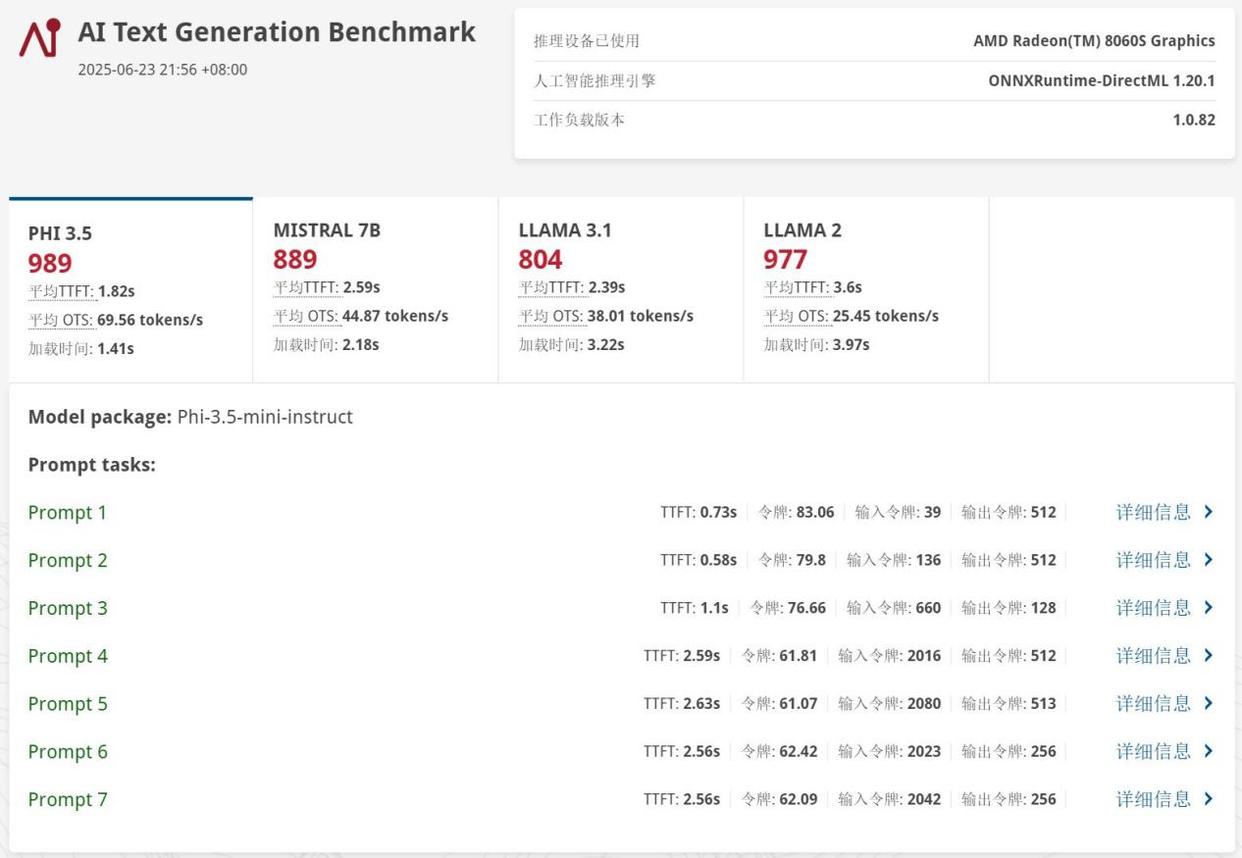
首先通过ul procyon测试了phi-3.5 4b、mistral 7b、llama 3.1 8b以及llama 2 13b四款经典大语言模型,生成速度分别达到了69.56 tokens/s、44.87 tokens/s、38.01 tokens/s以及25.45 tokens/s,速度非常快。另外值得一提的是,即便是rtx 5060笔记本电脑gpu,因为其作为独立显卡也只有可怜的8gb显存,所以也无法正常运行参数量较大的llama 2大模型,而radeon 8060s不仅成功运行,且生成速度能够达到25.45 tokens/s,日常应用完全没有问题。此时,锐龙ai max+ 395平台的独特优势就彻底显现出来了。
接下来我们通过lm studio进行了15b及以下小参数量大语言模型和22b及以上大参数量大语言模型的测试。
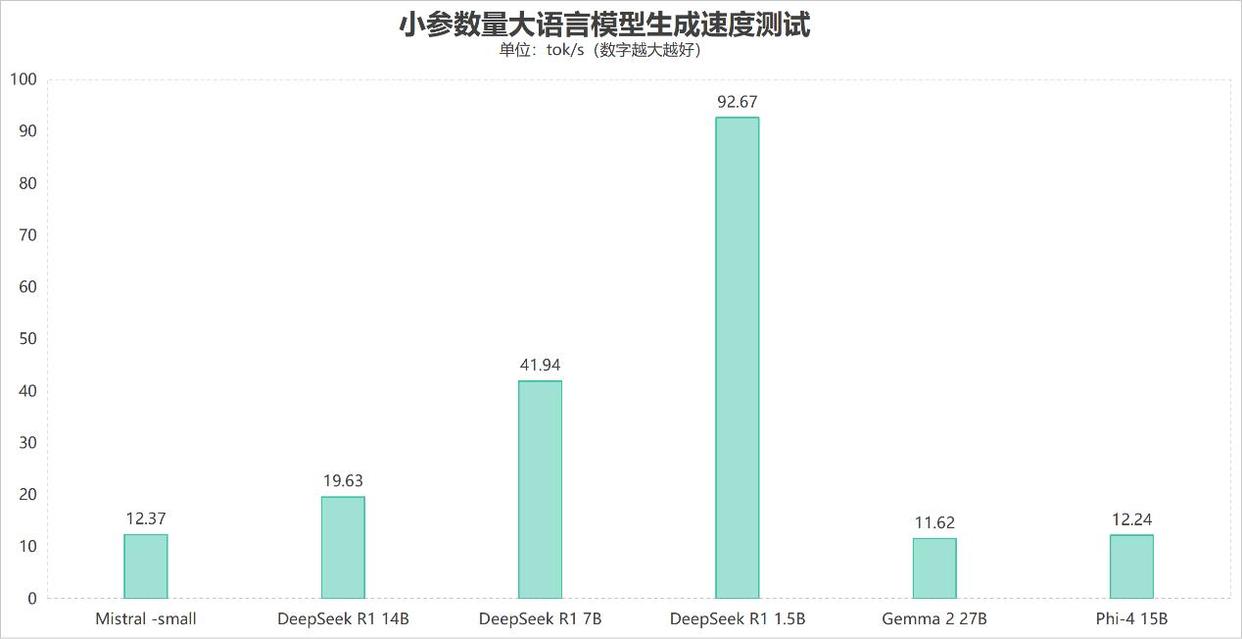
