一.背景概述
本周接到一个新的需求:从用户dau日志文件中读取用户uid,然后到redis中获取对应的用户数据。用户的uid存储于login_day_20220913.txt文件,共1亿2千多万条数据,数量达1.4g。
要求:尽量在2小时内获得结果,在数据处理过程中,redis服务器qps尽量低,不超过某个阈值,不然会触发监控报警。数据从redis从库读取,只提供一个端口。
二.分析与实现
由于之前做过相同数据量的统计需求,所以从一开始就确定单线程完成此次数据处理也是可以的。实际上,对多线程和并发的使用需要慎之又慎,特别是在业务繁忙的系统或环境下。
接触redis的朋友都知道,redis是支持批量读取的,其中常用的两个方法:mget()和hmget()。
本次处理的数据不是哈希结构,所以确定使用mget()。
此时,我自然而然地问了同事一个问题,那就是mget批量处理数据的最佳参数范围是多少?因为mget()接受一个字符串数组参数,也就是说字符串数组的长度最佳为多少?
同事并没有给我明确的答案,只是说他们日常每批次处理10000条,建议我自己可以尝试一下,于是我打算试试50000条数据。
主要代码如下:
package com.sina.weibo;
import com.sina.weibo.util.fileutils;
import com.sina.weibo.util.listutil;
import org.apache.commons.lang3.time.stopwatch;
import redis.clients.jedis.jedis;
import java.util.arraylist;
import java.util.linkedhashset;
import java.util.list;
import java.util.concurrent.timeunit;
public class application {
/** dau数据读取路径 */
private static string daudatapath = "/data1/sinawap/var/logs/wapcommon/place/user_position/dau/login_day_20220913.txt";
/** 结果输出路径 */
private static string outputpath = "/data1/bingqing5/importcampusdata/output/campus_data.txt";
/** 已处理过的uid数据存储路径 */
private static string processeduiddatapath = "/data1/bingqing5/importcampusdata/process/processed_uid.txt";
public static void main(string[] args) {
stopwatch stopwatch = new stopwatch();
// 开始时间
stopwatch.start();
system.out.println("================程序开始===============");
transfer(daudatapath, processeduiddatapath, outputpath);
system.out.println("================程序结束===============");
// 结束时间
stopwatch.stop();
// 统计执行时间(秒)
system.out.println("执行时长:" + stopwatch.gettime(timeunit.seconds) + " 秒.");
}
private static void transfer(string daudatapath, string processeduiddatapath, string outputpath) {
list<string> daudatalist = fileutils.readinfofromfile(daudatapath);
list<list<string>> bucket = listutil.splitlist(daudatalist, 50000);
jedis jedis = new jedis("rdsxxxxx.xxxx.xxxx.xxxx.com.cn",50000);
