader | 保留结构信息 | 依赖外部服务 | 复杂文档处理 |
| bshtmlloader | 纯python实现 | 功能较基础 | 简单html提取 |
| webbaseloader | 内置js渲染 | 需要浏览器 | 动态网页 |
| asynchtmlloader | 异步高效 | 仅获取原始html | 批量处理 |
二、实战演练:四种加载方式详解
1. 基础加载 - bshtmlloader
适合处理静态html文件:
from langchain.document_loaders import bshtmlloader
loader = bshtmlloader("example.html")
data = loader.load()
print(f"文档内容:{data[0].page_content[:200]}...")
print(f"元数据:{data[0].metadata}")
2. 保留结构 - unstructuredhtmlloader
使用unstructured api保持文档结构:
from langchain.document_loaders import unstructuredhtmlloader
# 使用元素模式保留结构
loader = unstructuredhtmlloader("blog_post.html", mode="elements")
docs = loader.load()
# 打印检测到的元素类型
for doc in docs:
print(f"元素类型: {doc.metadata['category']}")
print(f"内容: {doc.page_content[:80]}{'...' if len(doc.page_content) > 80 else ''}")
print("-" * 50)
3. 动态网页 - webbaseloader
处理需要javascript渲染的页面:
from langchain.document_loaders import webbaseloader
loader = webbaseloader([
"https://example.com/dynamic-content",
"https://web.with-js.com"
])
loader.requests_per_second = 2 # 礼貌爬取
docs = loader.load()
print(f"加载了{len(docs)}个文档")
4. 批量抓取 - asynchtmlloader
高效处理大量网页:
from langchain.document_loaders import asynchtmlloader
from langchain.document_transformers import html2texttransformer
urls = [f"https://news-site.com/page/{i}" for i in range(1, 6)]
loader = asynchtmlloader(urls)
html = loader.load()
# 转换为纯净文本
html2text = html2texttransformer()
docs_transformed = html2text.transform_documents(html)
print(f"第一页标题:{docs_transformed[0].page_content.splitlines()[0]}")
三、内部揭秘:html加载器如何工作
处理流程解析
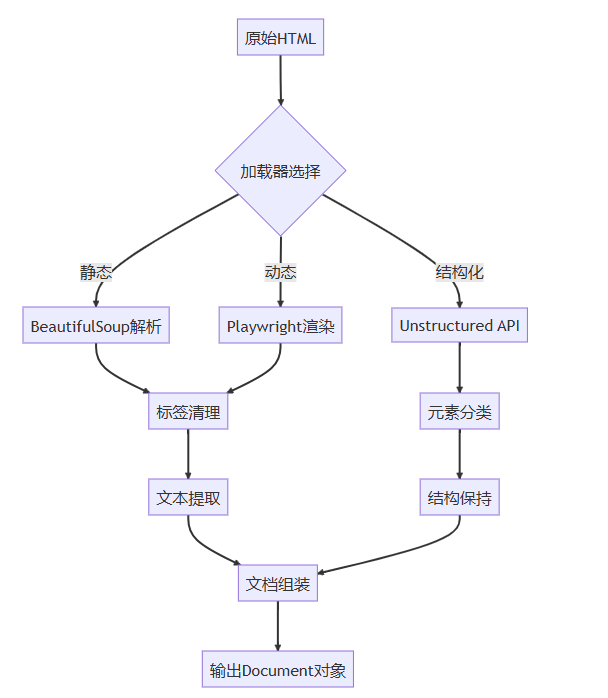
关键技术解析
dom树遍历:深度优先搜索算法提取文本节点
内容分类器:基于规则和机器学习识别标题/正文
动态渲染:无头浏览器执行javascript
文本规范化:
- 合并相邻文本节点
- 智能空格处理
- unicode规范化
元数据提取:
<title>标签内容<meta>描述信息- opengraph协议数据
四、避坑指南:html加载的七个致命错误
忽略编码问题
# 错误做法:默认utf-8
loader = bshtmlloader("gbk_page.html")
# 正确做法:指定编码
loader = bshtmlloader("gbk_page.html", encoding="gbk")
过度请求被封ip
# 添加延迟和伪装头
loader = webbaseloader(
urls,
header_template={
"user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/91.0.4472.124 safari/537.36",
"accept-language": "en-us,en;q=0.9"
},
requests_per_second=2
)
遗漏动态内容
# 确保启用js渲染
loader = webbaseloader("https://react-app.example")
loader.scrapejs = true # 默认已启用
处理登录墙
# 使用会话保持cookies
from requests.sessions import session
session = session()
session.post("https://site.com/login", data={"user": "...", "pass": "..."})
loader = webbaseloader("https://site.com/protected", session=session)
无限滚动陷阱
# 手动处理滚动
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://infinite-scroll.site")
# 滚动5次
for _ in range(5):
page.evaluate("window.scrollto(0, document.body.scrollheight)")
page.wait_for_timeout(2000) # 等待加载
content = page.content()
loader = bshtmlloader.from_string(content)
忽略反爬机制
# 使用代理轮询 proxies = ["http://proxy1:port", "http://proxy2:port"] loader = asynchtmlloader(urls, proxies=proxies, rotate_proxy=true)
内存爆炸
# 分批处理大文件
from langchain.text_splitter import recursivecharactertextsplitter
splitter = recursivecharactertextsplitter(
chunk_size=2000,
chunk_overlap=200
)
docs = loader.load()
chunks = splitter.split_documents(docs)
五、最佳实践:工业级html处理方案
完整处理流水线
from langchain.document_loaders import webbaseloader
from langchain.document_transformers import html2texttransformer
from langchain.text_splitter import recursivecharactertextsplitter
from langchain.embeddings import openaiembeddings
from langchain.vectorstores import chroma
def html_processing_pipeline(url):
# 1. 加载
loader = webbaseloader(url)
raw_docs = loader.load()
# 2. 转换
html2text = html2texttransformer()
cleaned_docs = html2text.transform_documents(raw_docs)
# 3. 分块
splitter = recursivecharactertextsplitter(
chunk_size=1500,
chunk_overlap=200,
separators=["\n\n", "\n", "。", "!", "?"]
