一、主从复制
mysql主从复制原理
mysql的主从复制和mysql的读写分离两者有着紧密联系,首先要部署主从复制,只有主从复制完成了,才能在此基础上进行数据的读写分离。
(1)mysql 支持的复制类型
①基于语句的复制。在主服务器上执行的 sql 语句,在从服务器上执行同样的语句,mysql 默认采用基于语句的复制,效率比较高。
②基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍
③混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
(2)复制工作过程
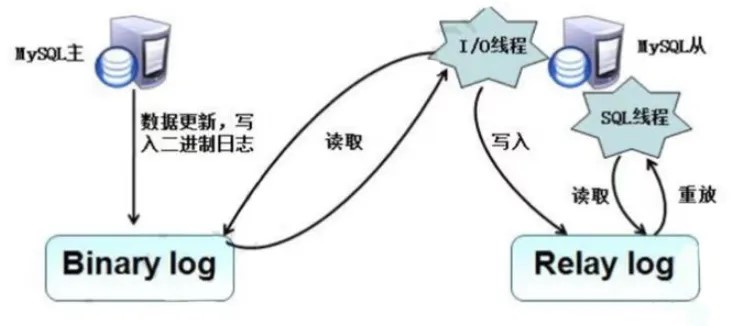
①在每个事务更新数据完成之前,master 将这些改变记录进二进制日志。写入二进制日志完成后,master 通知存储引擎提交事务。
②slave 将 master 的 binary log 复制到其中继日志(relay log)。首先,slave 开始一个工作线程–i/0 线程,i/0 线程在 master 上打开一个普通的连接,然后开始 binlog dump process。binlog dump process 从 master 的二进制日志中读取事件,如果已经跟上 master,它会睡眠并等待 master 产生新的事件。i/0 线程将这些事件写入中继日志。
③ sql slave thread(sql 从线程)处理该过程的最后一步。sql 线程从中继日志读取事件,并重放其中的事件而更新 slave 数据,使其与 master 中的数据保持一致。只要该线程与 i/0线程保持一致,中继日志通常会位于os 的缓存中,所以中继日志的开销很小。复制过程有一个很重要的限制,即复制在slave 上是串行化的,也就是说 master 上的并行更新操作不能在 slave 上并行操作。
实验案例
1.主从复制实验本实验用1台主mysql主机,ip:192.168.10.101
2台从mysql主机,ip:192.168.10.102和192.168.10.103
2.配置master主服务器
(1)在/etc/my.cnf 中修改或者增加下面内容
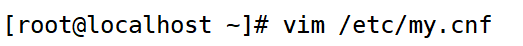

重启服务

登录mysql程序给从服务器授权


mysql 8.0 默认使用 caching_sha2_password 认证插件,将mysql_native_password 替换为旧版认证插件,确保从库能兼容


其中 file 列显示日志名,position 列显示偏移量,这两个值在后面配置从服务器的时候需要。slave 应从该点上进行新的更新。
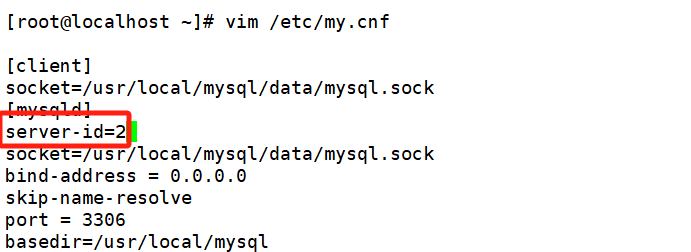
3.配置从服务器
在 slave1、slave2 服务器上面分别执行下面步骤
(1)在/etc/my.cnf 中修改或者增加下面内容,这里要注意 server-id 不能相同。
重启服务

