一、将voc格式数据集转换为yolo格式数据集
执行以下脚本将voc格式数据集转换为yolo格式数据集。
但是需要注意的是:
- 转换之后的数据集只有images和labels两个文件。还需要执行第二节中的脚本进行数据集划分,将总的数据集划分为训练、验证、测试数据集;
- 使用的话,需要修改 class_mapping 中类别名和对应标签,还有voc数据集路径、yolo数据集路径。
import os
import shutil
import xml.etree.elementtree as et
# voc格式数据集路径
voc_data_path = 'e:\\dataset\\helmet-voc'
voc_annotations_path = os.path.join(voc_data_path, 'annotations')
voc_images_path = os.path.join(voc_data_path, 'jpegimages')
# yolo格式数据集保存路径
yolo_data_path = 'e:\\dataset\\helmet-yolo'
yolo_images_path = os.path.join(yolo_data_path, 'images')
yolo_labels_path = os.path.join(yolo_data_path, 'labels')
# 创建yolo格式数据集目录
os.makedirs(yolo_images_path, exist_ok=true)
os.makedirs(yolo_labels_path, exist_ok=true)
# 类别映射 (可以根据自己的数据集进行调整)
class_mapping = {
'head': 0,
'helmet': 1,
'person': 2,
# 添加更多类别...
}
def convert_voc_to_yolo(voc_annotation_file, yolo_label_file):
tree = et.parse(voc_annotation_file)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
with open(yolo_label_file, 'w') as f:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
ymin = float(xmlbox.find('ymin').text)
xmax = float(xmlbox.find('xmax').text)
ymax = float(xmlbox.find('ymax').text)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
# 遍历voc数据集的annotations目录,进行转换
for voc_annotation in os.listdir(voc_annotations_path):
if voc_annotation.endswith('.xml'):
voc_annotation_file = os.path.join(voc_annotations_path, voc_annotation)
image_id = os.path.splitext(voc_annotation)[0]
voc_image_file = os.path.join(voc_images_path, f"{image_id}.jpg")
yolo_label_file = os.path.join(yolo_labels_path, f"{image_id}.txt")
yolo_image_file = os.path.join(yolo_images_path, f"{image_id}.jpg")
convert_voc_to_yolo(voc_annotation_file, yolo_label_file)
if os.path.exists(voc_image_file):
shutil.copy(voc_image_file, yolo_image_file)
print("转换完成!")
二、yolo格式数据集划分(训练、验证、测试)
参考:https://docs.ultralytics.com/datasets/detect/#ultralytics-yolo-format
随机将数据集按照0.7-0.2-0.1比例划分为训练、验证、测试数据集。
注意,修改代码中图片的后缀,如果是.jpg,就把.png修改为.jpg。
最终结果
2.1 版本1
用版本1划分就行,也可以用版本2,版本3就不用了。版本1和版本2是两种不同的组织方式都能训练。版本1是官方的组织方法。
import os
import shutil
import random
def make_yolo_dataset(images_folder, labels_folder, output_folder, train_ratio=0.8):
# 创建目标文件夹
images_train_folder = os.path.join(output_folder, 'images/train')
images_val_folder = os.path.join(output_folder, 'images/val')
labels_train_folder = os.path.join(output_folder, 'labels/train')
labels_val_folder = os.path.join(output_folder, 'labels/val')
os.makedirs(images_train_folder, exist_ok=true)
os.makedirs(images_val_folder, exist_ok=true)
os.makedirs(labels_train_folder, exist_ok=true)
os.makedirs(labels_val_folder, exist_ok=true)
# 获取图片和标签的文件名(不包含扩展名)
image_files = [f for f in os.listdir(images_folder) if f.endswith('.jpg')]
label_files = [f for f in os.listdir(labels_folder) if f.endswith('.txt')]
image_base_names = set(os.path.splitext(f)[0] for f in image_files)
label_base_names = set(os.path.splitext(f)[0] for f in label_files)
# 找出图片和标签都存在的文件名
matched_files = list(image_base_names & label_base_names)
# 打乱顺序并划分为训练集和验证集
random.shuffle(matched_files)
split_idx = int(len(matched_files) * train_ratio)
train_files = matched_files[:split_idx]
val_files = matched_files[split_idx:]
# 移动文件到对应文件夹
for base_name in train_files:
img_src = os.path.join(images_folder, f"{base_name}.jpg")
lbl_src = os.path.join(labels_folder, f"{base_name}.txt")
img_dst = os.path.join(images_train_folder, f"{base_name}.jpg")
lbl_dst = os.path.join(labels_train_folder, f"{base_name}.txt")
shutil.copyfile(img_src, img_dst)
shutil.copyfile(lbl_src, lbl_dst)
for base_name in val_files:
img_src = os.path.join(images_folder, f"{base_name}.jpg")
lbl_src = os.path.join(labels_folder, f"{base_name}.txt")
img_dst = os.path.join(images_val_folder, f"{base_name}.jpg")
lbl_dst = os.path.join(labels_val_folder, f"{base_name}.txt")
shutil.copyfile(img_src, img_dst)
shutil.copyfile(lbl_src, lbl_dst)
print("数据集划分完成!")
