引言:为什么需要pdf转word
痛点分析:pdf不可编辑的局限性
传统方法的不足(手动复制、付费工具)
python自动化转换的优势:免费、高效、可批量处理
好的!以下是对 pdf2docx 库的详细介绍,包括其功能、原理、优缺点及适用场景,帮助开发者快速掌握这一工具。
一、pdf2docx介绍
1. pdf2docx 是什么
pdf2docx 是一个基于 python 的第三方库,专门用于将 pdf 文件转换为可编辑的 word 文档(.docx 格式)。
核心功能:
- 保留 pdf 的文本、段落、表格、图片等基本布局。
- 支持自定义转换页码范围(如仅转换前 5 页)。
- 提供简单的 api,适合集成到自动化流程中。
底层依赖:
基于 pymupdf(解析 pdf 内容)和 python-docx(生成 word 文档)实现。
2. 核心特性
(1) 基本转换
from pdf2docx import converter pdf_path = "input.pdf" docx_path = "output.docx" cv = converter(pdf_path) cv.convert(docx_path, start=0, end=5) # 转换前5页 cv.close()
(2) 保留布局与元素
- 文本:提取字体、字号、颜色信息。
- 表格:自动识别并转换为 word 表格(支持合并单元格)。
- 图片:嵌入到 word 中,保留原始分辨率。
- 超链接:部分版本支持链接保留。
(3) 自定义参数
cv.convert(docx_path,
layout=true, # 保留页面布局
tables=true, # 解析表格
images=true, # 提取图片
rotate=true) # 自动旋转页面
3. 优点与局限性
优点
| 优点 | 说明 |
|---|---|
| 免费开源 | 无需付费,无文件大小限制 |
| 简单易用 | 仅需 10 行代码即可完成转换 |
| 可编程性 | 支持批量处理、集成到脚本 |
| 轻量级 | 依赖库体积小,适合快速部署 |
局限性
| 局限性 | 说明 |
|---|---|
| 复杂布局支持弱 | 多栏排版、数学公式可能错位 |
| 表格精度有限 | 嵌套表格或复杂边框可能丢失 |
| 加密 pdf 不支持 | 无法处理受密码保护的 pdf |
| 依赖字体库 | 若 pdf 使用特殊字体,word 中可能显示异常 |
4. 适用场景
| 场景 | 说明 |
|---|---|
| 简单文档转换 | 报告、合同等以文字为主的 pdf |
| 批量处理 | 自动化转换多个文件(如周报归档) |
| 快速原型开发 | 需要临时提取 pdf 内容到 word |
| 教育与科研 | 转换论文、教材等(需手动调整格式) |
5. 常见问题
(1) 转换后格式错乱?
原因:pdf 使用了复杂布局或非标准字体。
解决:
调整 word 中的样式(如手动合并单元格)。
使用 layout=false 仅提取文本。
(2) 转换速度慢?
原因:pdf 页数多或包含大量图片。
优化:
- 限制转换范围(如 end=10)。
- 关闭图片提取(images=false)。
(3) 不支持的 pdf 类型
- 扫描版 pdf(需先用 ocr 工具处理)。
- 加密或数字签名的 pdf。
6. 替代工具对比
| 工具 | 优点 | 缺点 |
|---|---|---|
| adobe acrobat | 高精度转换 | 付费、体积大 |
| 在线转换工具 | 无需安装 | 隐私风险、文件大小限制 |
| pdf2docx | 免费、可编程 | 复杂布局支持弱 |
二、环境准备:安装pdf2docx库
安装命令
pip install pdf2docx
验证安装
import pdf2docx print(pdf2docx.__version__)
常见安装问题
网络超时:切换国内镜像源(清华、阿里云)
