本节用到的员工信息管理表结构放到资源中,需要的同学自取。本节内容以此表为示例:
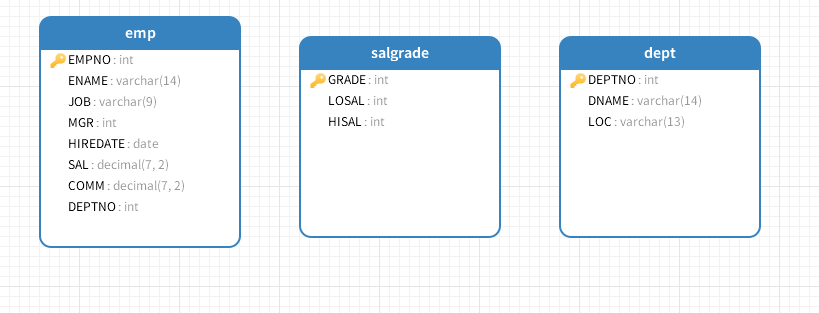
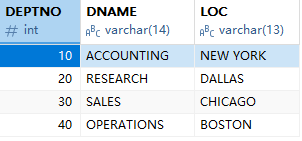
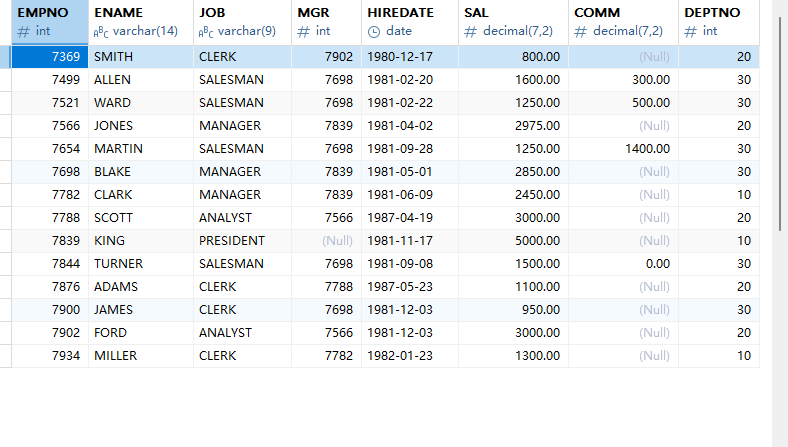
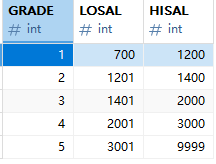
面试题:innodb与myisam的区别。
外键,事务
| 特性 | innodb | myisam |
|---|---|---|
| 事务支持 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 锁粒度 | 行级锁 | 表级锁 |
| 索引结构 | 聚簇索引 | 非聚簇索引 |
| 崩溃恢复 | 支持 | 不支持 |
| 空间效率 | 较高(但占用更多空间) | 较低(但更紧凑) |
| 写性能 | 高(行级锁) | 低(表级锁) |
| 适用场景 | 事务、高并发写 | 静态数据、读密集型 |
一、简单查询
语法:
select [ 去重关键字distinct] 字段 from 表格名称;
字段:*代表所有字段
select 字段 as "字段别名"... from 表格名称;
as可以省略不写,后面空格直接跟别名。
查询所有员工的编号,姓名,薪资
select empno"员工编号",ename"员工姓名",sal"员工薪资" from emp;
二、限定查询
语法:
select [ 去重关键字distinct] 字段 from 表格名称 [限定语法];
where >, < ,>= ,<= ,!=, between...and...,
查询公司中工资高于2000的员工
select * from emp where sal > 2000;
查询公司中工资1000到3000的员工
select * from emp where sal between 1000 and 3000; select * from emp where sal > 1000 and sal < 3000;
查询有奖金的员工信息
select * from emp where comm > 0
查询没有奖金的员工信息
select * from emp where comm is null or comm = 0
查询名称中以s开头 模糊匹配 %通配所有 _通配一位
select * from emp where ename like "s%" 以s开头 select * from emp where ename like "%s" 以s结尾 select * from emp where ename like "%s%" 名称中包含s select * from emp where ename like "_o%" 第二位为o,其余无所谓
查询1981年入职的员工信息
select * from emp where hiredate between '1981-01-01' and '1981-12-31' select * from emp where hiredate like '%1981%'
查询员工编号为7499,7521的员工信息
select * from emp where empno = 7499 or empno = 7521 select * from emp where empno in (7499,7521)
三、排序查询
语法:
select [ 去重关键字distinct] 字段 from 表格名称 [限定语法][排序条件];
排序关键字:order by
升序:asc
降序:desc
查询员工信息,根据薪资做倒序排序
select * from emp order by asl desc;
查询员工信息,根据入职日期做降序排序, 日期一致则按薪资升序排序。