list<string> processeduiddatalist = fileutils.readinfofromfile(processeduiddatapath);
linkedhashset<string> linkedhashset = listutil.getlinkedhashset(processeduiddatalist);
for (list<string> list : bucket) {
list<string> jsonstrlist = jedis.mget(list.toarray(new string[list.size()]));
for (int i = 0; i < list.size(); i++) {
if (!linkedhashset.contains(list.get(i))) {
string uid = list.get(i);
fileutils.appendinfotofile(processeduiddatapath, uid);
string jsonstr = jsonstrlist.get(i);
if (jsonstr == null || jsonstr == "") continue;
string content = uid + "\t" + jsonstr;
fileutils.appendinfotofile(outputpath, content);
}
}
system.out.println(list.size());
}
}
}三.发现问题与屡次改进
3.1.qps过高而且波动很大
上述代码上线后没多久,就被同事找来,说qps过高,开始的时候瞬间达到近100k,之后稳定在70k~100k之间。因为担心影响其他业务,于是把jar包暂停,着手优化。
于是,我多次修改如下代码:
list<list<string>> bucket = listutil.splitlist(daudatalist, 50000);
将50000,调整为10000,5000,1000,500,100等值逐一尝试。
qps确实逐步降下来了,但是即便是每次处理1000条,qps也有40k左右。
3.2.程序中断,抛异常
最终以每批次读取500条数据,将代码上线。但是程序总是中断报错,抛出异常:
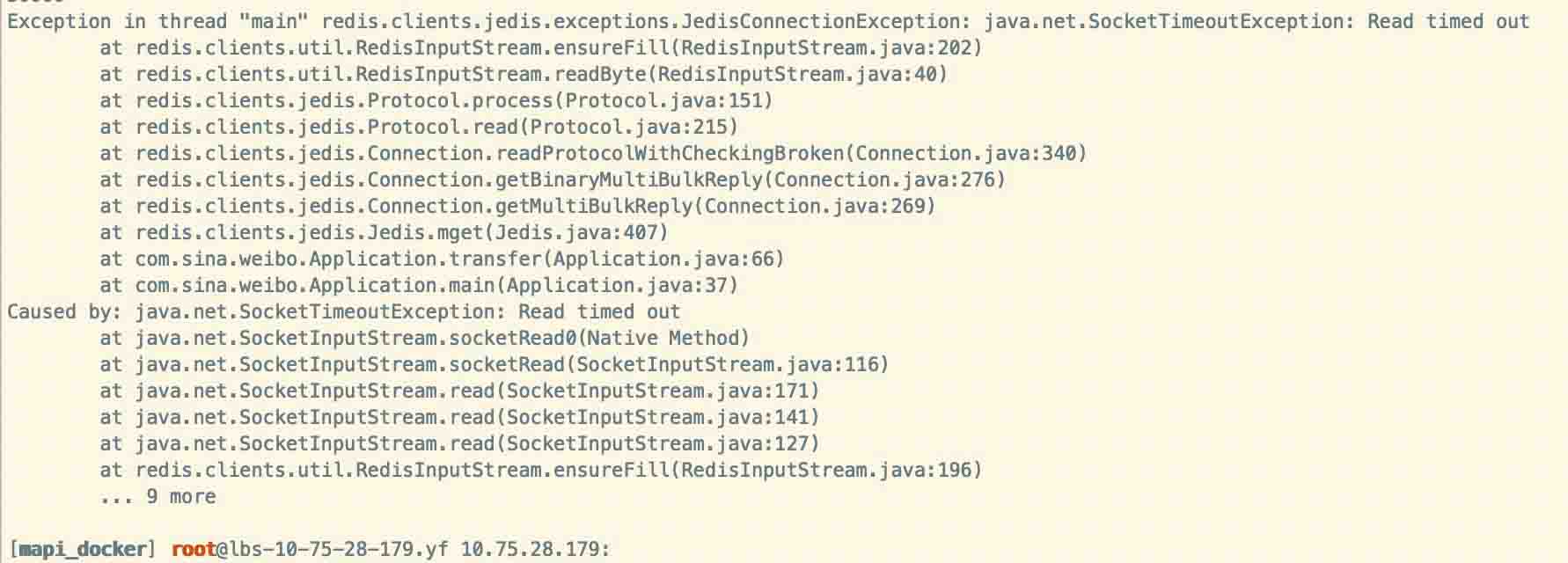
而这时候已处理的数据量达到几千万条。
最初怀疑是因为jedis对象没有调用close方法,于是修改代码如下:
package com.sina.weibo;
import com.sina.weibo.util.fileutils;
import com.sina.weibo.util.listutil;
import org.apache.commons.lang3.time.stopwatch;
import redis.clients.jedis.jedis;
import java.util.arraylist;
import java.util.linkedhashset;
import java.util.list;
import java.util.concurrent.timeunit;
public class application {
/** dau数据读取路径 */
private static string daudatapath = "/data1/sinawap/var/logs/wapcommon/place/user_position/dau/login_day_20220913.txt";
/** 结果输出路径 */
private static string outputpath = "/data1/bingqing5/importcampusdata/output/campus_data.txt";
/** 已处理过的uid数据存储路径 */
private static string processeduiddatapath = "/data1/bingqing5/importcampusdata/process/processed_uid.txt";
public static void main(string[] args) {
stopwatch stopwatch = new stopwatch();
// 开始时间
stopwatch.start();
system.out.println("================程序开始===============");
