一、io_uring介绍
io_uring是 linux 于 2019 年加入到内核的一种新型异步 i/o 模型,io_uring 主要为了解决 原生aio(native aio) 存在的一些不足之处。下面介绍一下原生 aio 的不足之处:
系统调用开销大:提交 i/o 操作和获取 i/o 操作的结果都需要通过系统调用完成,而触发系统调用时,需求进行上下文切换。在高 iops(input/output per second)的情况下,进行上下文切换也会消耗大量的cpu时间。
仅支持 direct i/o(直接i/o):在使用原生 aio 的时候,只能指定
o_direct标识位(直接 i/o),不能借助文件系统的页缓存(page cache)来缓存当前的 i/o 请求。对数据有大小对齐限制:所有写操作的数据大小必须是文件系统块大小(一般为4kb)的倍数,而且要与内存页大小对齐。
数据拷贝开销大:每个 i/o 提交需要拷贝 64+8 字节,每个 i/o 完成结果需要拷贝 32 字节,总共 104 字节的拷贝。这个拷贝开销是否可以承受,和单次 i/o 大小有关:如果需要发送的 i/o 本身就很大,相较之下,这点消耗可以忽略。而在大量小 i/o 的场景下,这样的拷贝影响比较大。
对应io_uring就有他的优势:
- 减少系统调用:io_uring通过内核态和用户态共享内存的方式进行通信。如下图:

用户态和内核态之间通过共享内存维护了三部分:提交队列、完成队列、提交队列表项数组。
提交队列是一整块连续的内存空间存储的环形队列,用于存放将要执行i/o操作的数据。
完成队列也是一整块连续的内存空间存储的环形队列,其中存放了i/o操作完成返回的结果。
提交队列表项数组是以数组形式将要执行的i/o操作组织在一起,提交队列完成队列分别通过指针指向对应表项(内部通过偏移量实现)完成对应操作。如下图所示:
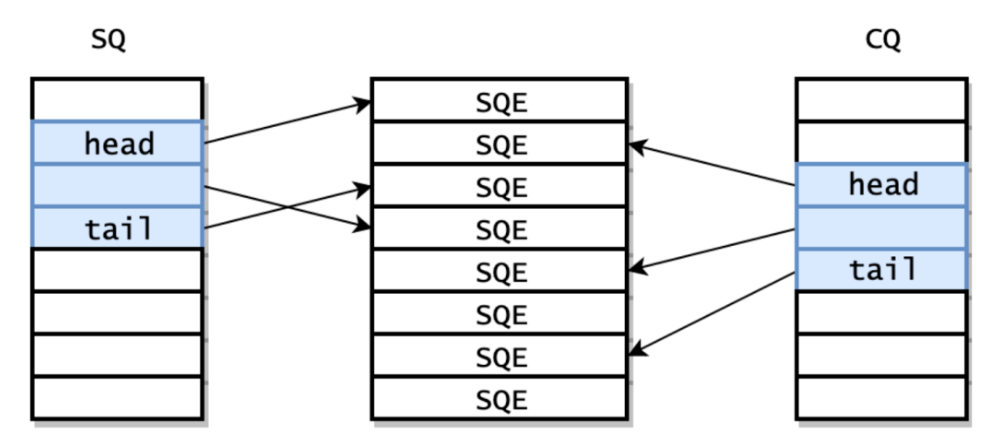
提交队列具体实现为:io_uring_sq结构体。
struct io_uring_sq {
unsigned *khead;
unsigned *ktail;
unsigned *kflags;
unsigned *kdropped;
unsigned *array;
struct io_uring_sqe *sqes;
unsigned sqe_head;
unsigned sqe_tail;
size_t ring_sz;
void *ring_ptr;
unsigned ring_mask;
unsigned ring_entries;
unsigned pad[2];
};提交队列通过struct io_uring_sqe *sqes提交队列表项数组,使用khead、ktail指向对应队头和对尾完成应用层提交的io任务的处理。同理完成队列也是如此,不过是由内核态将对应io事件执行完成后将结果写入到对应表项。应用层通过完成队列表项即可获取到最终结果。
整体流程为:
请求时:1、应用创建sqe,更新sq tail 2、内核消费sqe,更新sq head。内核开始处理任务,处理完成后:1、内核为完成的一个或多个请求创建cqe,更新cq tail 2、应用层消费cqe,更新cq head。
二、liburing安装
上文介绍的io_uring均为内核层支持,在内核层提供了三个api:
io_uring_setup(2)
io_uring_register(2)
io_uring_enter(2)
为方便使用直接安装liburing即可在应用层使用io_uring。liburing为作者axboe封装好的用户态库。
实验环境:vmware 17安装ubuntu22.04 、内核版本:6.8.0-60-generic
选用源码安装方式,安装liburing。
1、获取源码:git clone https://github.com/axboe/liburing.git
2、编译:
cd liburing-master ./configure make -j sudo make install
三、代码实现
#include <stdio.h>
#include <liburing.h>
#include <netinet/in.h>
#include <string.h>
#include <unistd.h>
#define buffer_length 1024
#define entries_length 1024
#define event_accept 0
#define event_read 1
#define event_write 2
// io事件信息
struct req_info{
int fd;
int event;
};
// 初始化tcp fd
int init_server(unsigned int port){
int socket_fd = socket(af_inet, sock_stream, 0);
struct sockaddr_in serveraddr;
memset(&serveraddr, 0, sizeof(struct sockaddr_in));
serveraddr.sin_addr.s_addr = htonl(inaddr_any);
serveraddr.sin_family = af_inet;
serveraddr.sin_port = htons(port);
if(-1 == bind(socket_fd, (struct sockaddr *)&serveraddr, sizeof(struct sockaddr))){
perror("bind error!\n");
}
listen(socket_fd, 10);
return socket_fd;
}
// 设置accept事件
int set_event_accept(struct io_uring *ring, int sockfd, struct sockaddr* addr, socklen_t *addrlen, int flags){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
