etl——extract, transform, load,即“提取、转换、加载”
一、全量同步(t+1)
逻辑:用源表的数据直接覆盖目标表。
实现的逻辑:在往目标表中插入数据之前,【先清空目标表】,然后查询源表的数据,直接插入目标表。适用于数据量小的情况。
(一)全量同步步骤
1.创建源表
drop table emp_source; create table emp_source as select e.*, sysdate create_date, sysdate last_update_date from emp e where 1 = 2; insert into emp_source select e.*, sysdate create_date, sysdate last_update_date from emp e; commit ; select * from emp_source;
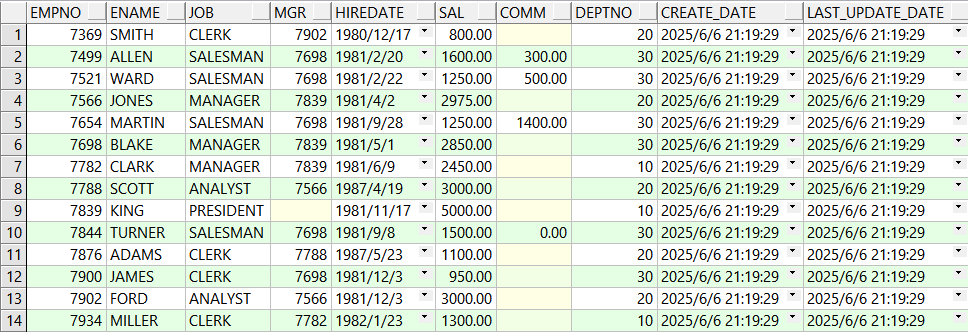
2.创建数据同步的目标表
drop table emp_tar; create table emp_tar as select e.*, sysdate etl_dt from emp e where 1 = 2; select * from emp_tar;
3.创建全量同步的存储过程并调用
create or replace procedure p_full
is
begin
----清空目标表数据
execute immediate 'truncate table emp_tar';
---插入数据到目标表
insert into emp_tar
select e.empno,
e.ename,
e.job,
e.mgr,
e.hiredate,
e.sal,
e.comm,
e.deptno,
sysdate etl_dt
from emp_source e;
commit;
----写入异常
exception
when others
then dbms_output.put_line(sqlerrm);
end;
begin
p_full;
end ;
select * from emp_tar;目标表同步成功:
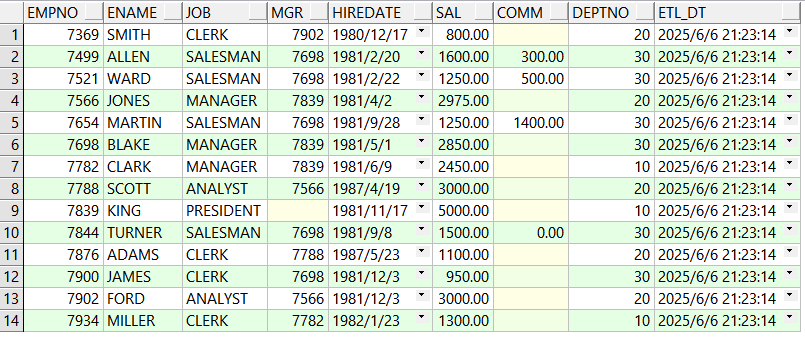
(二)全量同步练习
通过入参 p_job 工种,将非这个工种的数据,全量同步到 emp_0318 这个表(全量用truncate 实现,使用动态sql实现);
create table emp_0318 as select * from emp where 1,2;
create or replace procedure p_fullsync(p_job varchar2) is
begin
execute immediate 'truncate table emp_0318'; -- 清空目标表数据
-- 插入数据到目标表
insert into emp_0318
select * from emp where job != p_job;
commit;
-- 写入异常
exception
when others then
rollback;
end;
begin
p_fullsync(p_job => 'clerk');
end;
select * from emp_0318;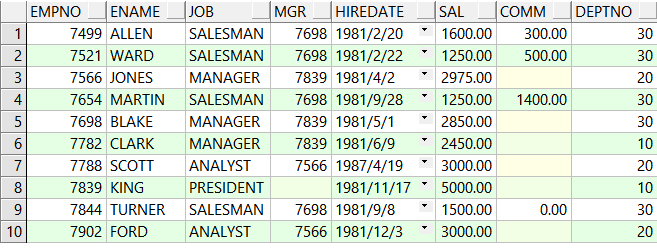
(三)存储过程 & 动态sql & 全量同步之间的区别
1.存储过程:是封装一段 数据的 同步 &转换逻辑;