transfer(daudatapath, processeduiddatapath, outputpath);
system.out.println("================程序结束===============");
// 结束时间
stopwatch.stop();
// 统计执行时间(秒)
system.out.println("执行时长:" + stopwatch.gettime(timeunit.seconds) + " 秒.");
}
private static void transfer(string daudatapath, string processeduiddatapath, string outputpath) {
list<string> daudatalist = fileutils.readinfofromfile(daudatapath);
list<list<string>> bucket = listutil.splitlist(daudatalist, 50000);
list<string> processeduiddatalist = fileutils.readinfofromfile(processeduiddatapath);
linkedhashset<string> linkedhashset = listutil.getlinkedhashset(processeduiddatalist);
for (list<string> list : bucket) {
jedis jedis = new jedis(rdsxxxxx.xxxx.xxxx.xxxx.com.cn", 50000);
list<string> jsonstrlist = jedis.mget(list.toarray(new string[list.size()]));
for (int i = 0; i < list.size(); i++) {
if (!linkedhashset.contains(list.get(i))) {
string uid = list.get(i);
fileutils.appendinfotofile(processeduiddatapath, uid);
string jsonstr = jsonstrlist.get(i);
if (jsonstr == null || jsonstr == "") continue;
string content = uid + "\t" + jsonstr;
fileutils.appendinfotofile(outputpath, content);
}
}
jedis.close();
system.out.println(list.size());
}
}
}修改后跑程序依旧没有任何改善,继续修改,代码如下:
package com.sina.weibo;
import com.sina.weibo.util.fileutils;
import com.sina.weibo.util.listutil;
import org.apache.commons.lang3.time.stopwatch;
import redis.clients.jedis.jedis;
import java.util.arraylist;
import java.util.linkedhashset;
import java.util.list;
import java.util.concurrent.timeunit;
public class a {
/** dau数据读取路径 */
private static string daudatapath = "/data1/sinawap/var/logs/wapcommon/place/user_position/dau/login_day_20220913.txt";
/** 结果输出路径 */
private static string outputpath = "/data1/bingqing5/importcampusdata/output/campus_data.txt";
/** 已处理过的uid数据存储路径 */
private static string processeduiddatapath = "/data1/bingqing5/importcampusdata/process/processed_uid.txt";
public static void main(string[] args) {