权限不足:windows用户使用管理员模式运行cmd
三、代码实现:10行核心代码详解
from pdf2docx import converter
# 输入你的pdf路径(注意斜杠方向!)
pdf_path = "c:/users/l/desktop/input.pdf"
# 输出word路径(自动创建文件)
docx_path = "c:/users/l/desktop/output.docx"
# 初始化转换器对象
cv = converter(pdf_path)
# 执行转换(start=起始页,end=结束页)
cv.convert(docx_path, start=0, end=none)
# 释放资源
cv.close()
print("转换成功!文件已保存至:", docx_path)
代码注释:
start 和 end 参数支持指定页码范围(例如转换第2-5页)
路径需使用正斜杠/或双反斜杠\\(避免windows路径错误)
四、分步操作指南
步骤1:获取pdf文件路径
右键文件 > 属性 > 复制路径
示例:c:/users/你的用户名/desktop/财务报告.pdf
步骤2:修改代码并运行
打开 idle,在菜单栏中,点击 file > new file,这会打开一个新的编辑窗口,将代码粘贴到编辑窗口中。
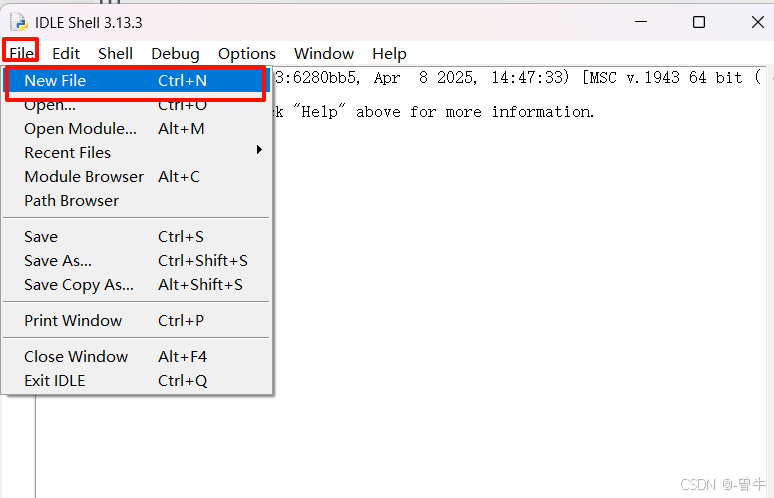
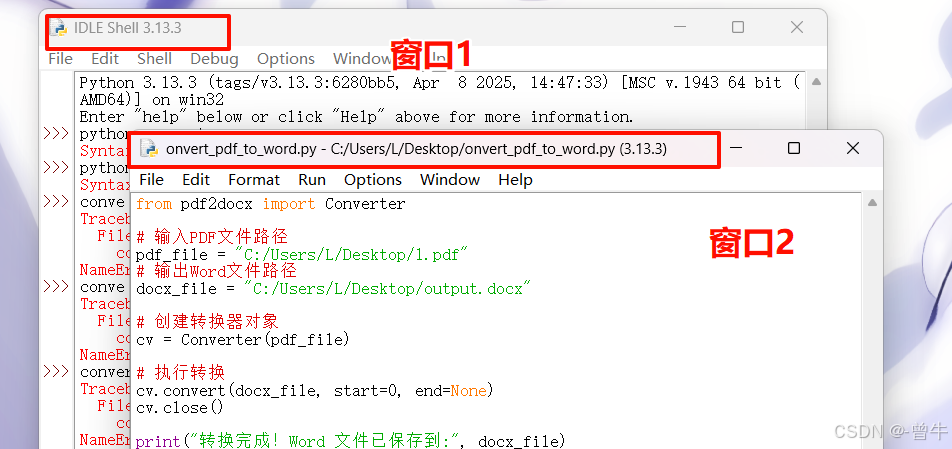
替换代码中的 pdf_path 和 docx_path ,点击 file > save as,将文件保存为 .py 格式,例如 convert_pdf_to_word.py。
在idle中按 f5 运行
注意:运行脚本时两个窗口要同时打开,不能关闭其中任何一个窗口,否则可能会报错。
步骤3:检查输出文件
- 转换时间:1页约1秒(性能实测)
- 复杂表格/图片可能需手动调整
五、进阶技巧:批量转换与自定义设置
批量处理多个pdf
import os
pdf_folder = "c:/pdfs/"
for file in os.listdir(pdf_folder):
if file.endswith(".pdf"):
pdf_path = os.path.join(pdf_folder, file)
docx_path = pdf_path.replace(".pdf", ".docx")
cv = converter(pdf_path)
cv.convert(docx_path)
cv.close()
自定义样式参数
cv.convert(docx_path,
layout=true, # 保留布局
tables=true, # 解析表格
images=true) # 提取图片
六、常见问题与解决方案
| 问题现象 | 原因 | 解决方法 |
|---|---|---|
| filenotfounderror | 路径错误或文件名含空格 | 用引号包裹路径:"c:/my docs/文件.pdf" |
| 转换后乱码 | pdf内嵌字体缺失 | 安装缺失字体或使用ocr版pdf |
| 表格错位 | 复杂多列布局 | 调整word表格或使用专业工具辅助 |
七、替代方案与工具对比
1.在线工具(smallpdf、ilovepdf)
- 优点:无需安装
- 缺点:文件大小限制、隐私风险
2.adobe acrobat pro
- 优点:高精度转换
- 缺点:付费、体积庞大
3.python方案适用场景
适合开发者、需批量处理、集成到自动化流程
结语:效率革命的开始
通过本文,你已掌握用python实现pdf转word的核心技能。
下一步建议:
- 尝试将脚本打包为exe工具(使用pyinstaller)
- 集成到钉钉/企业微信机器人(定时处理周报)
到此这篇关于python实现一键pdf转word(附完整代码及详细步骤)的文章就介绍到这了,更多相关python pdf转word内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论