select * from emp order by hiredate desc ,sal asc;
四、多表查询
语法:select [去重关键字distinct] 字段 from 表格名称 , 表格名称 [限定语法][排序条件];
查询所有员工信息,包含部门信息
select * from emp,dept
以上查询方式将两张表进行简单堆积,查询中有无用的冗余数据,这种现象称之为笛卡尔积效应
在查询过程中,添加关联条件,用来在显示上消除笛卡尔积效应
select * from emp,dept where emp.deptno = dept.deptno select e.*,d.dname,d.loc from emp e,dept d where e.deptno = d.deptno
查询所有员工信息,包含员工编号、员工姓名、员工薪资、领导编号、领导姓名、领导薪资
确定需要的表格:emp e1,emp e2
确定需要的字段:e1.empno '员工编号',e1.ename '员工姓名',e1.sal '员工薪资',e2.empno '领导编号',e2.ename '领导姓名',e2.sal '领导薪资'
确定需要的关联条件:e1.mgr = e2.empno
组装sql:
select e1.empno '员工编号', e1.ename '员工姓名', e1.sal '员工薪资', e2.empno '领导编号', e2.ename '领导姓名', e2.sal '领导薪资' from emp e1, emp e2 where e1.mgr = e2.empno;
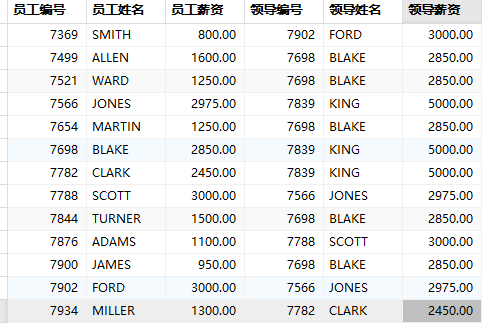
以上sql查询完之后,显示13条结果,king这条数据没有显示(边界值无法查询),如果向解决边界值问题,需要使用连接查询
五、连接查询
语法:
select [去重关键字distinct] 字段 from 表格名称 [连接条件] 表格名称 [限定语法][排序条件];
左(外)连接:left(outer) join ...on...
右(外)连接:right(outer) join ...on...
以哪个表为重点就哪边连接;
查询所有员工信息,包含员工编号、员工姓名、员工薪资、领导编号、领导姓名、领导薪资
select
e1.empno as '员工编号',
e1.ename as '员工姓名',
e1.sal as '员工薪资',
e2.empno as '领导编号',
e2.ename as '领导姓名',
e2.sal as '领导薪资'
from
emp e1
left join
emp e2 on e1.mgr = e2.empno;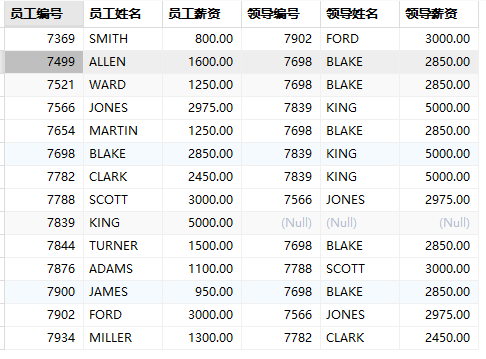
拓展语法:sql1999语法
交叉连接:select * from emp join dept; 类似于“,”进行笛卡尔积, 查询显示56条结果
自然连接:select * from emp natural join dept; 自动组合共同字段,查询显示14条结果
join...on+条件:select * from emp join dept on emp.deptno = dept.deptno; 查询显示14条结果
join...using(两边表的共同字段):select * from emp join dept using(deptno); 查询显示14条结果
六、分组查询
分组前提:需要分组的字段有重复值
语法:
select [去重关键字distinct] 字段 from 表格名称 [限定语法][分组条件][排序条件];
分组关键字:group by注意事项:
1.一旦出现分组条件,那么select后边只允许出现统计函数和分组字段
2.分组之后如果还想使用限定条件筛选,那么不允许使用where,需要使用having
查询每一个部门的平均工资
确定需要的表:emp
