下载python和依赖的库
python-docx读取word的库
官网:http://python-docx.readthedocs.io/en/latest/
读取excel的库:xlrd
写入excel的库:xlwt
两者的帮助库:xlutils
官网:http://www.python-excel.org/
上面是操作xls文件的库,如果要操作xlsx文件可以用openpyxl这个库
在命令行中输入以下命令即可
pip install python-docx #安装python-docx依赖库 pip install xlrd #读excel的库 pip install xlwt #写excel的库 pip install xlutils #复制excel的库
因为lz是以.doc格式的word文档,需要转为docx才能被这些库打开,因此用pywin32把.doc的文件转为.docx的文件,并且把转换的相关信息写到一个excel里面
xlrd,xlwt,xlutils只能操作xls类型的文件,如果想要操作xlsx类型的文件,可以用openpyxl这个库
如果需要直接修改一下输入和输出目录
# _*_ coding:utf-8 _*_
import os
import win32com
import xlwt
from win32com.client import dispatch
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#要转换的doc文件目录
docdir = r'c:\users\administrator\desktop\井陉矿区\井陉矿区'
#转换成功的docx文件目录
docxdir = r'd:\data\data10'
#包含转换信息的文件,主要包括转换成功的文件,转换失败的文件
msgexcel = r'd:\data\data10\转换信息表1.xls'
#文件总数
filetotal = 0
#转换正确的文件总数
successlist = []
#装换错误的文件总数
errorlist = []
#将转换信息写入到excel中
def writemsg():
excel = xlwt.workbook(encoding='utf-8')
# 这个是指定sheet页的名称
sheet1 = excel.add_sheet('统计信息')
sheet2 = excel.add_sheet('详细信息')
sheet1.write(0, 0, '文件总数')
sheet1.write(0, 1, '录入正确')
sheet1.write(0, 2, '录入错误')
sheet1.write(1, 0, filetotal)
sheet1.write(1, 1, len(successlist))
sheet1.write(1, 2, len(errorlist))
sheet2.write(0, 0, '录入正确')
sheet2.write(0, 1, '录入错误')
row = 1
for x in successlist:
sheet2.write(row, 0, x)
row += 1
row = 1
for x in errorlist:
sheet2.write(row, 1, x)
row += 1
excel.save(msgexcel.decode('utf-8'))
if __name__ == "__main__":
word = win32com.client.dispatch('word.application')
word.displayalerts = 0
word.visible = 0
path = unicode(docdir, 'utf8')
for root, dirs, files in os.walk(path):
filetotal = len(files)
for name in files:
filename = os.path.join(root, name)
print filename
try:
doc = word.documents.open(filename)
#这个是保存的目录
doc.saveas(docxdir + "\\" + filename.split("\\")[-1].split(".")[0] + ".docx", 12)
doc.close()
successlist.append(name)
except exception as e:
errorlist.append(name)
continue
writemsg()
为了转换方便lz直接封装了一个工具,你们也可以模仿我这个页面将自己的工具也封装成图形界面:http://blog.csdn.net/zzti_erlie/article/details/78922112
读取word内容
假如word的内容为:
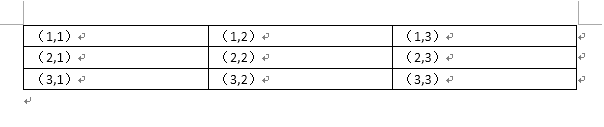
代码为:
# coding=utf-8
from docx import document
import xlrd
#打开word文档
document = document('test.docx')
#获取word文档中的所有表格是一个list
temptable = document.tables
#获取第一个表格
table = temptable[0]
#遍历表格
for x in table.rows:
for y in x.cells:
print y.text,
print
则读取如下:
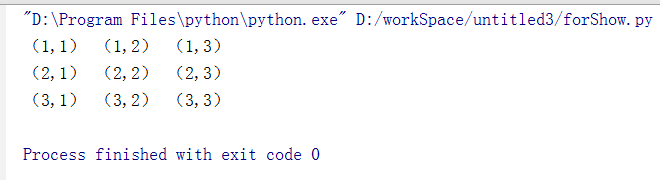
如果把表格合并成如下格式:

读取如下:

可以看出虽然表格合并了,可还是按3行3列输出,只不过是合并的内容相同,这样从word中取数据就特别麻烦,可以通过判重来取,但也是特别复杂,下面写一个简单的demo说一下具体的做法
主要思路
主要思路是弄一个模板表用来获取每个字段数据所在的位置,读取模板表将数据放入dict中,其中key为字段名,值为位置,在读取数据表,通过dict获取字段的值,并将字段的值和字段的数据放入sheetdict中,最后将sheetdict和excel列名相同的数据放到这一列下面,我们不能通过api直接在空的excel中写数据,直接通过复制一个空的excel得到另一个excel,在复制的这个excel中写数据
word和excel的格式
模板表.docx

