pdf 文件在日常工作中非常常见,比如合同、项目报告、课程讲义等。作为重要的共享和存档格式,pdf 的合并和拆分是最常见的处理需求之一。然而,手动操作不仅效率低,还容易出错,尤其是在处理大文件时更是如此。
幸运的是,通过 python 脚本可以轻松实现 pdf 的自动化处理,大幅提升工作效率,并有效减少人为错误。本文将带你掌握如何使用 python 快速拆分和合并 pdf,无论是需要将扫描件按页存档,还是将多份报告汇总成一个文件,都能轻松完成。
环境准备
本文将使用 spire.pdf for python 库来完成任务。作为一款专业且强大的 python pdf 库,spire.pdf 不仅可以在无需依赖 adobe acrobat 的情况下读取、编辑、转换 pdf,还能通过丰富的 api 对 pdf 文件进行精细化控制,例如本文将介绍的 pdf 拆分和合并操作。
你可以通过以下命令安装正式版:
pip install spire.pdf
或者使用免费版:
pip install spire.pdf.free
免费版在处理页数上有限制,但对于小型任务已经足够。
温馨提示:在动手实践本文提供的方法和代码前,请先准备若干示例 pdf 文件。
pdf 拆分实用方法
pdf 文件应用广泛,不同场景下对页面拆分的需求也各不相同。本章节将介绍如何使用 python 实现两种常见的拆分方法:将 pdf 按页拆分为单页文件,以及按照指定页范围拆分 pdf。一起看看具体怎么做吧!
将 pdf 按页拆分为单页文件
当你需要将 pdf 文档中的每一页单独保存为独立文件时,比如将扫描件按页存档,这种方法将非常适合你的需求!
完整代码示例 - 通过 python 将 pdf 文件按页拆分为独立文件:
from spire.pdf.common import *
from spire.pdf import *
# 创建一个 pdfdocument 对象
doc = pdfdocument()
# 加载一个 pdf 文件
doc.loadfromfile("/示例文档.pdf")
# 将 pdf 文件拆分为多个单页的 pdf 文件
doc.split("/pdf 拆分/拆分结果-{0}.pdf", 1)
# 关闭 pdfdocument 对象
doc.close()效果预览:
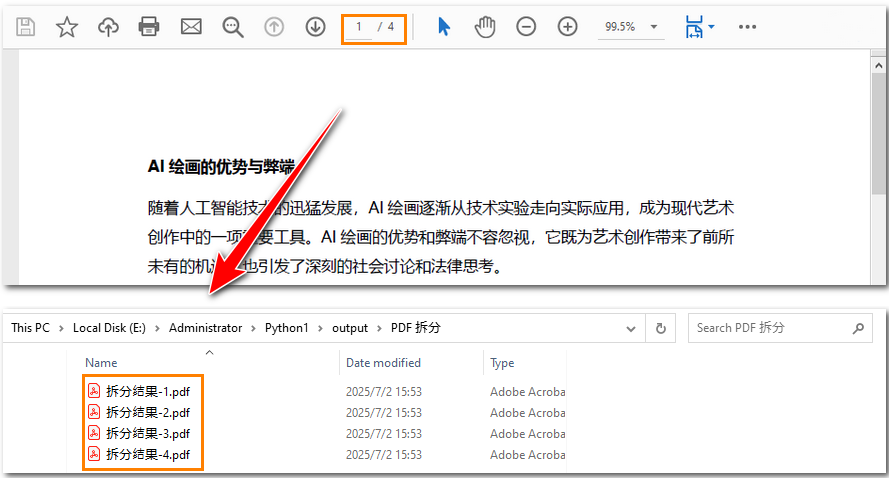
(python 按页拆分 pdf 为单页文件)
关键步骤解析:
创建 pdfdocument 类的对象并加载 pdf 文件。
通过 pdfdocument.split() 方法将 pdf 文档拆分为单页的独立文件。
按指定页范围拆分 pdf