首先在各类小参数量稠密大模型测试中可以看到,锐龙ai max+ 395表现非常出色,凭借内存分配带来的超大显存支持,即便是遇到bf16高精度的mistral-small 24b以及gemma 2 27b大模型,生成速度也分别达到了12.37 tokens/s和11.62 tokens/s,表现出色。而对于更高性能的deepseek r1 14b、phi-4 15b,速度也能达到19.63 tokens/s和12.24 tokens/s;低精度的deepseek r1 7b生成速度更是达到了41.94 tokens/s,而deepseek r1 1.5b则达到了92.67 tokens/s,可见在面对小参数量大模型时,锐龙ai max+ 395无论是面对高精度模型还是低精度模型,都能提供足够快的生成速度。
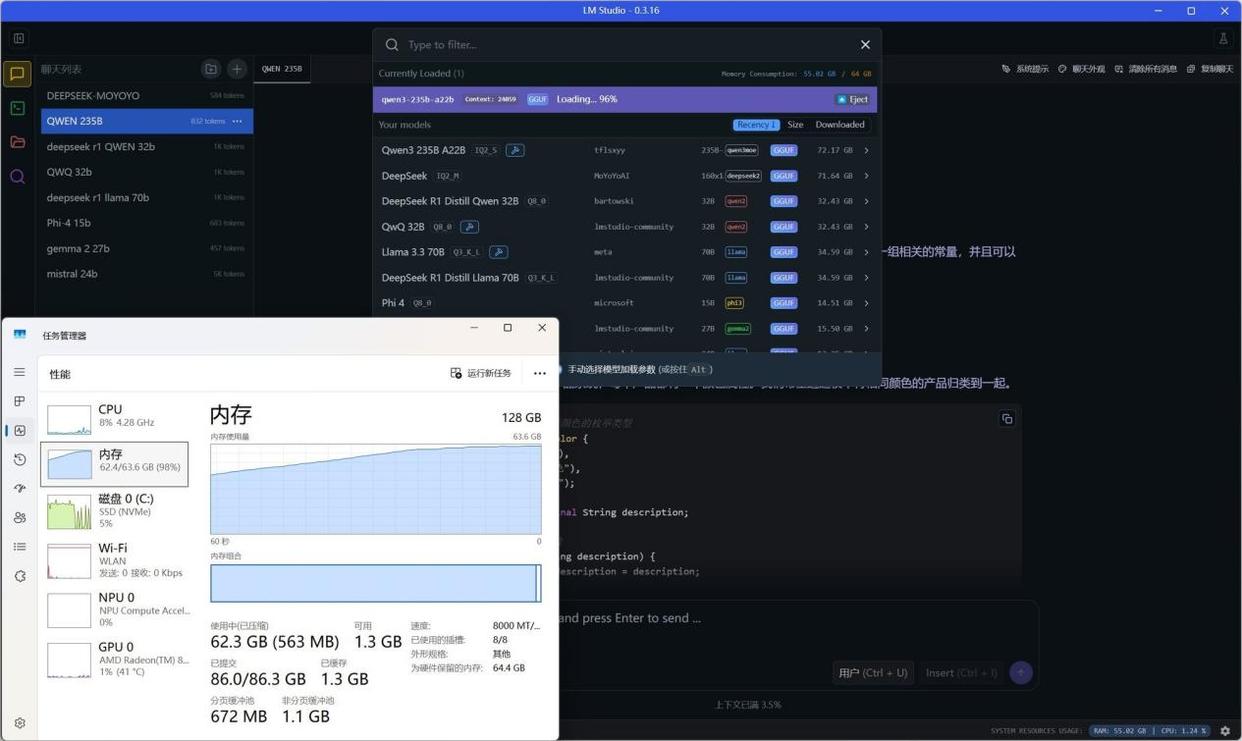