2.动态sql:当sql中存在不稳定因素,比如,表名不确定,筛选条件不确定,或者是 ddl语句(truncate / drop)不能直接运行,这个时候需要 拼接一个变量的sql语句字符串,然后用 execute immediate sql语句字符串 去动态执行。如果这个sql是 select 语句 一般后面还有 into 变量赋值。
3.全量同步:在插入目标表的时候,需要先清空目标表,这样才能保证目标表的数据不会重复。(否则 我们调用一次存储过程,目标表的数据就会重复一次)。
二、增量同步——merge into
(一)相关概念介绍
1.什么是增量
增量指的是那一天新增的或者发生修改的数据。
2.什么是增量同步
逻辑:用源表的数据 更新 目标表 ,如果这条数据在目标表中存在则更新,数据不存在,则插入。
实现的逻辑:首先判断 目标表中是否有源表中的数据:如果有,则用 源表的数据 更新目标表中对应的数据;如果没有,则查询源表的记录,直接插入目标表。
通常用 merge into 的方式来做增量同步数据。
3.全量同步与增量同步的区别
全量同步是同步整张表的数据,增量同步只同步增量数据(比如今天只同步昨天新增的或者修改的数据)
全量同步之前要清空目标表的数据,增量同步不用清空表,有则更新,无则插入;
4.增量同步merge into语法结构
merge into 目标表 using (增量数据的查询结果集) --子查询 查询源表的增量结果集 on (匹配字段) --用来判断增量结果集里的数据到底是更新,目标表里的数据还是插入到目标表中 when matched then update set 目标表的字段 = 增量结果集字段 --update和set之间不需要加表名 when not matched then insert(目标表字段) values(增量结果集字段) ; --insert和values之间不需要加 into 表名
(二)增量同步练习
1.练习1
示例:假如在昨天公司里新增一个员工和 7788 这个员工的薪资发生了变化,用存储过程实现,将 emp_source 表的数据增量同步到 emp_tar
源表数据:
drop table emp_tar; drop table emp_source; create table emp_source as select e.*,sysdate create_date,sysdate last_update_date from emp e; insert into emp_source(empno,ename,hiredate,create_date,last_update_date) values(1111,'lisa',trunc(sysdate)-1,trunc(sysdate)-1,trunc(sysdate)-1); update emp_source set sal=10000,last_update_date=trunc(sysdate)-1 where empno=7788; commit; select * from emp_source;
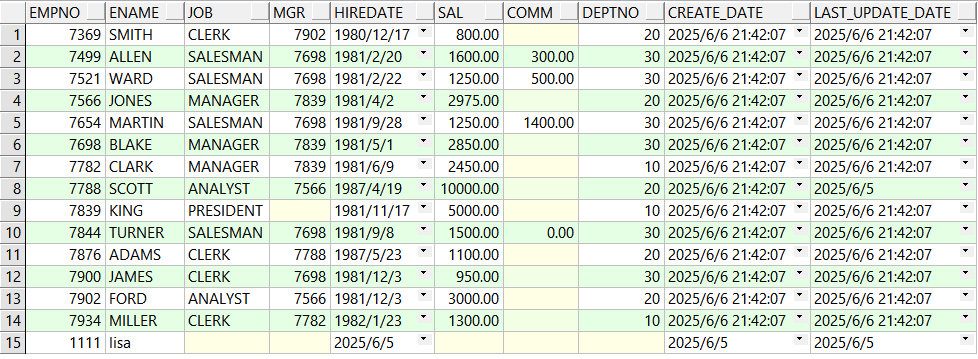
create table emp_tar as select e.*,sysdate etl_dt from emp e; select * from emp_tar;
目标表数据:
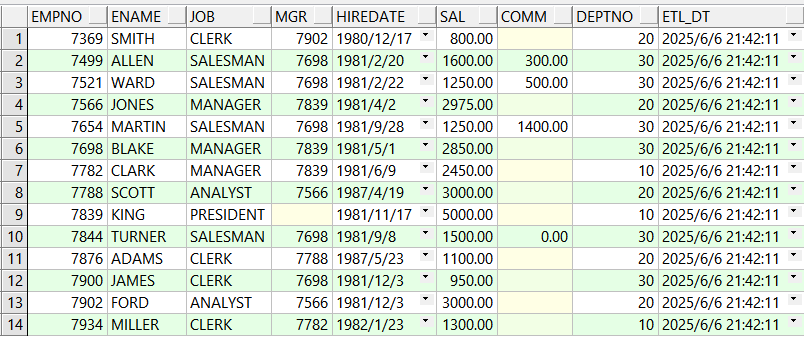
编写存储过程进行增量同步,并进行调用:
create or replace procedure p_emp_source(p_dt date) as
begin
merge into emp_tar a
using (select * from emp_source where last_update_date = p_dt) b
--子查询 查询源表的增量结果集