登录 mysql,配置同步


开启同步

查看 slave 状态,确保以下两个值为 yes
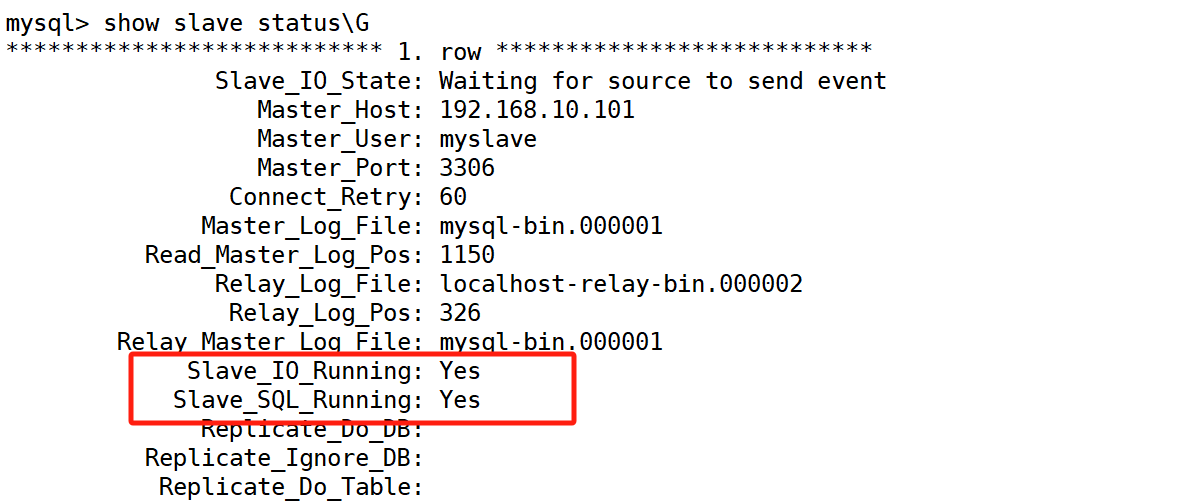
验证主从复制效果
在主、从服务器上登录mysql
在主上创建库,表,数据