# 使用示例
images_folder = 'path/to/your/images_folder' # 原始图片文件夹路径
labels_folder = 'path/to/your/labels_folder' # 原始标签文件夹路径
output_folder = 'path/to/your/output_folder' # 存放结果数据集的文件夹路径
make_yolo_dataset(images_folder, labels_folder, output_folder)
2.2 版本2
import os
import shutil
import random
from math import floor
# 创建输出目录的函数
def create_dirs(output_dir):
images_dir = os.path.join(output_dir, 'images')
labels_dir = os.path.join(output_dir, 'labels')
for split in ['train', 'val', 'test']:
os.makedirs(os.path.join(images_dir, split), exist_ok=true)
os.makedirs(os.path.join(labels_dir, split), exist_ok=true)
return images_dir, labels_dir
# 获取图片和对应txt标签的列表
def get_files(images_path, labels_path):
image_files = [f for f in os.listdir(images_path) if f.endswith(('jpg', 'png', 'jpeg'))]
label_files = [f for f in os.listdir(labels_path) if f.endswith('.txt')]
# 检查图片和标签是否配对
paired_files = []
for image_file in image_files:
base_name = os.path.splitext(image_file)[0]
label_file = base_name + '.txt'
if label_file in label_files:
paired_files.append((image_file, label_file))
return paired_files
# 将文件按比例划分并拷贝到相应目录
def split_and_copy(paired_files, images_path, labels_path, images_dir, labels_dir, train_ratio, val_ratio):
random.shuffle(paired_files) # 随机打乱
total_files = len(paired_files)
train_count = floor(total_files * train_ratio)
val_count = floor(total_files * val_ratio)
test_count = total_files - train_count - val_count
splits = {
'train': paired_files[:train_count],
'val': paired_files[train_count:train_count + val_count],
'test': paired_files[train_count + val_count:]
}
for split, files in splits.items():
for image_file, label_file in files:
shutil.copy(os.path.join(images_path, image_file), os.path.join(images_dir, split, image_file))
shutil.copy(os.path.join(labels_path, label_file), os.path.join(labels_dir, split, label_file))
print(f'{split}: {len(files)} files')
# 主函数
def main():
# 写死的路径
images_path = "e:\\dataset\\lc\\large_coal_blocked_yolo\\totalimages" # 替换为实际图片文件夹路径
labels_path = "e:\\dataset\\lc\\large_coal_blocked_yolo\\totallabels" # 替换为实际txt文件夹路径
output_dir = "e:\\dataset\\lc\\large_coal_blocked_yolo\\output" # 替换为实际输出主目录路径
# 数据划分比例
train_ratio = 0.7
val_ratio = 0.3
test_ratio = 0
# 容差值用于浮点数比较
epsilon = 1e-6
# 确保比例之和等于1
assert abs(train_ratio + val_ratio + test_ratio - 1) < epsilon, "比例之和必须等于1"
# 创建目录
images_dir, labels_dir = create_dirs(output_dir)
# 获取文件列表
paired_files = get_files(images_path, labels_path)
# 进行划分并拷贝
split_and_copy(paired_files, images_path, labels_path, images_dir, labels_dir, train_ratio, val_ratio)
# 调用主函数
if __name__ == "__main__":
main()
2.3 版本3
import os
import shutil
import random
# yolo格式数据集保存路径
yolo_images_path1 = 'e:\\dataset\\helmet-voc'
yolo_labels_path1 = 'e:\\dataset\\helmet-yolo'
yolo_data_path = yolo_labels_path1
yolo_images_path = os.path.join(yolo_images_path1, 'jpegimages')