struct req_info accept_info = {
.fd = sockfd,
.event = event_accept
};
memcpy(&sqe->user_data, &accept_info, sizeof(struct req_info));
io_uring_prep_accept(sqe, sockfd, addr, addrlen, flags);
return 0;
}
// 设置recv事件
int set_event_recv(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
struct req_info recv_info = {
.fd = sockfd,
.event = event_read
};
memcpy(&sqe->user_data, &recv_info, sizeof(struct req_info));
io_uring_prep_recv(sqe, sockfd, buf, len, flags);
return 0;
}
// 设置send事件
int set_event_send(struct io_uring *ring, int sockfd, void *buf, size_t len, int flags){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
struct req_info send_info = {
.fd = sockfd,
.event = event_write
};
memcpy(&sqe->user_data, &send_info, sizeof(struct req_info));
io_uring_prep_send(sqe, sockfd, buf, len, flags);
return 0;
}
int main(int argc, void *argv[]){
unsigned int port = 9999;
int sockfd = init_server(port);
struct io_uring_params params;
memset(¶ms, 0, sizeof(struct io_uring_params));
// 初始化io_uring 其中包含了sq和cq
struct io_uring ring;
io_uring_queue_init_params(entries_length, &ring, ¶ms);
struct sockaddr_in clientaddr;
socklen_t len = sizeof(clientaddr);
set_event_accept(&ring, sockfd, (struct sockaddr*)&clientaddr, &len, 0);
while(1){
char buffer[buffer_length] = {0};
// 事件提交
io_uring_submit(&ring);
// 等待事件完成,其他开发场景下非必要情况无需等待
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe);
// 获取完成事件
struct io_uring_cqe *cqe_list[128];
int nready = io_uring_peek_batch_cqe(&ring, cqe_list, 128);
// echo逻辑处理
for(int i = 0; i < nready; ++i){
struct io_uring_cqe *entries = cqe_list[i];
struct req_info result;
memcpy(&result, &entries->user_data, sizeof(struct req_info));
if(result.event == event_accept){
printf("accept client\n");
set_event_accept(&ring, sockfd, (struct sockaddr*)&clientaddr, &len, 0);
int connfd = entries->res;
set_event_recv(&ring, connfd, buffer, buffer_length, 0);
}else if(result.event == event_read){
int connfd = entries->res;
if(connfd == 0){
printf("close fd:%d\n", result.fd);
close(result.fd);
}else if(connfd > 0){
printf("recv: len:%d, data:%s\n", connfd, buffer);
set_event_send(&ring, result.fd, buffer, connfd, 0);
}else{
printf("error recv!\n");
close(result.fd);
}
}else if(result.event == event_write){
int ret = entries->res;
printf("set_event_send ret: %d, %s\n", ret, buffer);
set_event_recv(&ring, result.fd, buffer, buffer_length, 0);
}
}
// 清除完成队列中完成表项,以免事件重复处理
io_uring_cq_advance(&ring, nready);
}
return 0;
}更多内容可参考:0voice · github
到此这篇关于异步io框架io_uring实现tcp服务器的文章就介绍到这了,更多相关io_uring tcp服务器内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论