在面对大参数量大语言模型时,其实首要解决的问题不是能不能使用大模型,而是能不能正常加载大模型。就比如rtx 5060笔记本电脑gpu,虽然其性能比radeon 8060s要强,但如果大模型参数量较大,前者大概率也过不了加载这一关,更别提进一步应用了。
从下图可以看到,我们在加载qwen3-235b-a22b-iq2_s的moe混合大模型时,内存峰值占用高达63.6gb,如果没有128gb超大内存支持的话,加载这一关就过不了。
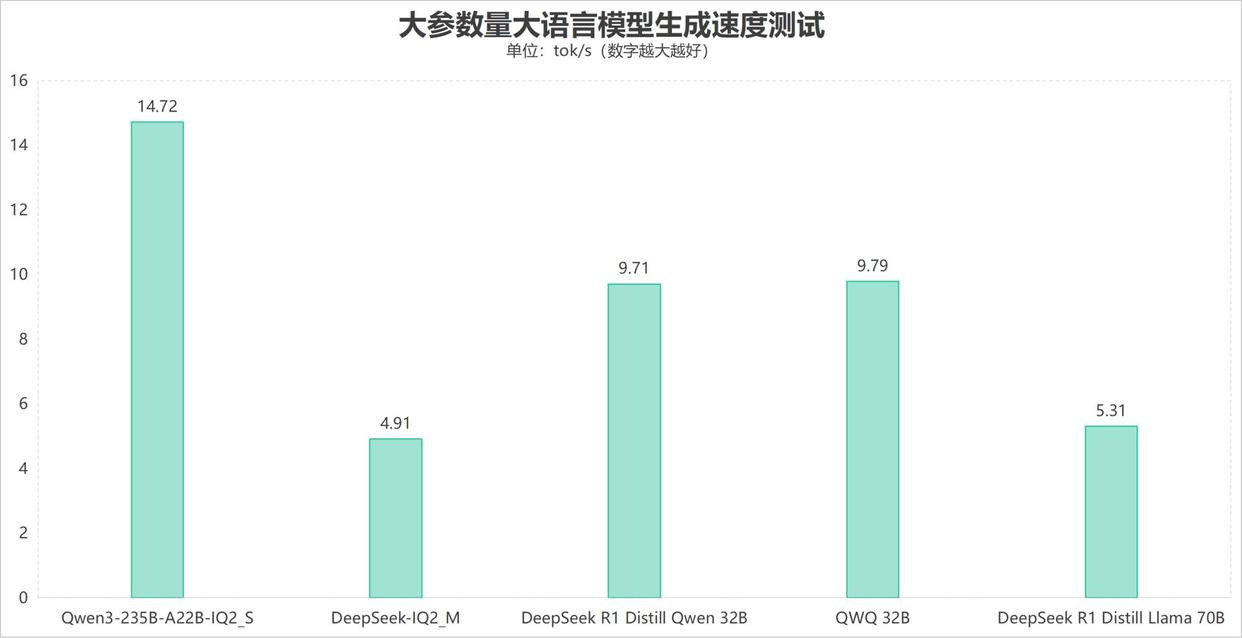
在各类大参数量大语言模型测试中,qwen3-235b-a22b-iq2_smoe模型生成速度达到了14.72 tokens/s,表现出色;deepseek iq2_m、deepseek r1 distill llama 70b大参数量稠密模型也能够正常运行,并且可以达到4.91 tokens/s和5.31 tokens/s的生成速度。而q4量化版本的deepseek r1 qwen 32b蒸馏模型以及qwq 32b大模型生成速度分别可以达到9.71 tokens/s和9.79 tokens/s的生成速度。