yolo_labels_path = os.path.join(yolo_labels_path1, 'labels')
# 创建划分后的目录结构
train_images_path = os.path.join(yolo_data_path, 'train', 'images')
train_labels_path = os.path.join(yolo_data_path, 'train', 'labels')
val_images_path = os.path.join(yolo_data_path, 'val', 'images')
val_labels_path = os.path.join(yolo_data_path, 'val', 'labels')
test_images_path = os.path.join(yolo_data_path, 'test', 'images')
test_labels_path = os.path.join(yolo_data_path, 'test', 'labels')
os.makedirs(train_images_path, exist_ok=true)
os.makedirs(train_labels_path, exist_ok=true)
os.makedirs(val_images_path, exist_ok=true)
os.makedirs(val_labels_path, exist_ok=true)
os.makedirs(test_images_path, exist_ok=true)
os.makedirs(test_labels_path, exist_ok=true)
# 获取所有图片文件名(不包含扩展名)
image_files = [f[:-4] for f in os.listdir(yolo_images_path) if f.endswith('.png')]
# 随机打乱文件顺序
random.shuffle(image_files)
# 划分数据集比例
train_ratio = 0.7
val_ratio = 0.2
test_ratio = 0.1
train_count = int(train_ratio * len(image_files))
val_count = int(val_ratio * len(image_files))
test_count = len(image_files) - train_count - val_count
train_files = image_files[:train_count]
val_files = image_files[train_count:train_count + val_count]
test_files = image_files[train_count + val_count:]
# 移动文件到相应的目录
def move_files(files, src_images_path, src_labels_path, dst_images_path, dst_labels_path):
for file in files:
src_image_file = os.path.join(src_images_path, f"{file}.png")
src_label_file = os.path.join(src_labels_path, f"{file}.txt")
dst_image_file = os.path.join(dst_images_path, f"{file}.png")
dst_label_file = os.path.join(dst_labels_path, f"{file}.txt")
if os.path.exists(src_image_file) and os.path.exists(src_label_file):
shutil.move(src_image_file, dst_image_file)
shutil.move(src_label_file, dst_label_file)
# 移动训练集文件
move_files(train_files, yolo_images_path, yolo_labels_path, train_images_path, train_labels_path)
# 移动验证集文件
move_files(val_files, yolo_images_path, yolo_labels_path, val_images_path, val_labels_path)
# 移动测试集文件
move_files(test_files, yolo_images_path, yolo_labels_path, test_images_path, test_labels_path)
print("数据集划分完成!")
三、一步到位
如果不想分两步进行格式转换,那么以下脚本结合了以上两步,直接得到最后按比例划分训练、验证、测试的数据集结果。
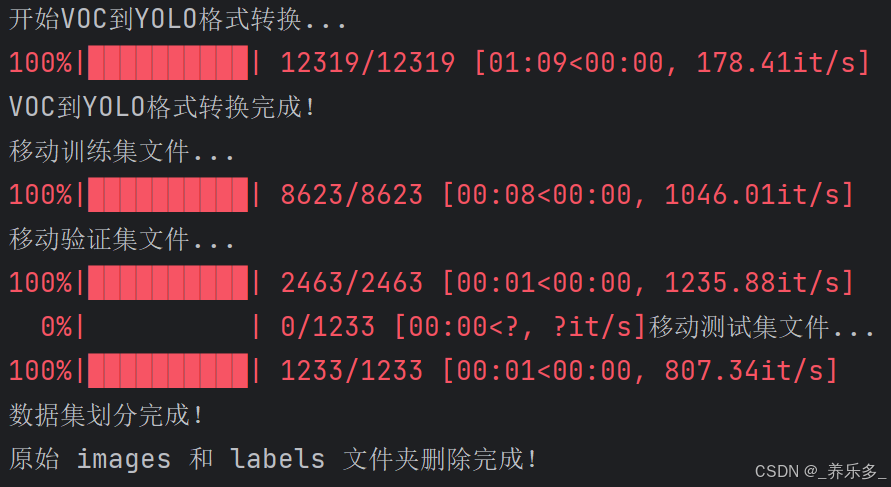
注意:需要修改 voc_data_path ,yolo_data_path ,class_mapping 以及 ‘.png’ 后缀。
import os
import shutil
import random
import xml.etree.elementtree as et
from tqdm import tqdm
# voc格式数据集路径
voc_data_path = 'e:\\dataset-voc'
voc_annotations_path = os.path.join(voc_data_path, 'annotations')
voc_images_path = os.path.join(voc_data_path, 'jpegimages')
# yolo格式数据集保存路径
yolo_data_path = 'e:\\dataset-yolo'
yolo_images_path = os.path.join(yolo_data_path, 'images')
yolo_labels_path = os.path.join(yolo_data_path, 'labels')
# 创建yolo格式数据集目录
os.makedirs(yolo_images_path, exist_ok=true)
os.makedirs(yolo_labels_path, exist_ok=true)