stopwatch stopwatch = new stopwatch();
// 开始时间
stopwatch.start();
system.out.println("================程序开始===============");
transfer(daudatapath, processeduiddatapath, outputpath);
system.out.println("================程序结束===============");
// 结束时间
stopwatch.stop();
// 统计执行时间(秒)
system.out.println("执行时长:" + stopwatch.gettime(timeunit.seconds) + " 秒.");
}
private static void transfer(string daudatapath, string processeduiddatapath, string outputpath) {
list<string> daudatalist = fileutils.readinfofromfile(daudatapath);
list<list<string>> bucket = listutil.splitlist(daudatalist, 50000);
list<string> processeduiddatalist = fileutils.readinfofromfile(processeduiddatapath);
linkedhashset<string> linkedhashset = listutil.getlinkedhashset(processeduiddatalist);
for (list<string> list : bucket) {
jedis jedis = new jedis("rdsxxxxx.xxxx.xxxx.xxxx.com.cn", 50000);
list<string> jsonstrlist = jedis.mget(list.toarray(new string[list.size()]));
for (int i = 0; i < list.size(); i++) {
if (!linkedhashset.contains(list.get(i))) {
string uid = list.get(i);
fileutils.appendinfotofile(processeduiddatapath, uid);
string jsonstr = jsonstrlist.get(i);
if (jsonstr == null || jsonstr == "") continue;
string content = uid + "\t" + jsonstr;
fileutils.appendinfotofile(outputpath, content);
}
}
try {
thread.sleep(100);
} catch (interruptedexception e) {
e.printstacktrace();
} finally {
jedis.close();
}
system.out.println(list.size());
}
}
}上线以后,观测发现qps区域稳定,但是程序会空跑,也就是从头开始将已处理的数据也要逐一读取一次,很多时候都没有跑到上次程序处理的地方就已经被迫退出。
linkedhashset本来是用来标记上次程序运行停止的地方,但是似乎并没有完全发挥作用。
于是修改代码,加入一个新的list集合,用于存放还没有处理过的数据,代码如下:
package com.sina.weibo;
import com.sina.weibo.util.fileutils;
import com.sina.weibo.util.listutil;
import org.apache.commons.lang3.time.stopwatch;
import redis.clients.jedis.jedis;
import java.util.arraylist;
import java.util.linkedhashset;
import java.util.list;
import java.util.concurrent.timeunit;
/**
* @author bingqing5