另外这里要说明的一点是,qwen3-235b-a22b-iq2_s这个模型虽然参数量达到了235b,但它并非是常见的稠密模型,而是moe(mixtureofexperts)混合专家模型。简单来说,moe模型虽然总参数量很大,但以qwen3-235b-a22b-iq2_s模型为例,它虽然拥有235b总参数量,但运行时实际只会调用22b(模型中a22b标识就表示运行时只会调用22b参数量)的参数进行计算,因此对于硬件的压力要小很多。
也正是因为有着这种大参数、低算力特性,moe模型或许会成为未来大模型发展的主流趋势。
反之,稠密模型每一次计算都会调用所有参数,这也就是为什么235b的qwen3-235b-a22b-iq2_s生成速度反而比deepseek r1 32b、qwq 32b大模型要快的原因。
ai测试的最后一部分,我们使用了针对amd锐龙平台打造的amuse这款stable diffusion工具,它支持文生图、图生图、文生视频等应用,使用起来非常方便。
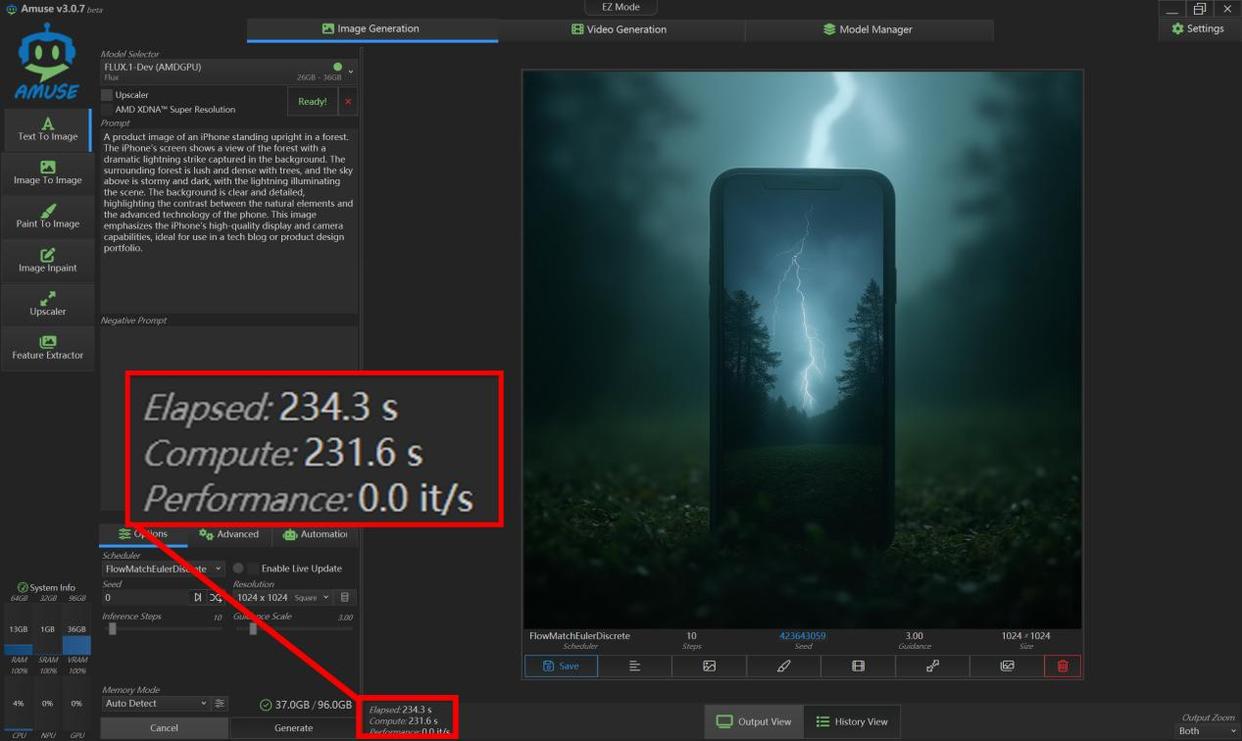
首先我们使用最近大半年非常火爆的flux.1-dev模型进行了文生图测试,实测迭代10步,生成一张1024×1024超清图片用时234.3秒。这个表现虽然不如独显,但在集成显卡里,能顺利完成这一任务的此前没有,radeon 8060s不仅顺利完成,而且效率也还不错,毕竟1024×1024规格的图片生成,在ai文生图应用中算是高负载任务了。
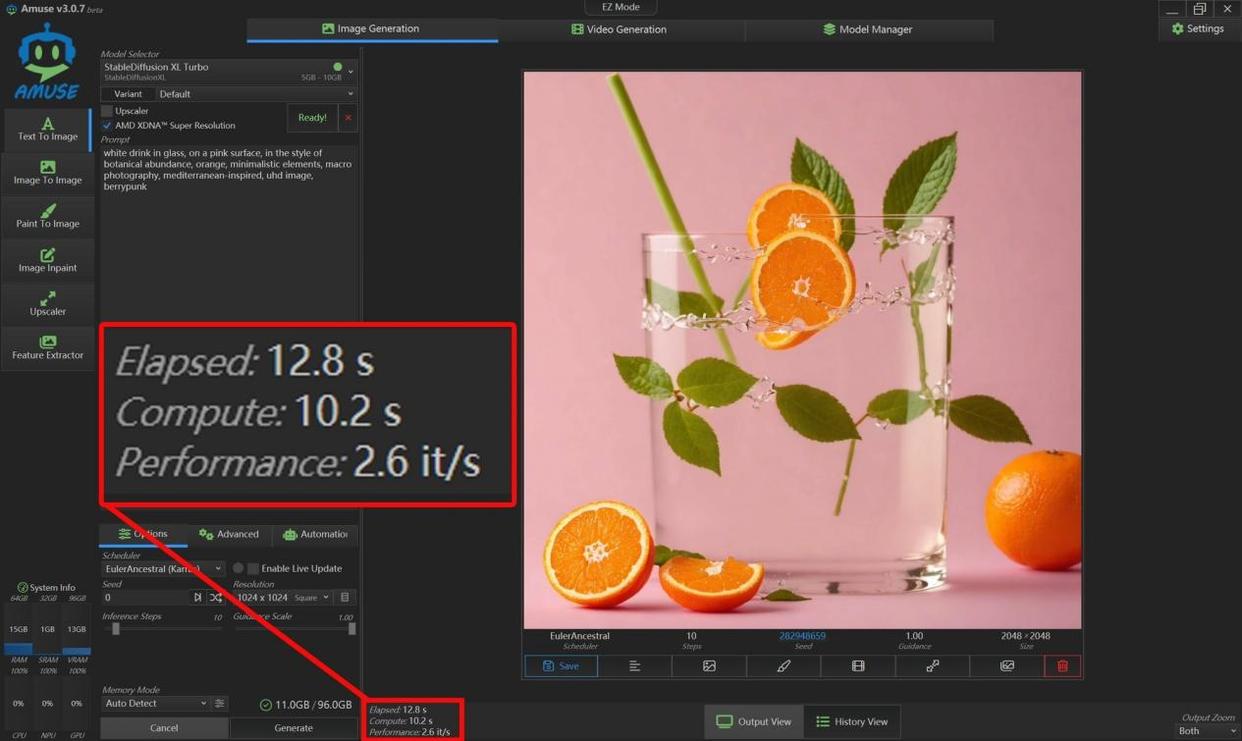
其次我们使用了stable diffusion xl turbo模型,进行了2048x2048规格图片的生成。这款大模型整体精度要低一些,所以对硬件负载的压力不算太高。普通用户使用这类大模型进行文生图就足够了,没必要使用flux.1-dev这种超高精度大模型。