确定需要的字段:avg(sal)
确定需要的分组条件:group by deptno
组装sql:select avg(sal) from emp group by deptno优化sql:select deptno,avg(sal) from emp group by deptno
发现上述sql中没有40部门(边界值)
确定需要的表:emp e,dept d
确定需要的字段:d.deptno,avg(sal)
确定需要的分组条件:group by d.deptno
组装sql:
select
d.deptno,
ifnull(avg(sal), 0) '平均工资'
from
emp e
right join
dept d on e.deptno = d.deptno
group by
d.deptno;查询部门的平均薪资,要求显示平均薪资高于2000的信息
select
d.deptno,
ifnull(avg(e.sal), 0) as '平均工资'
from
dept d
left join
emp e on d.deptno = e.deptno
group by
d.deptno
having
ifnull(avg(e.sal), 0) > 2000; -- 确保在过滤时处理 null 值
avg(sal) > 2000七、统计查询
平均avg 最大值max 最小值min 统计数量 count 求和 sum
拓展技术:
单行函数参考单行函数文档。
八、子查询
where 子查询
当查询的结果为单行单列或多行单列的时候
查询比smith工资高的所有员工信息。
select * from emp where sal > (select sal from emp where ename = 'smith');
查询公司中和经理一样工资的员工信息
select * from emp where sal in (select sal from emp where job = 'manager')
小贴士:
=ang 等同于 in
<ang 等同于 比最大值小的数据
>ang 等同于 比最小值大的数据
<all 等同于 比最小值小的数据
>all 等同于 比最大值大的数据
from 子查询
当查询的结果为多行多列
查询部门编号、部门名称、部门位置、部门人数、部门平均薪资
第一步:查询部门单表信息(4条结果)
select * from dept
第二步:查询员工表,得到部门人数、部门平均(3条结果)
确定需要的表格:emp e 确定需要的字段:e.deptno deptno,count(e.empno) num,avg(e.sal) sal 确定需要的分组条件:group by e.deptno 组装sql: select e.deptno deptno,count(e.empno) num,avg(e.sal) sal from emp e group by e.deptno
第三步:将上述sql进行左右连接查询
确定需要的表格:
dept d,
(select e.deptno deptno,count(e.empno) num,avg(e.sal) sal from emp e group by e.deptno) temp
确定需要的字段:d.deptno,d.dname,d.loc,temp.num,temp.sal
确定需要的关联条件:d.deptno = temp.deptno
组装sql:
select
d.deptno,
d.dname,
d.loc,
temp.num,
temp.sal
from
dept d
left join
(
select
e.deptno as deptno,
count(e.empno) as num,
avg(e.sal) as sal
from
emp e
group by
e.deptno
) temp
on
d.deptno = temp.deptno;九、分页查询
为什么需要分页查询?