on (a.empno = b.empno)
--用来判断增量结果集里的数据到底是更新,目标表里的数据还是插入到目标表中
when matched then
update
set a.ename = b.ename, --主键不能update
a.job = b.job,
a.mgr = b.mgr,
a.hiredate = b.hiredate,
a.sal = b.sal,
a.comm = b.comm,
a.deptno = b.deptno,
a.etl_dt = sysdate --update和set之间不需要加表名
when not matched then
insert
(a.empno,
a.ename,
a.job,
a.mgr,
a.hiredate,
a.sal,
a.comm,
a.deptno,
a.etl_dt)
values
(b.empno,
b.ename,
b.job,
b.mgr,
b.hiredate,
b.sal,
b.comm,
b.deptno,
sysdate); --insert和values之间不需要加 into 表名
commit;
end;
begin
p_emp_source(p_dt=>trunc(sysdate)-1);
end;目标表数据:
select * from emp_tar;
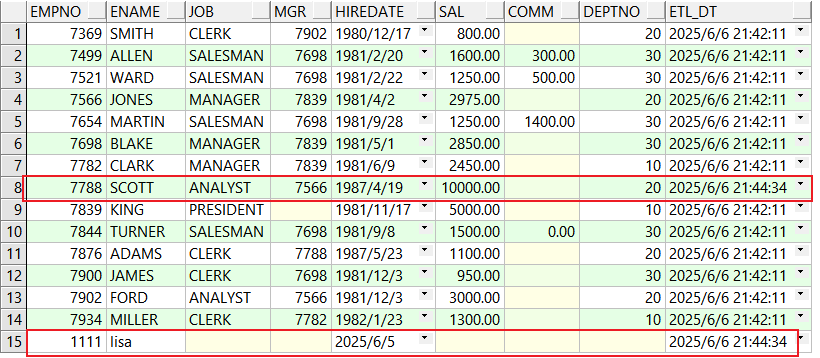
2.练习2
--书 book表
drop table book;
create table book(bno varchar2(20),--图书编号
bname varchar2(50),--图书名称
aid int,--作者
pid int,--出版社
tid varchar2(20),--种类
buy date,--进货日期
price number(7,2),--价格
buynum int); --数量
insert into book values('j0001','计算机基础',2001,1001,'j001',date '2016-1-5',12.5,5);
insert into book values('j0002','oracle从入门到精通',2002,1004,'j001',date '2016-8-8',30,10);
insert into book values('y0001','常见病例及用药',2005,1003,'y001',date '2016-2-4',20,20);
insert into book values('w0001','平凡的世界',2006,1003,'w001',date '2016-5-15',35,30);
insert into book values('w0002','悲惨世界',2007,1004,'w001',date '2016-4-9',31,22);
insert into book values('j0003','sql入门',2001,1004,'j001',date '2016-2-15',32,20);
insert into book values('j0004','sql基础课程',2002,1001,'j001',date '2016-6-6',28,10);
commit;
select * from book; --书(主表)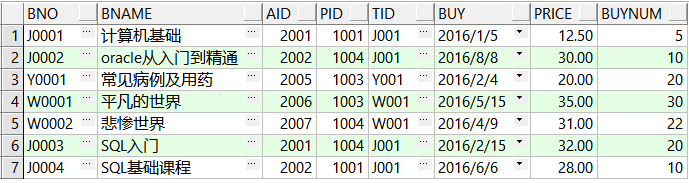
drop table book_source;
create table book_source
as
select t.*
---假如昨天写入的这些数据
,sysdate -1 as create_date
,sysdate -1 as last_update_date