可以看到,stable diffusion xl turbo模型生成2048x2048规格图片耗时仅需12.8秒,每秒迭代次数也达到了2.6次。
总体来说,锐龙ai max+ 395是非常不错的ai计算平台,配合大内存并通过amd统一内存技术分配给显存之后,常规的ai应用基本没有太大压力,完全可以作为个人或者小型工作室、小型企业用户的ai终端设备。尤其相比动辄数万、数十万元的ai一体机来说,14999元的极摩客evo-x2绝对是一个高性价比的解决方案。
同时,这类设备也非常适合ai初学者、初级ai开发者使用。首先,锐龙ai max+ 395平台配合超大内存,完全可以在本地部署多样化的ai大模型,如70b、32b大语言模型,或者flux、stablediffusion等文生图、文生视频大模型。借助lmstudio、comfy-ui等ai工具,轻松实现本地化的ai助手、个人知识库以及图片、视频创作平台的搭建。
其次,超大内存与显存带来了更加出色的ai应用体验,例如用户在实际应用中可以同时加载stable diffusion+whisper+llama这样的混合式ai模型方案,从而用ai解决ai应用的问题,如让ai直接生成提示词,再通过sd进行图片、视频创作。同时锐龙ai max+395平台还支持onnx、directml等多种框架,完美适配windows平台的部署与运行。因此也非常适合多模态ai应用,如扩图、分割、语音识别、图像识别等,节约实验或验证成本,快速完成demo或开源项目的开发。
其三,设备成本支出更低的同时,本地化部署带来的另一大好处就是使用成本几乎为零。用户无需额外支付token费用,也不受网络质量影响。同时拥有更加可靠的用户隐私、数据安全,算法模型数据不容易外泄。
此外,锐龙ai max+ 395的npu也可以参与yolo等适配模型的相关任务,分担负载,从而让多模态应用拥有最优的算力表现。
游戏性能评估
锐龙ai max+ 395集成的radeon 8060s本身拥有相当不错的图形性能,因此对于游戏玩家来说也是不错的选择。所以性能测试的最后一部分,我们进行了四款热门游戏的测试。