* @date 2022/09/14 15:00
* @version 1.0
*/
public class application {
/** dau数据读取路径 */
private static string daudatapath = "/data1/sinawap/var/logs/wapcommon/place/user_position/dau/login_day_20220913.txt";
/** 结果输出路径 */
private static string outputpath = "/data1/bingqing5/importcampusdata/output/campus_data.txt";
/** 已处理过的uid数据存储路径 */
private static string processeduiddatapath = "/data1/bingqing5/importcampusdata/process/processed_uid.txt";
public static void main(string[] args) {
stopwatch stopwatch = new stopwatch();
// 开始时间
stopwatch.start();
system.out.println("================程序开始===============");
// transfer(daudatapath, processeduiddatapath, outputpath);
list<string> daudatalist = fileutils.readinfofromfile(daudatapath);
// list<list<string>> bucket = listutil.splitlist(daudatalist, 50000);
// jedis jedis = new jedis("rdsxxxxx.xxxx.xxxx.xxxx.com.cn", 50000);
list<string> processeduiddatalist = fileutils.readinfofromfile(processeduiddatapath);
linkedhashset<string> linkedhashset = listutil.getlinkedhashset(processeduiddatalist);
list<string> uidlist = new arraylist<>();
for (string uid : daudatalist) {
if (linkedhashset.contains(uid)) {
continue;
} else {
uidlist.add(uid);
}
}
list<list<string>> bucket;
if (uidlist.size() != 0) {
bucket = listutil.splitlist(uidlist, 10000);
} else {
bucket = new arraylist<>();
}
for (list<string> list : bucket) {
jedis jedis = new jedis("rdsxxxxx.xxxx.xxxx.xxxx.com.cn", 50000);
list<string> jsonstrlist = jedis.mget(list.toarray(new string[list.size()]));
for (int i = 0; i < list.size(); i++) {
if (!linkedhashset.contains(list.get(i))) {
string uid = list.get(i);
fileutils.appendinfotofile(processeduiddatapath, uid);
string jsonstr = jsonstrlist.get(i);
if (jsonstr == null || jsonstr == "") continue;
string content = uid + "\t" + jsonstr;
fileutils.appendinfotofile(outputpath, content);
}
}
try {
thread.sleep(100);
} catch (interruptedexception e) {
e.printstacktrace();
} finally {