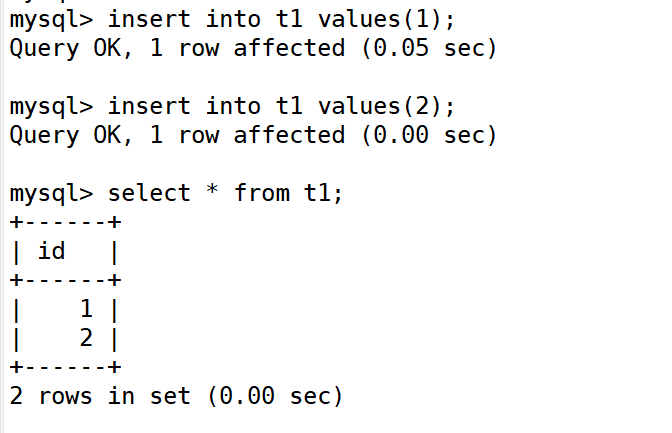
在从服务器102上查看

二、读写分离
简单来说,读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性查询,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性查询导致的变更同步到集群中的从数据库。
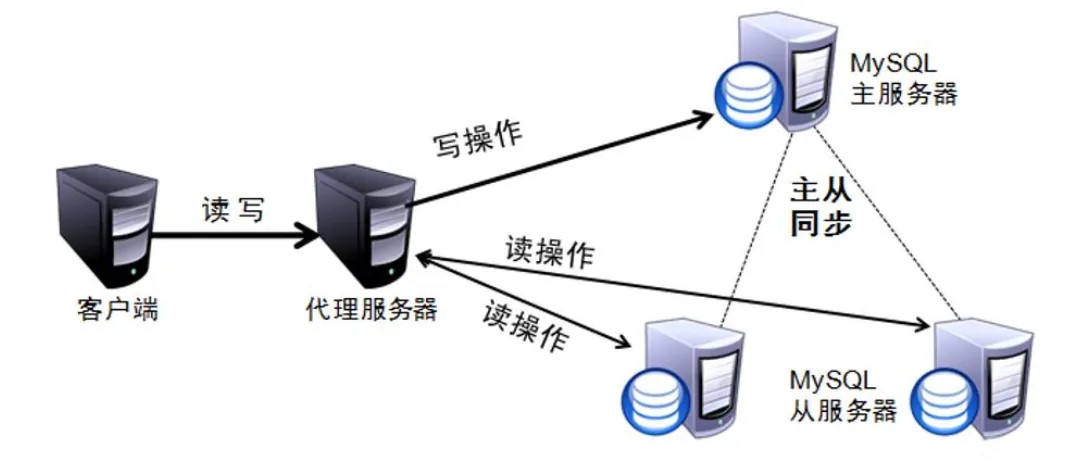
目前较为常见的 mysql 读写分离分为两种
(1)基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。优点是性能较好,因为在程序代码中实现,不需要增加额外的设备作为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。
(2)基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有两个代表性程序。
① mysql-proxy。mysql-proxy 为 mysql 开源项目,通过其自带的 lua 脚本进行 sql 判断,虽然是 mysql 官方产品,但是 mysql 官方并不建议将 mysql-proxy 用到生产环境。
②amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由 java 语言进行开发,阿里巴巴将其用于生产环境。它不支持事务和存储过程。经过上述简单的比较,通过程序代码实现 mysql 读写分离自然是一个不错的选择,但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的java应用,如果在程序代码中实现读写分离对代码改动就较大。所以,像这种应用一般会考虑使用代理层来实现。本章后续案例通过 amoeba 实现。
③ mycat是一款开源的分布式关系型数据库中间件,主要用于解决大规模数据存储和高效查询的需求。它支持分布式 sql 查询,兼容 mysql通信协议,能够通过数据分片提高数据查询处理能力。mycat的前端用户可以将其视为一个数据库代理,使用 mysql 客户端工具和命令行访问,而后端则可以通过 mysql 原生协议与多个 mysql 服务器通信,或者使用jdbc协议与大多数主流数据库服务器通信
- mycat是目前最流行的分布式数据库中间插件,是一个开源的分布式数据库系统,是一个实现了 mysql协议的服务器。前端用户可以把它看作一个数据库代理,用 mysql 客户端工具和命令行访问,其后端可以用
- mysql 原生协议与多个mysql服务器通信,也可以用 jdbc协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为n个小表,存储在后端 mysql服务器里或者其他数据库里。
- mycat 发展到目前,已经不是一个单纯的 mysql 代理了,它的后端可以支持mysql、sql server、0racle、db2、postgresql 等主流数据库,也支持 mongodb这种新型 nosql方式的存储。未来,它还会支持更多类型的存储。
不过,无论是哪种存储方式,在最终用户看,mycat里都是一个传统的数据库表,支持标准的sql语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
实验案例
在基于读写分离的基础上做
在第四台客户机充当中间代理mycat主机:192.168.10.104
安装mycat2

mycat 需要依赖于java,因此需要在读写分离代理所在的系统预先安装java环境

安装并配置mycat 软件
unzip 解开后 mycat2 安装包,将其移动到目录“/usr/local”
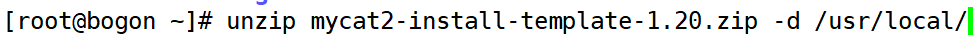

把依赖包 mycat2-1.21-release-jar-with-dependencies.jar 和mysql-connector-java-8.0.18.jar,原样移动或者复制到目录"/usr/local/mycat/lib’

为 mycat 命令添加执行权限

到目前为止,安装的步骤基本上算是完成了,任意命令行下执行指令“mycat -h”验证安装的正确性

关闭防火墙
设置mycat读写分离
mycat2读写分离配置可分为:创建数据库连接账号、启动mycat2与读写分离配置等几个步骤
1)创建 mycat2工作所必须的账号启动 mycat2 服务,需要有真实的数据库服务器支撑才能运行,因此,需要在 mysql 服务器(其它被 mycat2 支持的数据库也如此)创建账号并给账号授权,然后在 mycat2 所在的宿主系统用 mysql,客户端用创建好的账号远程进行连接,验证账号的有效性和正确性。
在前边,我们已经做好了 mysql数据库间的主从同步,因此创建 mycat2 所需账号的操作只需也只能在主数据库上进行,具体的指令如下:


2)启动 mycat2
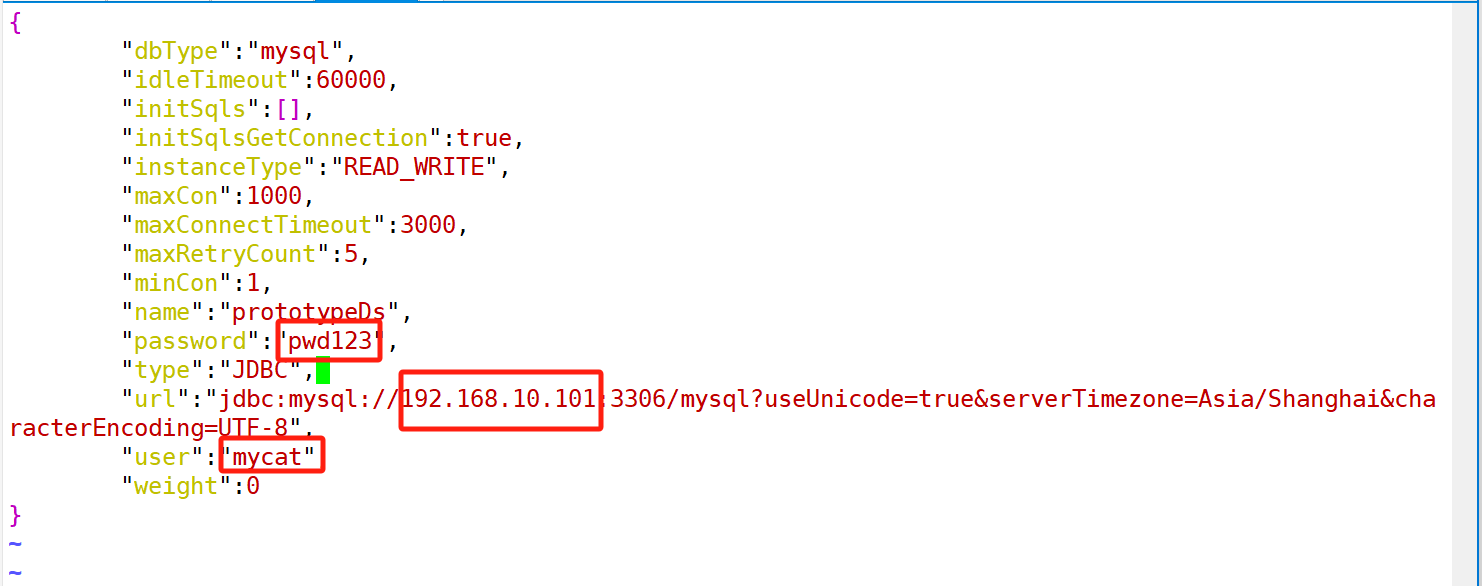
与 mycat1.x版本相比,mycat2 的配置基本不需要手动去修改配置文件,而是可以在 mycat2 启动之后,登录 mycat 管理后台,用 sql 指令或者客户端工具进行配置。在启动 mycat2 之前,需要对原型库的数据源做相应的修改,修改的项主要是主数据库的连接信息,一个完整的修改过的原型数据源文件“/usr/local/mycat/conf/datasources/prototypeds.datasource.json”的内容如下:

因为已经对系统变量做了设置,所以在任意路径执行“mycat start”就可以启动 mycat2。在 mycat2的安装目录“/usr/local/mycat”下,存在目录“logs”打开此目录中的日志文件“wrapper.log’,可了解 mycat2 服务的运行状
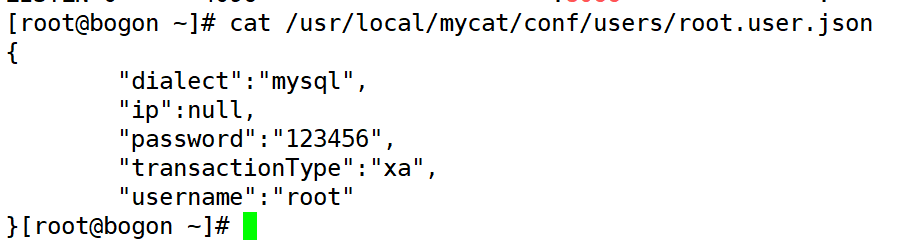
用 mysql, 客户端工具连接 mycat 的服务端口 tcp 8066、用户名与密码在配置文件“/usr/local/mycat/conf/users/ root.user.json’