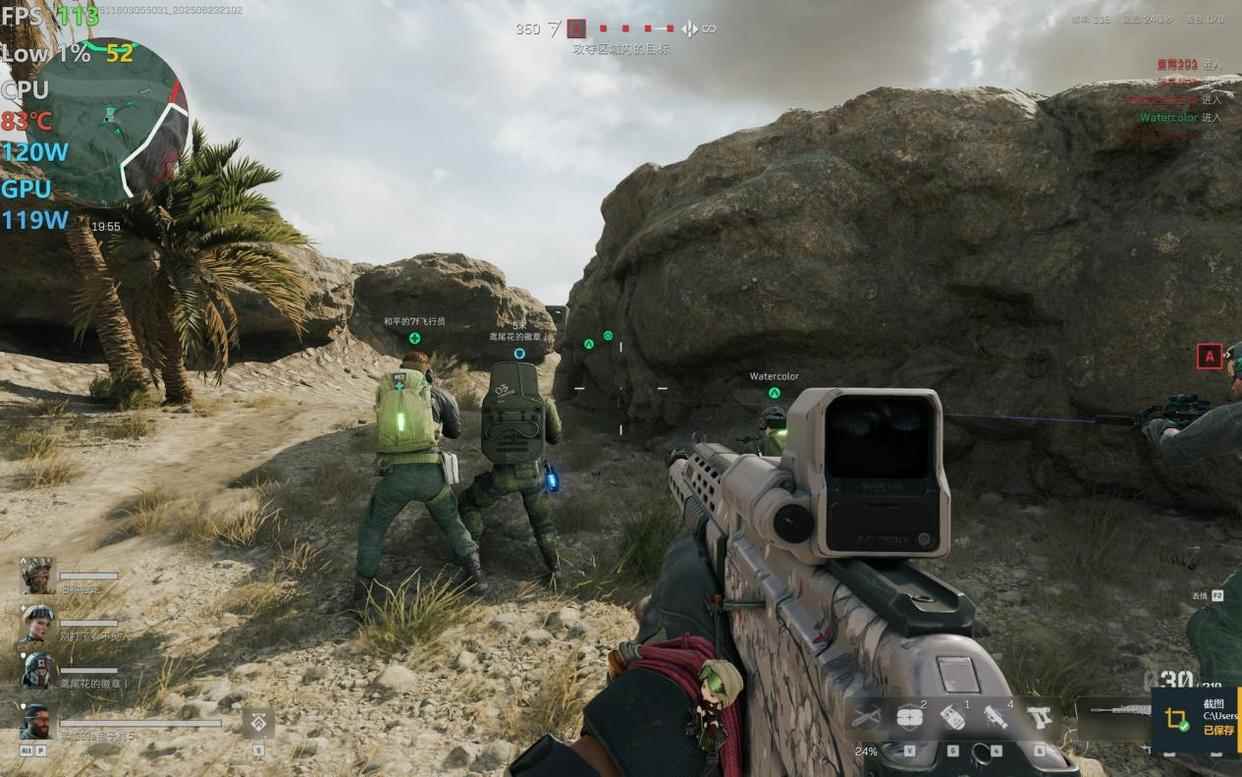
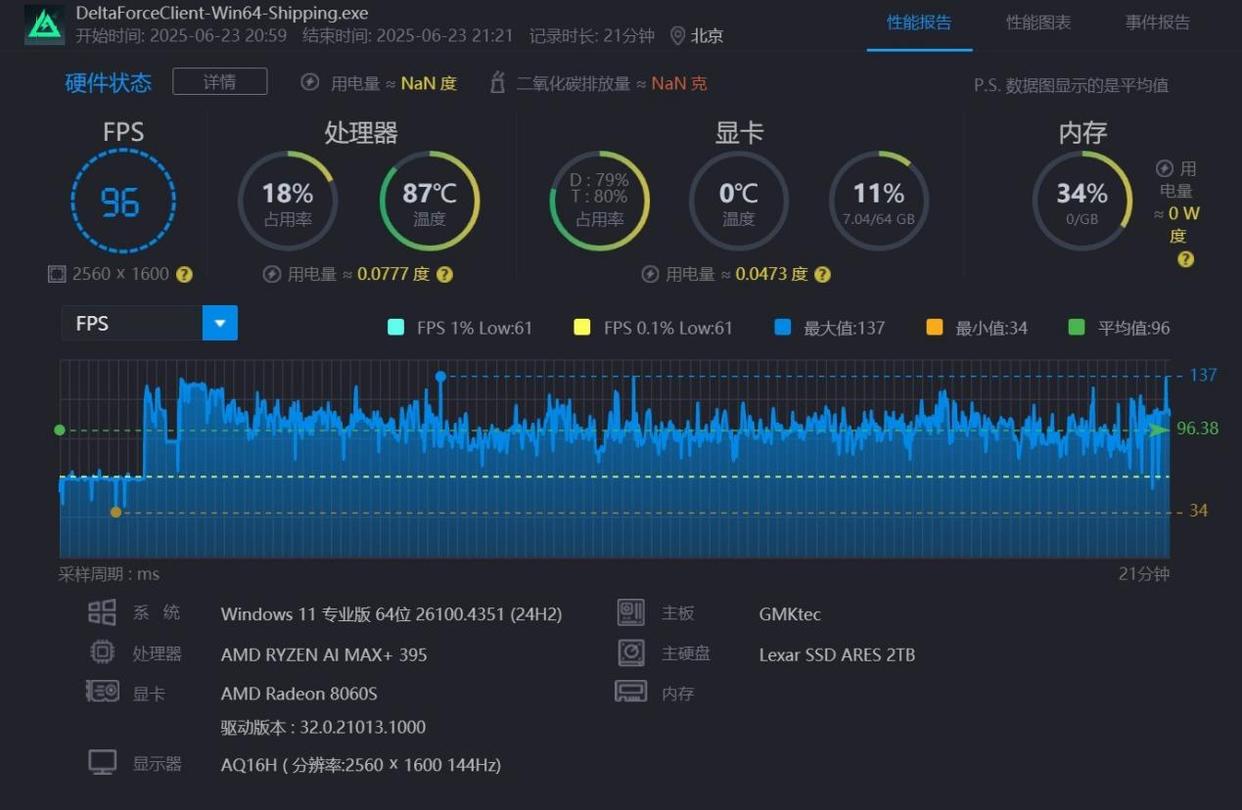
- 《三角洲行动》,极高画质(次高画质),2560x1600分辨率,平均帧率可以达到96fps,流畅运行无压力。
- 《荒野大镖客2》,中等画质,2560x1600分辨率,开启fsr,平均帧率可以达到89fps,运行非常流畅。
- 《赛博朋克2077》,超级画质,未开启光追,2560x1600分辨率,平均帧率可以达到59.23fps,接近60fps的表现已经远超当前其它集成显卡了。
- 《黑神话:悟空》,超高画质(非影视级画质),2560x1600分辨率,平均帧率达到了62fps,可以流畅游玩。
可见极摩客evo-x2不仅拥有出色的ai性能,同时还有着不错的游戏性能,再加上出色的生产力性能,这款产品可以说是相当能打的一款综合性迷你主机了。而且确实不负“桌面ai超算中心”之名!


发表评论