有时 pdf 中的连续几页内容紧密关联,比如一个文档的正文部分,这种情况下不适合简单地将 pdf 拆分成单页文件,而是需要根据指定的页范围进行拆分。比如将封面单独保存、中间几页作为正文,其余页面作为附录单独输出。
完整代码示例 - 将第一页、第二和第三页、剩余页拆分成不同 pdf 文件:
from spire.pdf.common import *
from spire.pdf import *
# 创建一个 pdfdocument 对象
doc = pdfdocument()
# 加载一个 pdf 文件
doc.loadfromfile("/示例文档.pdf")
# 创建三个 pdfdocument 对象
newdoc_1 = pdfdocument()
newdoc_2 = pdfdocument()
newdoc_3 = pdfdocument()
# 将源文件的第一页插入到第一个文档中
newdoc_1.insertpage(doc, 0)
# 将源文件的第2-3页插入到第二个文档中
newdoc_2.insertpagerange(doc, 1, 2)
# 将源文件的剩余页插入到第三个文档中
newdoc_3.insertpagerange(doc, 3, doc.pages.count - 1)
# 保存这三个文档
newdoc_1.savetofile("/pdf 拆分1/拆分结果-1.pdf")
newdoc_2.savetofile("/pdf 拆分1/拆分结果-2.pdf")
newdoc_3.savetofile("/pdf 拆分1/拆分结果-3.pdf")
# 关闭 pdfdocument 对象
doc.close()
newdoc_1.close()
newdoc_2.close()
newdoc_3.close()效果预览:
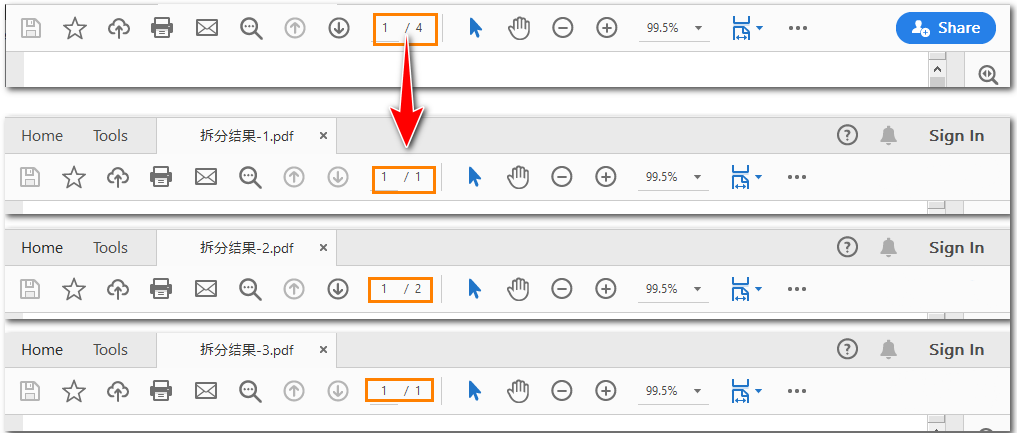
(python 按照指定页面范围拆分 pdf)
关键步骤解析:
- 创建新的 pdfdocument 对象用于保存拆分后的每个文档。
- 通过 pdfdocument.insertpage() 方法将源文档的单个页面插入到新文档中。
- 通过 pdfdocument.insertpagerange() 方法将源文档页面范围插入到新文档中。
pdf 合并实用方法
在 pdf 文件处理中,合并 pdf 文件同样是非常常见的需求。比如将各季度的销售报告合并成全年汇总,或者将多份相关报告合并为一个文件,方便整理与归档。在 python 中,借助 spire.pdf 提供的 pdfdocument.mergefiles() 方法,可以轻松快速地完成 pdf 合并操作。
完整代码示例 - 将三个 pdf 文件合并为一个:
from spire.pdf.common import *
from spire.pdf import *