from book t;
select * from book_source;
---目标表
drop table book_target;
create table book_target(bno varchar2(20) ,--图书编号
bname varchar2(50),--图书名称
aid int,--作者
pid int,--出版社
tid varchar2(20),--种类
buy date,--进货日期
price number(7,2),--价格
buynum int
,etl_date date);
select * from book_target;
-- 创建存储过程,将源表数据同步到目标表中
create or replace procedure p_book_source_target(p_dt date) is
v_rowcount number;
begin
merge into book_target a
using (select * from book_source where trunc(last_update_date) = p_dt) b
on (a.bno = b.bno)
when matched then
update
set a.bname = b.bname,
a.aid = b.aid,
a.pid = b.pid,
a.tid = b.tid,
a.buy = b.buy,
a.price = b.price,
a.buynum = b.buynum,
a.etl_date = sysdate -- 这里必须是当天的日期
when not matched then
insert
(a.bno,
a.bname,
a.aid,
a.pid,
a.tid,
a.buy,
a.price,
a.buynum,
a.etl_date)
values
(b.bno,
b.bname,
b.aid,
b.pid,
b.tid,
b.buy,
b.price,
b.buynum,
sysdate);
-- 记录merge影响的行数
v_rowcount := sql%rowcount;
dbms_output.put_line('merge影响的行数: ' || v_rowcount);
commit;
exception
when others then
rollback;
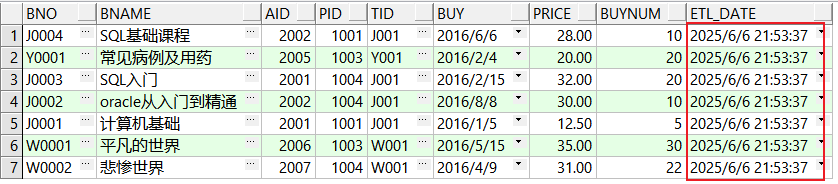
end;-- 没有匹配到数据,是新增数据 begin p_book_source_target(p_dt => trunc(sysdate) - 1); -- 传入昨天的日期 end; select * from book_target;
源表数据成功insert到目标表中:
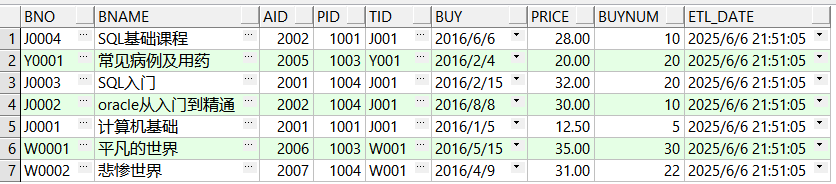
insert into book_source
select t.*
---假如昨天写入的这些数据
,sysdate as create_date
,sysdate as last_update_date
from book t;
commit;
select * from book_source;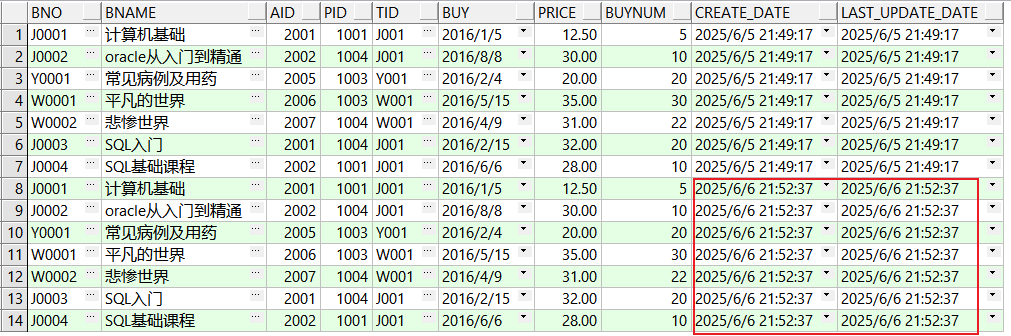
begin p_book_source_target(p_dt => trunc(sysdate)); -- 传入今天的日期 end; -- 这次匹配到了,是更新操作 select * from book_target;
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论