学生信息表1.docx
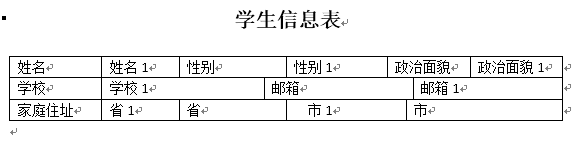
学生信息表.xlsx

样例代码
# _*_ coding:utf-8 _*_
from docx import document
import xlwt
import xlrd
from xlutils.copy import copy
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
#开始的excel
startexcel = r'd:\workspace\forshow\学生信息表.xlsx'
#最后生成的excel,这个库只能保存xls格式的文件
endexcel = r'd:\workspace\forshow\学生信息表.xls'
#模板表
templete = r'd:\workspace\forshow\模板表.docx'
#word所在的文件夹
worddir = r'd:\workspace\forshow\数据'
#模板表中每个字段对应的位置,键是字段,值是所在的位置
dict1 = {}
#判断是否是英文
def isenglish(checkstr):
for ch in checkstr.decode('utf-8'):
if u'\u4e00' <= ch <= u'\u9fff':
return false
return true
#读取模板表
def readtemplate():
document = document(templete.decode('utf-8'))
temptable = document.tables
table = temptable[0]
rowlist = table.rows
columnlist = table.columns
rowlength = len(rowlist)
columnlength = len(columnlist)
for rowindex in range(rowlength):
for columnindex in range(columnlength):
cell = table.cell(rowindex,columnindex)
if isenglish(cell.text):
dict1.setdefault(cell.text,[rowindex,columnindex])
#读入的表
re = xlrd.open_workbook(startexcel.decode("utf-8"))
#通过复制读入的表来生成写入的表
we = copy(re)
#写第一页的sheet
def writefirstsheet1(table, row):
sheet = we.get_sheet(0)
#将字段对应的值填到sheet1dict中
sheet1dict = {}
for key in dict1:
templist = dict1[key]
for index in range(0,1):
x = templist[index]
y = templist[index+1]
sheet1dict.setdefault(key,table.cell(x,y).text)
#读取第一个sheet
tempsheet = re.sheet_by_index(0)
#读取第一个sheet中的第二行
list1 = tempsheet.row_values(1)
for excelindex in range(len(list1)):
for key in sheet1dict:
if list1[excelindex] == key:
#将sheet1dict中的内容写入excel的sheet中
sheet.write(row, excelindex, sheet1dict[key])
#将word中数据写入excel
def writeexcel(wordname, row):
document = document(wordname)
temptable = document.tables
table = temptable[0]
#一个excel一般有好几个sheet(即页数),所以单独写一个函数
writefirstsheet1(table, row)
we.save(endexcel.decode("utf-8"))
if __name__ == "__main__":
readtemplate()
docfiles = os.listdir(worddir.decode("utf-8"))
# 开始数据的行数
row = 1
for doc in docfiles:
#输出文件名
print doc.decode("utf-8")
try:
row += 1
writeexcel(worddir + '\\' + doc.decode("utf-8"), row)
except exception as e:
print(e)
生成的excel
学生信息表.xls
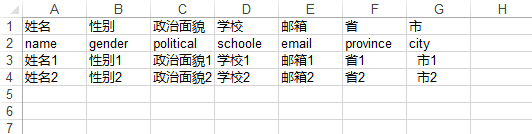
知识扩展
使python把文件夹下所有的excle写入word文件中
完整代码
from pathlib import path, purepath
from openpyxl import load_workbook
from docx import document
# 当前目录
p = path('./')
# 获取所有 xlsx 文件
files = [x for x in p.iterdir() if x.is_file() and purepath(x).match('*.xlsx')]
# 创建 word 文档
doc = document()
for file in files:
print(f'文件名={file.name}')
wb = load_workbook(file)
for sheet_name in wb.sheetnames:
print(f"工作表名称: {sheet_name}")
ws = wb[sheet_name]
# 在 word 中加标题(文件名 + sheet名)
doc.add_heading(f"{file.name} - {sheet_name}", level=2)
# 获取 sheet 所有数据
data = []
for row in ws.iter_rows(values_only=true):
# 如果整行都是空,则跳过
if all(cell in (none, '') for cell in row):
continue
data.append([str(cell) if cell is not none else '' for cell in row])
if data:
# 创建 word 表格
table = doc.add_table(rows=1, cols=len(data[0]))
table.style = 'table grid'
# 表头(假如没有表头,这里就只是第一行)
hdr_cells = table.rows[0].cells
for idx, val in enumerate(data[0]):
hdr_cells[idx].text = val
# 添加数据行
for row_data in data[1:]:
row_cells = table.add_row().cells
for idx, val in enumerate(row_data):
row_cells[idx].text = val
doc.add_paragraph('') # 分段落空行
else:
doc.add_paragraph('(此工作表为空)')
# 保存 word 文件
output_dir = path('../word')
output_dir.mkdir(exist_ok=true, parents=true)
output_file = output_dir / 'merged.docx'
doc.save(output_file)
print(f"已将所有 excel 数据写入 word 文件: {output_file}")
到此这篇关于使用python将word中的内容写入excel的文章就介绍到这了,更多相关python word写入excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论