jedis.close();
}
system.out.println(list.size());
}
system.out.println("================程序结束===============");
// 结束时间
stopwatch.stop();
// 统计执行时间(秒)
system.out.println("执行时长:" + stopwatch.gettime(timeunit.seconds) + " 秒.");
}
}终于这次修改后,上线代码,代码平稳运行。
此时查看qps,发现10000的批读取量,qps文档在25k以下,此前同样的数据量,qps能达到40k。
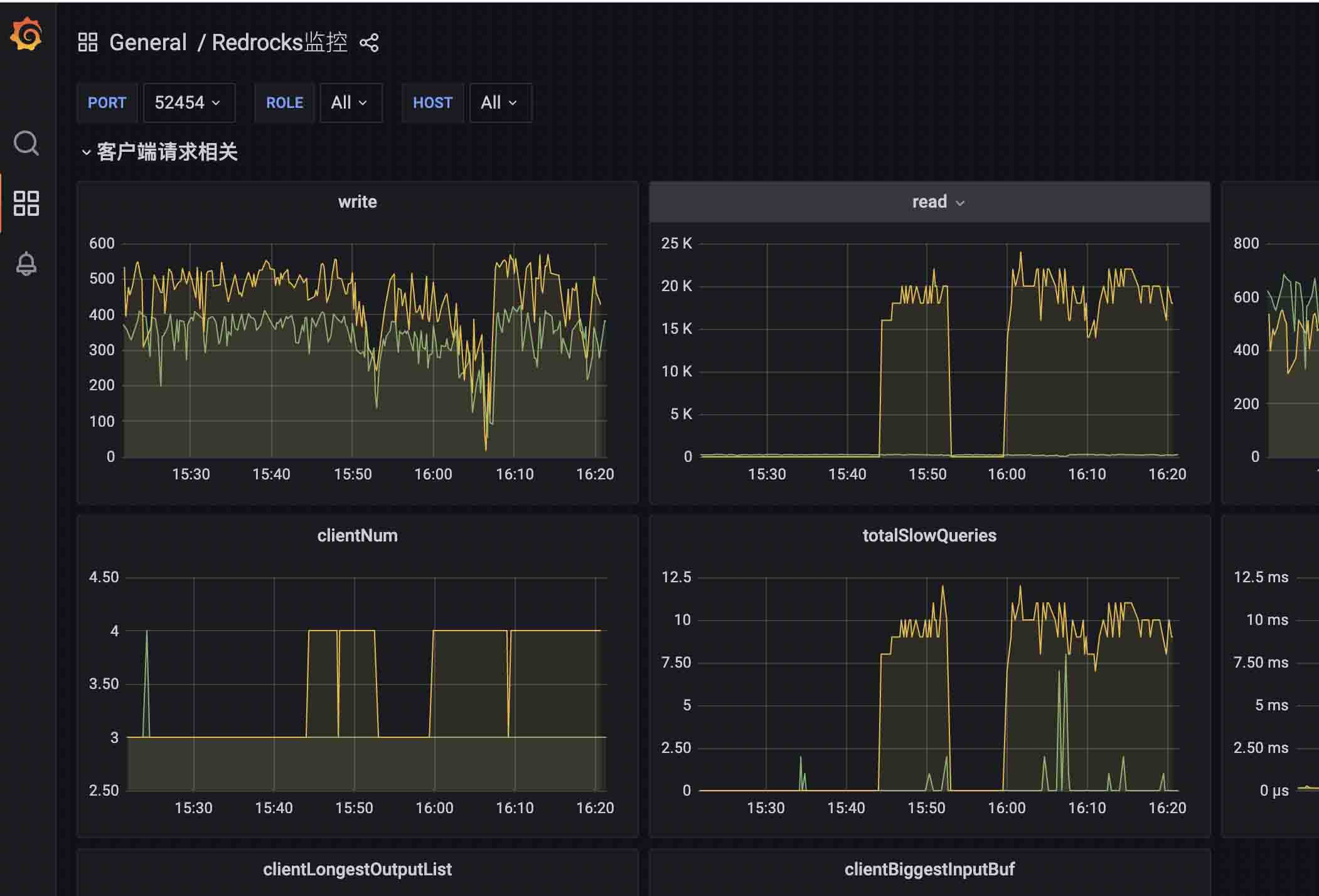
3.3.内存消耗过大
在上次修改后,程序平稳运行,期间我查看了机器状态,发现我跑的jar包竟然消耗了32%左右的内存,那台机器也不过62g的总内存。虽然不缺内存资源,但是还是决定趁着程序在跑的期间,回顾一下代码。
list<list<string>> bucket = listutil.splitlist(daudatalist, 10000);
上面这行代码是将所有的用户uid数据按照10000的大小均等分割,每次遍历,要重复创建同一类jedis对象,也会消耗大量内存。
另外,下面这段程序:
list<string> uidlist = new arraylist<>();
for (string uid : daudatalist) {
if (linkedhashset.contains(uid)) {
continue;
} else {
uidlist.add(uid);
}
}已经对处理过的数据做过筛选,在循环中再次做如下判断:
if (!linkedhashset.contains(list.get(i))) {
}也是多次一举,会增加耗时。
综合以上考虑,我做了修改,代码如下:
package com.sina.weibo;
import com.sina.weibo.util.fileutils;
import com.sina.weibo.util.listutil;
import org.apache.commons.lang3.time.stopwatch;
import redis.clients.jedis.jedis;
import java.util.arraylist;
import java.util.linkedhashset;
import java.util.list;
import java.util.concurrent.timeunit;
/**
* @author bingqing5
* @date 2022/09/14 15:00
* @version 1.0
*/
public class application {
/** dau数据读取路径 */
private static string daudatapath = "/data1/sinawap/var/logs/wapcommon/place/user_position/dau/login_day_20220913.txt";
/** 结果输出路径 */
// private static string outputpath = "/data1/bingqing5/redis_test/output/campus_data.txt";
private static string outputpath = "/data1/bingqing/redis_test/output/campus_data.txt";
/** 已处理过的uid数据存储路径 */
// private static string processeduiddatapath = "/data1/bingqing5/redis_test/process/processed_uid.txt";
private static string processeduiddatapath = "/data1/bingqing/redis_test/process/processed_uid.txt";
public static void main(string[] args) {
stopwatch stopwatch = new stopwatch();
// 开始时间
stopwatch.start();
system.out.println("================程序开始===============");
