longadder 原理与应用详解
一、设计背景与核心思想
1. 传统原子类的性能瓶颈
- atomicinteger/atomiclong 基于 cas 实现
- 高并发场景缺陷:
- cas 失败率随竞争加剧指数上升
- cpu 空转消耗大量资源
- 缓存一致性流量(mesi协议)导致总线风暴
2. longadder 设计目标
- 降低竞争:通过数据分片分散写压力
- 空间换时间:牺牲部分内存换取更高吞吐
- 最终一致性:允许读取结果存在短暂误差
二、实现原理剖析
1. 核心数据结构
// 基础值(无竞争时直接操作)
transient volatile long base;
// 分片单元数组(应对高并发)
transient volatile cell[] cells;
// 分片单元结构(避免伪共享)
@jdk.internal.vm.annotation.contended
static final class cell {
volatile long value;
cell(long x) { value = x; }
}2. 分段累加流程
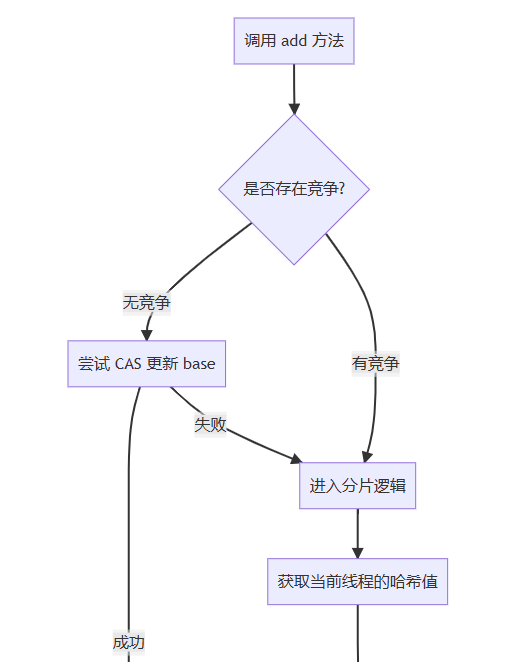
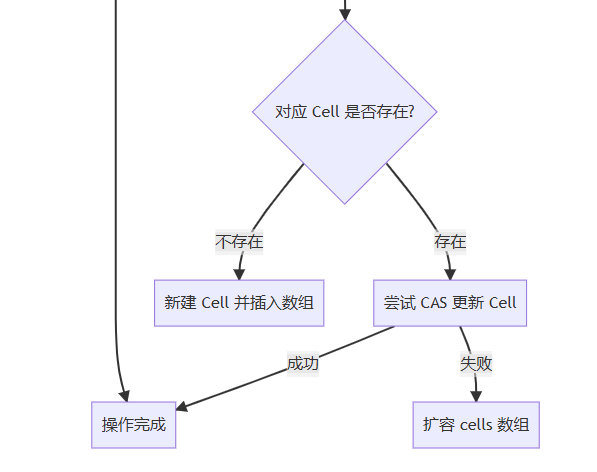
3. 伪共享解决方案
- 问题根源:不同线程的变量共享同一缓存行(通常 64 字节)
- 优化方案:
- 使用
@contended注解自动填充 - 每个 cell 独占缓存行
- 内存布局示意:
- 使用
| cell1 (64字节) | cell2 (64字节) | ... |
三、关键操作解析
1. 累加操作(add)
public void add(long x) {
cell[] cs; long b, v; int m; cell c;
if ((cs = cells) != null ||
!casbase(b = base, b + x)) {
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getprobe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longaccumulate(x, null, uncontended);
}
}执行策略:
- 优先尝试更新 base
- 失败后定位到线程对应的 cell
- 多级失败后触发数组扩容
2. 取值操作(sum)
public long sum() {
cell[] cs = cells;
long sum = base;
if (cs != null) {
for (cell c : cs)
if (c != null) sum += c.value;
}
return sum;
}特点:
- 非原子快照(可能包含进行中的更新)
- 时间复杂度 o(n)(需遍历所有 cell)
四、示例
import java.util.concurrent.executorservice;
import java.util.concurrent.executors;
import java.util.concurrent.timeunit;
import java.util.concurrent.atomic.longadder;
public class simplelongadderexample {
public static void main(string[] args) throws interruptedexception {
// 1. 创建longadder实例
longadder counter = new longadder();
// 2. 创建线程池(模拟并发请求)
executorservice executor = executors.newfixedthreadpool(10);
// 3. 提交100个累加任务
for (int i = 0; i < 100; i++) {
executor.submit(() -> {
// 每个任务累加1000次
for (int j = 0; j < 1000; j++) {
counter.increment(); // 等同于add(1)
}
});
}
// 4. 关闭线程池并等待任务完成
executor.shutdown();
executor.awaittermination(1, timeunit.minutes);
// 5. 输出最终结果
system.out.println("最终计数: " + counter.sum()); // 应输出100000
}
}五、性能对比数据
测试环境:
- cpu:8 核 intel i9-9900k
- 内存:32gb ddr4
- jvm:openjdk 17
- 测试用例:32 线程执行 1 亿次累加
| 实现方案 | 耗时 (ms) | 吞吐量 (ops/ms) | 内存占用 |
|---|---|---|---|
| synchronized | 4,520 | 22,123 | 低 |
| atomiclong | 1,280 | 78,125 | 低 |
| longadder | 235 | 425,531 | 中 |
| threadlocal 优化 | 182 | 549,450 | 高 |
六、应用场景指南
1. 推荐使用场景
| 场景类型 | 典型用例 | 优势说明 |
|---|---|---|
| 高频计数器 | 网站 pv/uv 统计 | 分散写竞争 |
| 监控指标采集 | qps/tps 统计 | 允许最终一致性 |
| 分布式限流 | 令牌桶算法实现 | 避免 cas 失败风暴 |
| 大数据聚合 | 实时计算中间结果 | 支持快速并行累加 |
2. 不适用场景
| 场景类型 | 典型用例 | 问题分析 |
|---|---|---|
| 精确原子操作 | 库存扣减 | sum() 非原子快照 |
| 读多写少 | 配置项更新 | atomiclong 更高效 |
| 内存敏感场景 | 海量独立计数器 | cell 数组内存开销大 |
七、实现原理总结
| 设计要点 | 实现方案 | 解决的问题 |
|---|---|---|
| 竞争分散 | 分片 cell 数组 | 降低 cas 失败率 |
| 伪共享预防 | @contended 注解 | 提升缓存利用率 |
| 动态扩容 | 按需创建 cell | 平衡性能与内存 |
| 延迟初始化 | 初始使用 base 变量 | 减少内存开销 |
| 最终一致性 | sum() 合并所有 cell | 保证最终结果正确性 |
通过理解 longadder 的设计哲学和实现细节,开发者可以在高并发场景中做出更优的技术选型,在保证线程安全的前提下实现 5-10 倍的性能提升。关键是要根据实际业务场景的读写比例、一致性要求和资源限制进行合理选择。
到此这篇关于高并发计数器longadder 实现原理与使用场景详解的文章就介绍到这了,更多相关longadder原理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论