)
chunks = splitter.split_documents(cleaned_docs)
# 4. 向量化
embeddings = openaiembeddings()
vectorstore = chroma.from_documents(chunks, embeddings)
return vectorstore
# 使用示例
store = html_processing_pipeline("https://example.com")
retriever = store.as_retriever(search_kwargs={"k": 3})
智能内容提取技巧
# 使用css选择器精准定位
from bs4 import beautifulsoup
def extract_main_content(html):
soup = beautifulsoup(html, 'html.parser')
# 策略1:尝试常见内容容器
selectors = [
'article',
'.post-content',
'.article-body',
'main',
'[role="main"]'
]
for selector in selectors:
element = soup.select_one(selector)
if element and len(element.text) > 500:
return element.get_text()
# 策略2:回退到正文密度检测
all_text = soup.get_text()
return all_text # 实际应用中应实现正文密度算法
# 集成到langchain
class smarthtmlloader(bshtmlloader):
def load(self):
raw_docs = super().load()
for doc in raw_docs:
doc.page_content = extract_main_content(doc.page_content)
return raw_docs
六、面试考点:html加载的深度问答
q: 如何处理需要登录的网页? a: 需要维护会话状态,典型方案有:
- 使用
requests.session保持cookies - playwright的存储状态重用
- 模拟登录后保存身份令牌
q: 大型html文档导致内存溢出怎么办?
a: 采用流式处理:
from langchain.document_loaders import unstructuredfileioloader
with open("large.html", "rb") as f:
loader = unstructuredfileioloader(f, strategy="fast")
for chunk in loader.lazy_load():
process(chunk)
q: 如何保证网页内容的最新性?
a: 实现缓存策略:
from datetime import timedelta
from langchain.cache import sqlitecache
loader = webbaseloader("https://news.com")
loader.cache = sqlitecache(
ttl=timedelta(hours=1), # 1小时缓存
db_path=".cache.db"
)
q: 如何处理多语言html内容?
a: 需要语言检测和特殊处理:
from langdetect import detect
docs = loader.load()
for doc in docs:
lang = detect(doc.page_content)
doc.metadata["language"] = lang
if lang == "ja": # 日语需要不同分句
custom_split_japanese(doc)
七、未来展望:html处理的进化方向
ai增强解析
- 使用llm识别内容区域
- 自动过滤广告/推荐内容
视觉感知处理
# 结合截图理解布局
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
page.screenshot(path="screenshot.png")
# 使用cv模型分析布局
layout = analyze_layout("screenshot.png")
content = extract_by_coordinates(html, layout)
交互式抓取
# 自动化交互操作
loader = webbaseloader("https://dashboard.example")
loader.playwright_actions = [
{"action": "click", "selector": "#load-more"},
{"action": "type", "selector": "#search", "text": "keyword"},
{"action": "wait_for", "selector": ".results"}
]
八、结语:html处理的终极艺术
langchain的html加载器就像一位经验丰富的考古学家——他能从html的废墟中挖掘出知识的宝藏,拂去标签的尘埃,还原内容的真容。通过本指南,你已经掌握了:
- 四类加载器的精准选择
- 动态内容的完整处理方案
- 工业级处理流水线搭建
- 复杂场景的应对策略
- 面试深度问题的解答思路
记住,优秀的html处理不是简单地移除标签,而是理解内容背后的结构和语义。
到此这篇关于从入门到精通详解langchain加载html内容的全攻略的文章就介绍到这了,更多相关langchain加载html内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论