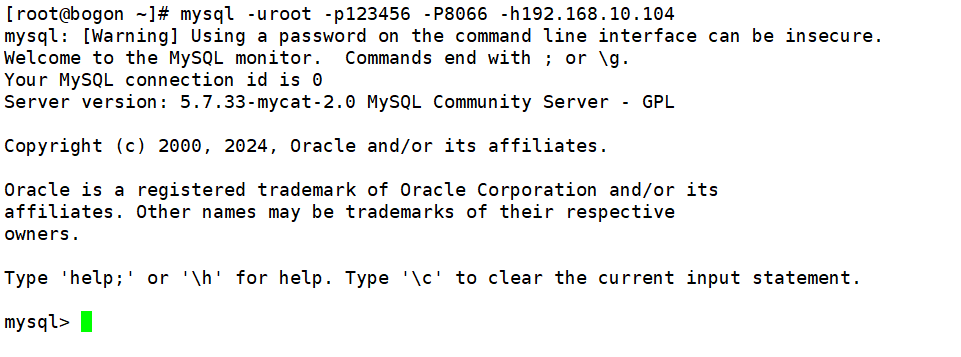
用命令行连接 mycat 管理后台的指令为“mysql -uroot -p123456 -p8066 -h192.168.10.104 ”,ip指向mycat主机,进入用户交互界面,表明 mycat2 运行正常,可在此交互界面进行读写分离配置
3)mycat2配置读写分离
两种配置 mysql读写分离的方法,一种是直接在 mycat 的配置目录“/usr/1ocal/mycat/conf”的子目录编辑相关的文本文件(mycat1.x版本只用这种方法):另一种登录到 mycat 交互界面,用特殊语法的 sql,命令进行配置。本教程采用第二种方法,直接在 mycat 的交互界面输入命令。
第一步:mycat 增加数据源
需要正确输入的数据主要包括:mysql 主从数据库的 ip 地址、数据库库名(schema)、数据库账号、数据库密码(生产数据库请使用复杂密码)、实例类型(read、write或 read_write)。下边是添加一个主库源和两个从库源的具体指令:
增加主库master:

增加从库slavel和 slave2:

查看数据源信息:
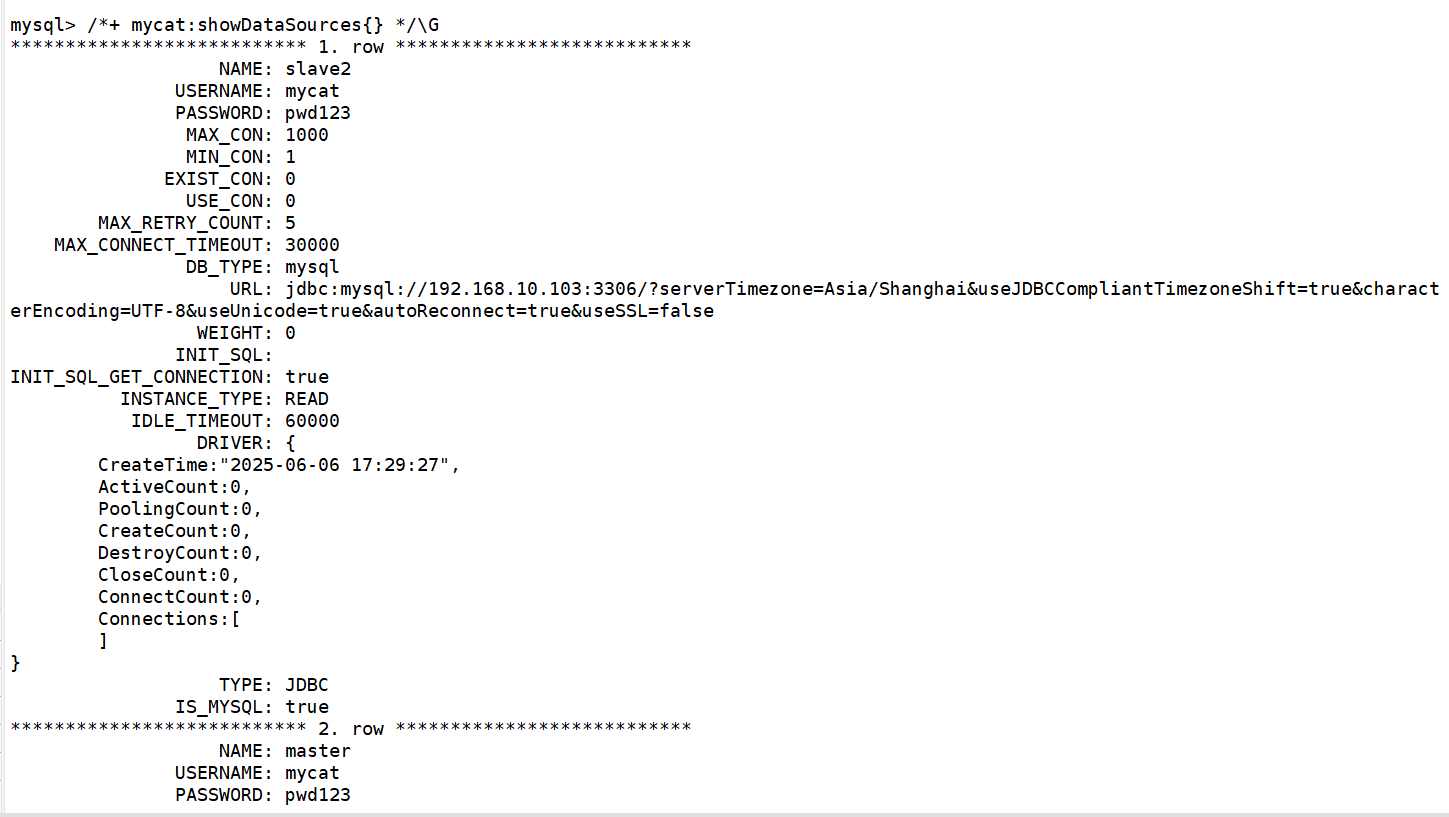
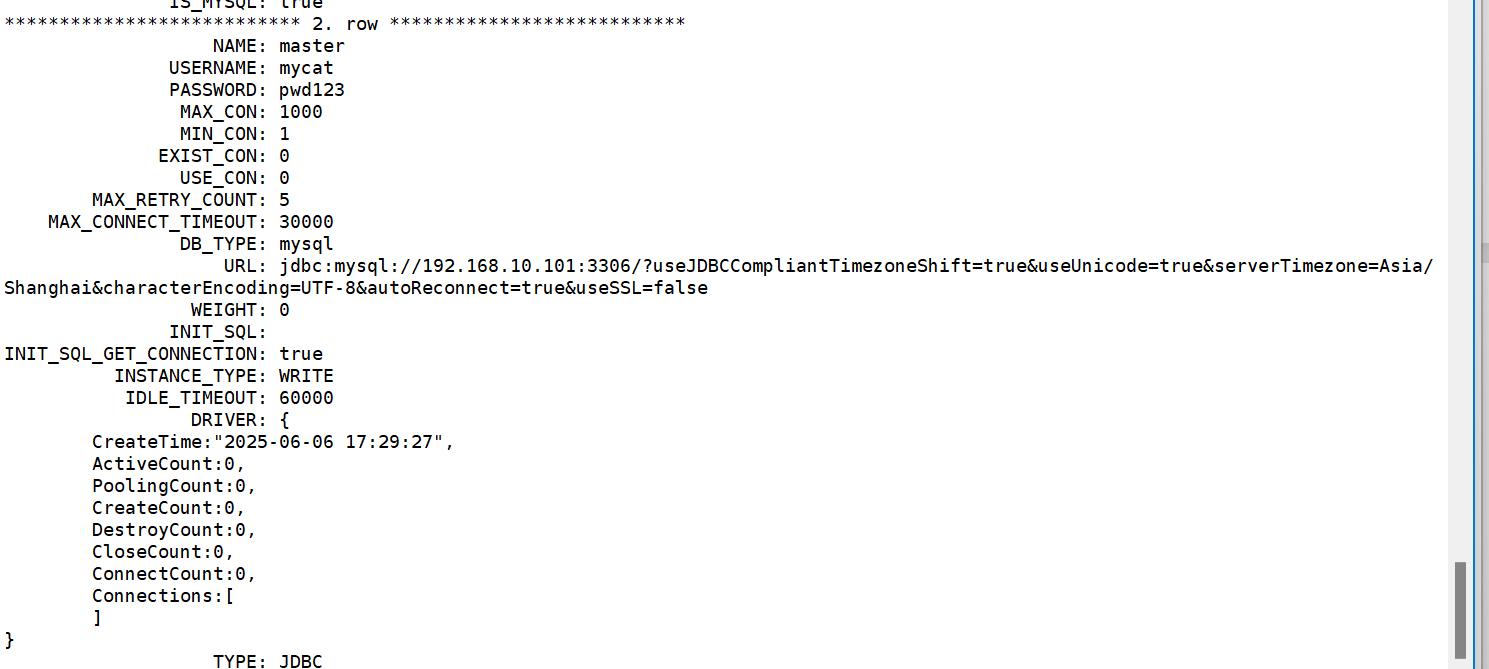
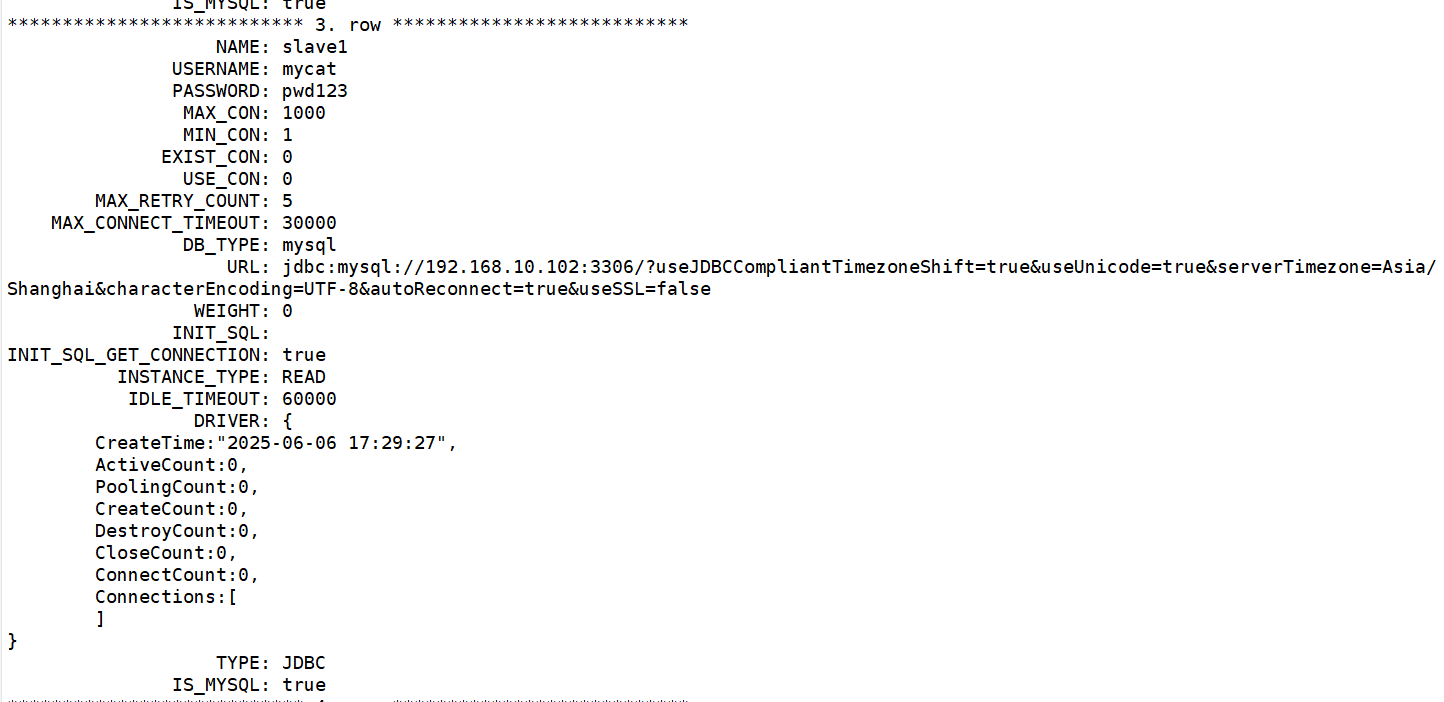
如数据源配置有误可使用” /* + mycat:resetconfig{ } */;“进行重置
正确执行完上面三条 sql语句以后,在目录“/usr/local/mycat/conf/datasources”下自动生成三个文本文件,文件名以已经执行的sql 语句中“name”的键值做前缀