语法:select [去重关键字distinct] 字段 from 表格名称 [限定语法][分组条件][排序条件][分页条件]
分页:limit n,m
n:数据索引,从0开始
m:每一页显示多少条
查询第一页员工数据,一页显示10条
select * from emp limit 0,10;
当n为0的时候,可以省略不写:select * from emp limit 10;
第二页:
select * from emp limit 10,10;
事务
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
事务的四大特性:
1、原子性(atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
2、一致性(consistency):几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
3、隔离性(isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
4、持久性(durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
脏读 幻读
mysql数据库事务测试
mysql的事务是默认提交机制
事务提交机制有两种:自动提交,手动提交
修改数据库事务提交机制:
关闭自动提交:set autocommit = 0;开启自动提交:set autocommit = 1;
如果关闭自动提交,那么在发生增删改以后需要程序员提交(commit)或回滚(rollback)
mysql数据库事务隔离级别
mysql 提供了四种事务隔离级别,以确保数据的一致性和完整性。这四种隔离级别分别是:读未提交(read uncommitted)、读已提交(read committed)、可重复读(repeatable read)和可串行化(serializable)
读未提交(read uncommitted):
定义:事务可以读取其他未提交事务的更改。问题:可能导致脏读(dirty read)
适用场景:对数据一致性要求不高的场景。
读已提交(read committed):(oracle默认级别)
定义:事务只能读取其他已提交事务的更改。
问题:避免了脏读,但可能导致不可重复读(non-repeatable read)
适用场景:大多数数据库系统的默认隔离级别,如oracle。
可重复读(repeatable read):(mysql默认级别)
定义:在同一事务中多次读取相同数据时,结果一致。
问题:避免了脏读和不可重复读,但可能导致幻读(phantompead)。
适用场景:mysql 的默认隔离级别,适用于大部分应用。
可串行化(serializable):
定义:最高的隔离级别,事务按顺序逐个执行,完全隔离。
问题:避免了脏读、不可重复读和幻读,但并发性能最差。
适用场景:对数据一致性要求极高的场景。
脏读(dirty read)。
定义:读取到其他事务未提交的修改数据,若该事务回滚则导致数据无效
示例:事务a修改账户余额后未提交,事务b读取到该临时值;若事务a回滚,事务b基于脏数据操作将引发错误不可重复读(non-repeatable read)
定义:同一事务内多次读取同一数据,因其他事务已提交的修改导致结果不一致
示例:事务a第一次查询余额为1000元,事务b修改为800元并提交后,事务a再次查询结果变为800元幻读(phantom read)
定义:同一事务内两次范围查询的结果行数不同,因其他事务插入或删除数据
示例:事务a首次查询年龄>30的用户共10人,事务b新增1人后,事务a再次查询结果为11人
隔离级别测试:
数据库默认隔离级别查看:
- 查看全局默认隔离级别(5.7版本之前):
select @@global.tx_isolation; - 查看全局默认隔离级别(5.7版本之后):
select @@global.transaction_isolation; - 查看当前会话隔离级别(5.7版本之前):
select @@session.tx_isolation; - 查看当前会话隔离级别(5.7版本之后):
select @@session.transaction_isolation;
第一步:修改数据库隔离级别
set [global|session} transaction isolation level [read uncommitted|read committed|repeatable read|serializable]
第二步:设置手动提交
set autocommit = 0;
第三步:开启事务
start transaction;
第四步:测试业务
update t_person set sal = sal-500 where id = 1; update t_person set sal = sal+500 where id = 3;
索引、优化、b+tree后续再了解。
python连接数据库
安装模块pymysql
第一步:导入模块
import pymysql
第二步:创建连接
conn = pymysql.connect (host='locohost', user='user', password='password', port=3306,database='database')
第三步:创建数据库对象
cursor = conn.cursor()
第四步:执行sql语句
sql = "select * from emp" #通过数据库对象执行sql cont = cursor.execute(sql) #执行sql语句,返回查询结果的行数。 result = cursor.fetchall() #执行 execute() 后查询的所有结果
第五步:关闭连接
cursor.close() conn.close()
传参问题
- 方式一:直接字符串拼接
把变量(如username、password、id)拼接到 sql 语句里,有严重 sql 注入风险 ,比如用户输入恶意内容可篡改查询逻辑。
示例:sql = "select * from t_user where username = '" +username+ "' and password = '" +password+ "'"
- 方式二:简单格式化拼接(仍有风险)
用%做占位符拼接参数,看似规范但本质还是字符串拼接,仍可能被 sql 注入 (如输入lufei' or 1=1 --可绕过校验 )sql = "select * from t_user where username = '%s' and password = '%s'"%(username,password)
- 方式三:参数化查询(推荐)
用%s做占位符,但实际执行时由数据库驱动自动处理参数转义,可有效避免 sql 注入 ,是安全的传参方式sql = "select * from t_user where username = %(name)s and password = %(pwd)s" cursor.execute(sql, {"name": username, "pwd": password})
到此这篇关于mysql查询优化与事务实战指南的文章就介绍到这了,更多相关mysql查询优化内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论