# 创建pdf文件路径列表
inputfile1 = "/文档.pdf"
inputfile2 = "/示例文档.pdf"
inputfile3 = "/示例文本.pdf"
files = [inputfile1, inputfile2, inputfile3]
# 合并pdf文档
pdf = pdfdocument.mergefiles(files)
# 保存结果文档
pdf.save("/合并pdf.pdf", fileformat.pdf)
pdf.close()效果预览:
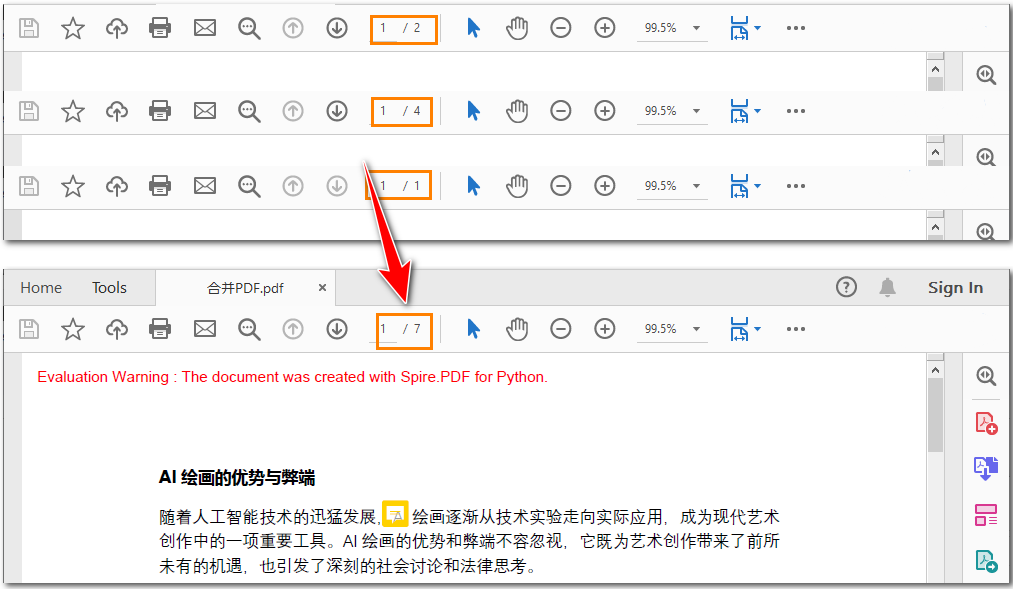
关键步骤解析:
- 确定导入 pdf 文件的路径,并将它们添加到列表中。
- 通过 pdfdocument.mergefiles() 方法将列表中的 pdf 文件合并。
除了使用 pdfdocument.mergefiles() 方法,你还可以通过将复制多个 pdf 文件页面到新文件中的方法实现合并 pdf。
完整代码示例 - 通过循环将每个文档的页面追加到新 pdf:
from spire.pdf.common import *
from spire.pdf import *
# 创建pdf文件路径列表
inputfile1 = "/文档.pdf"
inputfile2 = "/示例文档.pdf"
inputfile3 = "/示例文本.pdf"
files = [inputfile1, inputfile2, inputfile3]
# 加载每个pdf文件并添加到列表中
pdfs = []
for file in files:
pdfs.append(pdfdocument(file))
# 创建一个pdfdocument对象
newpdf = pdfdocument()
# 将加载的pdf文档的页面插入到新的pdf文档中
for pdf in pdfs:
newpdf.appendpage(pdf)
# 保存新的pdf文档
newpdf.savetofile("/复制页面合并pdf.pdf")这两种方法前者更简洁,而循环方法更灵活。
小结
通过本文介绍的方法,你可以轻松实现 pdf 文件的拆分和合并,让日常文档处理更高效、更专业。无论是批量保存扫描件,还是汇总多份报告,使用 python 脚本都能显著提升工作效率。如果需要进一步处理 pdf,比如添加水印、加密保护或提取内容,还可以继续探索 spire.pdf 提供的其他功能,让你的 pdf 管理更加全面、便捷。
到此这篇关于python高效处理pdf合并与拆分的实用方法的文章就介绍到这了,更多相关python pdf合并与拆分内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论