第二步:创建 mycat 集群
在本案例中,集群成员包括一个主库与两个从库。根据业务场景,也可以创建多个集群,充分、有效的利用系统资源。创建 mycat 集群的 sql语句如下:

上述 sql, 语句执行完以后,将在目录“/usr/local/mycat/conf/clusters自动生成 mycat 集群配置文件“cls01.cluster.json
查看并修改集群配置


修改负载均衡的默认策略为轮询


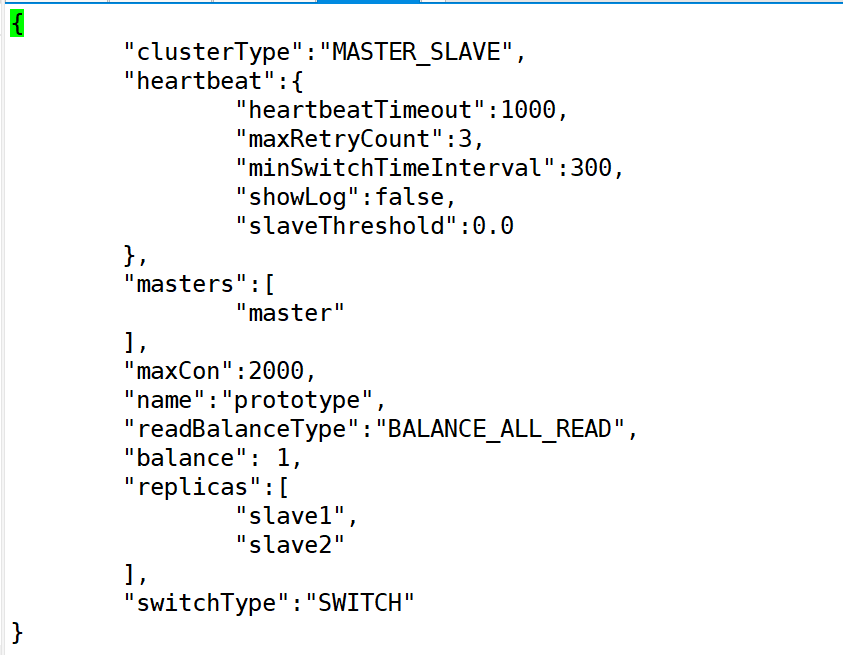
修改配置后需重启 mycat
验证mycat读写分离
1)登录 mycat 集群,创建测试库和测试表
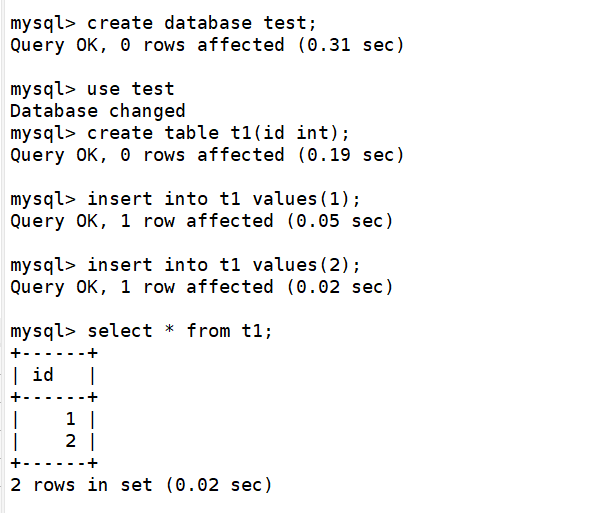
创建库和表的操作会路由到 master 执行,并被同步到slave 节点
2)停止salvel和slave2的主从同步
在102和103mysql上

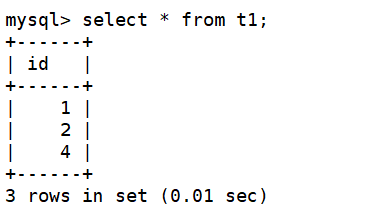
3)在 master 和 slave1、slave2 创建测试数据
在slave1:102上添加数据4

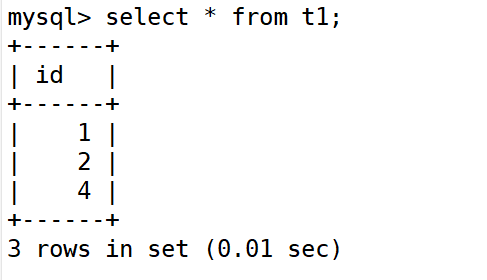
在slave2:103上添加数据6

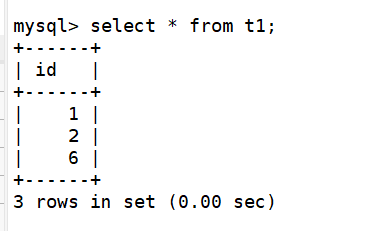
3)测试读操作登录 mycat 集群,查询 test.t1 的数据
第一次查询
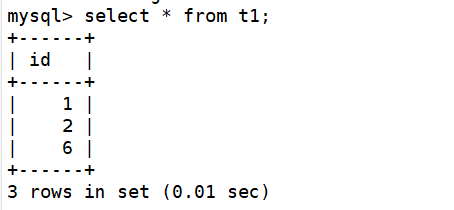
第二次查询
可以看到轮询的查询模式
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论