# 类别映射 (可以根据自己的数据集进行调整)
class_mapping = {
'head': 0,
'helmet': 1,
'person': 2,
# 添加更多类别...
}
def convert_voc_to_yolo(voc_annotation_file, yolo_label_file):
tree = et.parse(voc_annotation_file)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
with open(yolo_label_file, 'w') as f:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
ymin = float(xmlbox.find('ymin').text)
xmax = float(xmlbox.find('xmax').text)
ymax = float(xmlbox.find('ymax').text)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
# 遍历voc数据集的annotations目录,进行转换
print("开始voc到yolo格式转换...")
for voc_annotation in tqdm(os.listdir(voc_annotations_path)):
if voc_annotation.endswith('.xml'):
voc_annotation_file = os.path.join(voc_annotations_path, voc_annotation)
image_id = os.path.splitext(voc_annotation)[0]
voc_image_file = os.path.join(voc_images_path, f"{image_id}.png")
yolo_label_file = os.path.join(yolo_labels_path, f"{image_id}.txt")
yolo_image_file = os.path.join(yolo_images_path, f"{image_id}.png")
convert_voc_to_yolo(voc_annotation_file, yolo_label_file)
if os.path.exists(voc_image_file):
shutil.copy(voc_image_file, yolo_image_file)
print("voc到yolo格式转换完成!")
# 划分数据集
train_images_path = os.path.join(yolo_data_path, 'train', 'images')
train_labels_path = os.path.join(yolo_data_path, 'train', 'labels')
val_images_path = os.path.join(yolo_data_path, 'val', 'images')
val_labels_path = os.path.join(yolo_data_path, 'val', 'labels')
test_images_path = os.path.join(yolo_data_path, 'test', 'images')
test_labels_path = os.path.join(yolo_data_path, 'test', 'labels')
os.makedirs(train_images_path, exist_ok=true)
os.makedirs(train_labels_path, exist_ok=true)
os.makedirs(val_images_path, exist_ok=true)
os.makedirs(val_labels_path, exist_ok=true)
os.makedirs(test_images_path, exist_ok=true)
os.makedirs(test_labels_path, exist_ok=true)
# 获取所有图片文件名(不包含扩展名)
image_files = [f[:-4] for f in os.listdir(yolo_images_path) if f.endswith('.png')]
# 随机打乱文件顺序
random.shuffle(image_files)
# 划分数据集比例
train_ratio = 0.7
val_ratio = 0.2
test_ratio = 0.1
train_count = int(train_ratio * len(image_files))
val_count = int(val_ratio * len(image_files))
test_count = len(image_files) - train_count - val_count
train_files = image_files[:train_count]
val_files = image_files[train_count:train_count + val_count]
test_files = image_files[train_count + val_count:]
# 移动文件到相应的目录
def move_files(files, src_images_path, src_labels_path, dst_images_path, dst_labels_path):
for file in tqdm(files):
src_image_file = os.path.join(src_images_path, f"{file}.png")
src_label_file = os.path.join(src_labels_path, f"{file}.txt")
dst_image_file = os.path.join(dst_images_path, f"{file}.png")
dst_label_file = os.path.join(dst_labels_path, f"{file}.txt")
if os.path.exists(src_image_file) and os.path.exists(src_label_file):
shutil.move(src_image_file, dst_image_file)
shutil.move(src_label_file, dst_label_file)
# 移动训练集文件
print("移动训练集文件...")
move_files(train_files, yolo_images_path, yolo_labels_path, train_images_path, train_labels_path)
# 移动验证集文件
print("移动验证集文件...")
move_files(val_files, yolo_images_path, yolo_labels_path, val_images_path, val_labels_path)
# 移动测试集文件
print("移动测试集文件...")
move_files(test_files, yolo_images_path, yolo_labels_path, test_images_path, test_labels_path)
print("数据集划分完成!")
# 删除原始的 images 和 labels 文件夹
shutil.rmtree(yolo_images_path)
shutil.rmtree(yolo_labels_path)
print("原始 images 和 labels 文件夹删除完成!")
到此这篇关于python实现将voc格式数据集转换为yolo格式数据集的文章就介绍到这了,更多相关python voc格式转yolo格式内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论