transfer(daudatapath, processeduiddatapath, outputpath);
system.out.println("================程序结束===============");
// 结束时间
stopwatch.stop();
// 统计执行时间(秒)
system.out.println("执行时长:" + stopwatch.gettime(timeunit.seconds) + " 秒.");
}
private static void transfer(string daudatapath, string processeduiddatapath, string outputpath) {
list<string> daudatalist = fileutils.readinfofromfile(daudatapath);
jedis jedis = new jedis("rdsxxxxx.xxxx.xxxx.xxxx.com.cn", 50000);
list<string> processeduiddatalist = fileutils.readinfofromfile(processeduiddatapath);
linkedhashset<string> linkedhashset = listutil.getlinkedhashset(processeduiddatalist);
list<string> uidlist = new arraylist<>();
for (string uid : daudatalist) {
if (linkedhashset.contains(uid)) {
continue;
} else {
uidlist.add(uid);
}
}
list<list<string>> bucket;
if (uidlist.size() != 0) {
bucket = listutil.splitlist(uidlist, 50000);
} else {
bucket = new arraylist<>();
}
for (list<string> list : bucket) {
list<string> jsonstrlist = jedis.mget(list.toarray(new string[list.size()]));
for (int i = 0; i < list.size(); i++) {
string uid = list.get(i);
fileutils.appendinfotofile(processeduiddatapath, uid);
string jsonstr = jsonstrlist.get(i);
if (jsonstr == null || jsonstr == "") continue;
string content = uid + "\t" + jsonstr;
fileutils.appendinfotofile(outputpath, content);
}
try {
thread.sleep(100);
} catch (interruptedexception e) {
e.printstacktrace();
} finally {
jedis.close();
}
system.out.println(list.size());
}
}
}修改代码以后,替换掉原先运行的jar包,接着运行。发现内存消耗明显降低,稳定占总内存的20%。
然后尝试修改了mget参数量,修改为50000条,再次运行程序发现qps稳定在40k左右。
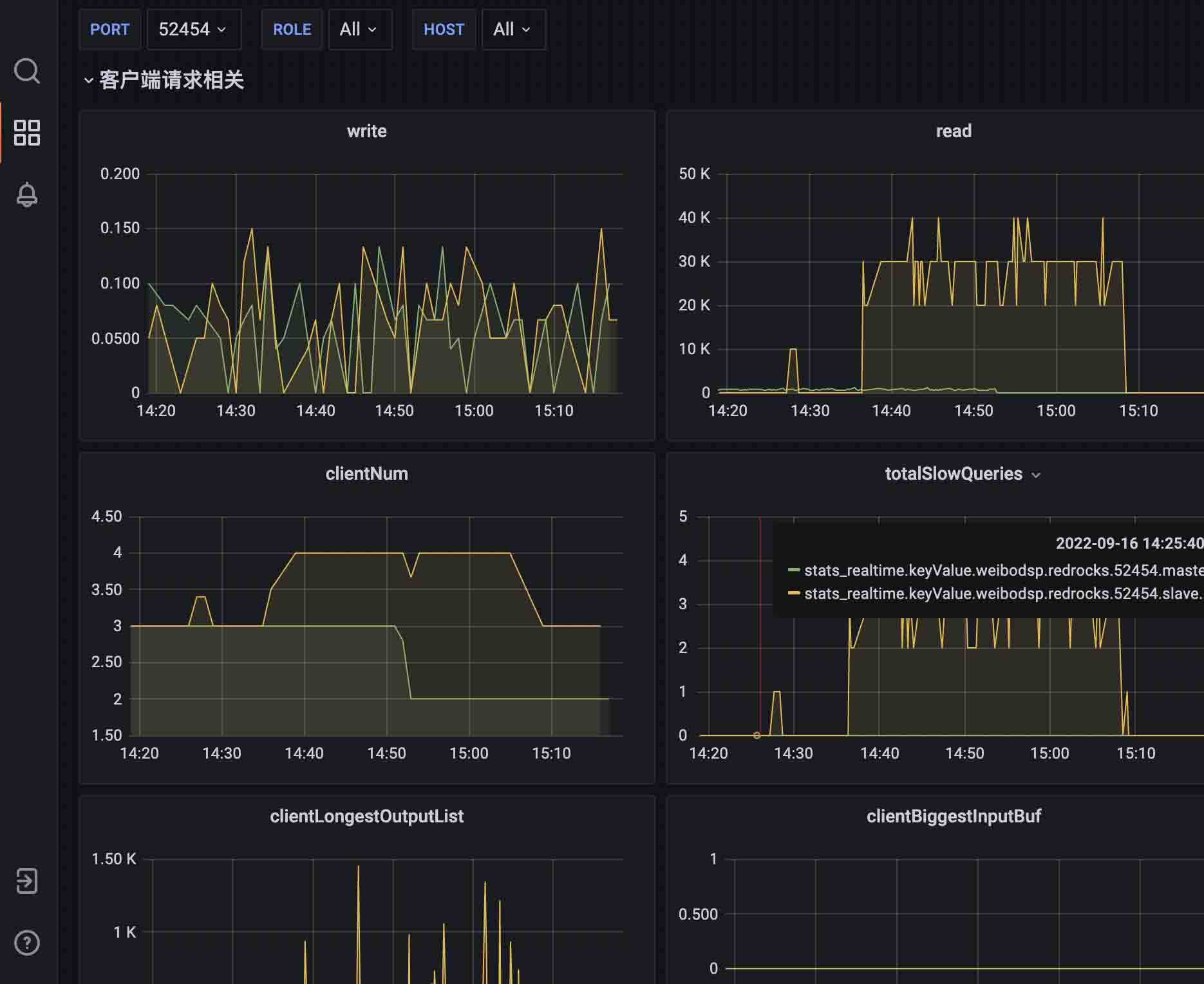
总结
本篇算是笔者刚接触redis不久的一篇随手记。通过本次需求的开发经历,让我对redis有了直观的了解,同时也理解了代码优化在实际生产工作和开发中的潜在价值。
关于redis,在快速直接从redis读取数据的场景中,尤其是数据量大的时候,为了防止qps过高,最好在处理一批次数据后空出一定的时间间隔,比如可以让线程暂时休眠一定时间间隔,再进行下批次读取和处理。
关于代码优化,尽量创建可重复使用的对象,非必要不添加同类对象,避免大量创建对象带来的资源消耗,本次经历也算是很鲜明的体会到这点。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论