shardingsphere-读写分离
读写分离
- 依赖于 mysql的主从集群 搭建手册
- 查询 走的是从库(slave)
- 新增、更新、删除走的是主库(master)
mysql主从集群
| 节点角色 | 主机地址 | 端口 | 用户名 | 密码 | 库名 |
|---|---|---|---|---|---|
| master | 192.168.40.128 | 3306 | root | root@123456 | db_demo |
| slave | 192.168.40.129 | 3306 | root | root@123456 | db_demo |
创建 user 表
主节点执行见表语句
create table `user` ( `id` bigint not null, `client_id` bigint not null, `name` varchar(255) character set utf8mb4 collate utf8mb4_general_ci null default null, `age` int null default null, primary key (`id`) using btree ) engine = innodb character set = utf8mb4 collate = utf8mb4_general_ci row_format = dynamic;
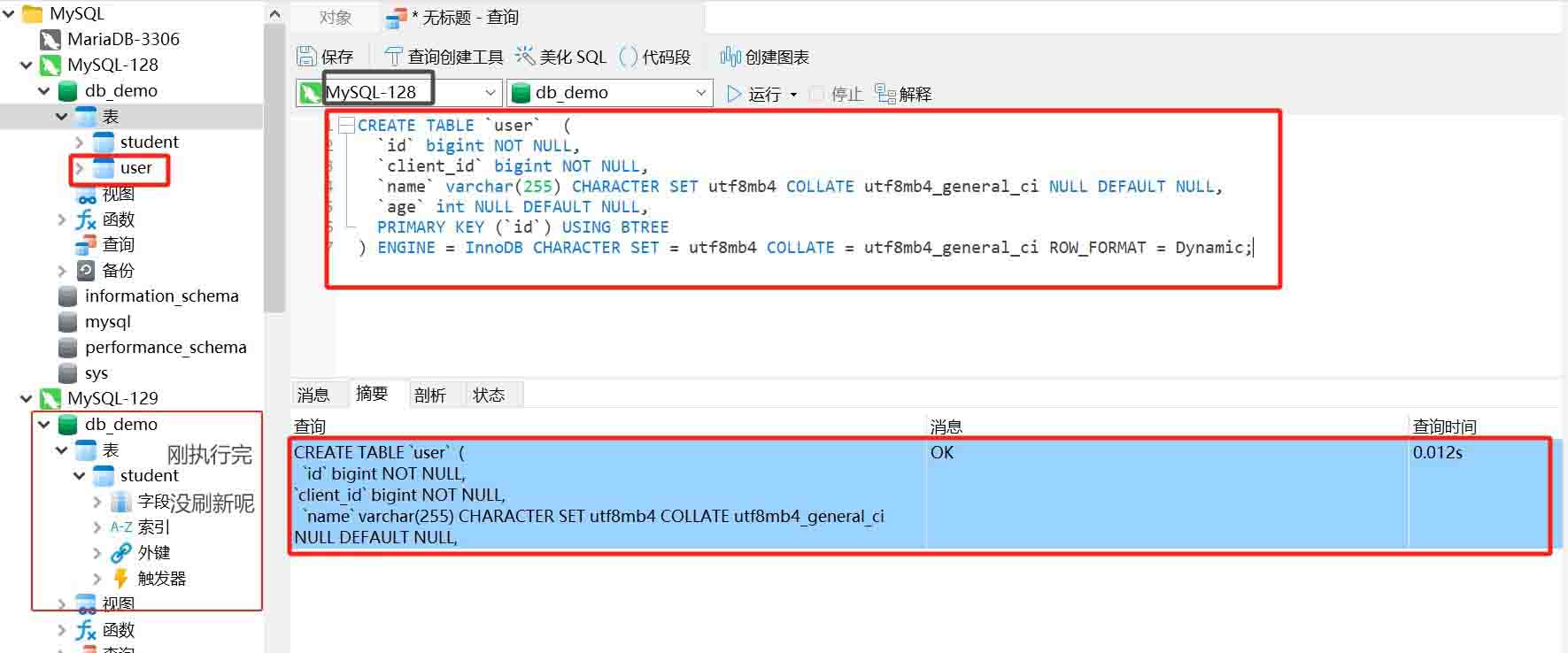
从节点刷新查看
项目代码
复用之前的 user 表操作代码即可
读写分离配置
application.yml
# 主从配置 读写分离
server:
port: 8081
spring:
main:
# 一个实体类对应两张表,覆盖
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,s1 # 主库 从库
m1:
type: com.alibaba.druid.pool.druiddatasource
driver-class-name: com.mysql.cj.jdbc.driver
url: jdbc:mysql://192.168.40.128:3306/db_demo?useunicode=true&characterencoding=utf-8&usessl=false&servertimezone=utc
username: root
password: root@123456
s1:
type: com.alibaba.druid.pool.druiddatasource
driver-class-name: com.mysql.cj.jdbc.driver
url: jdbc:mysql://192.168.40.129:3306/db_demo?useunicode=true&characterencoding=utf-8&usessl=false&servertimezone=utc
username: root
password: root@123456
sharding:
tables:
user:
# 分表策略 固定分配到主库的user表 即 m1.user
actual-data-nodes: m1.user
# 主库从库规则定义
master-slave-rules:
m1:
# 主库
master-data-source-name: m1
# 从库
slave-data-source-names: s1
props:
# 打印sql日志
sql:
show: true
测试结果
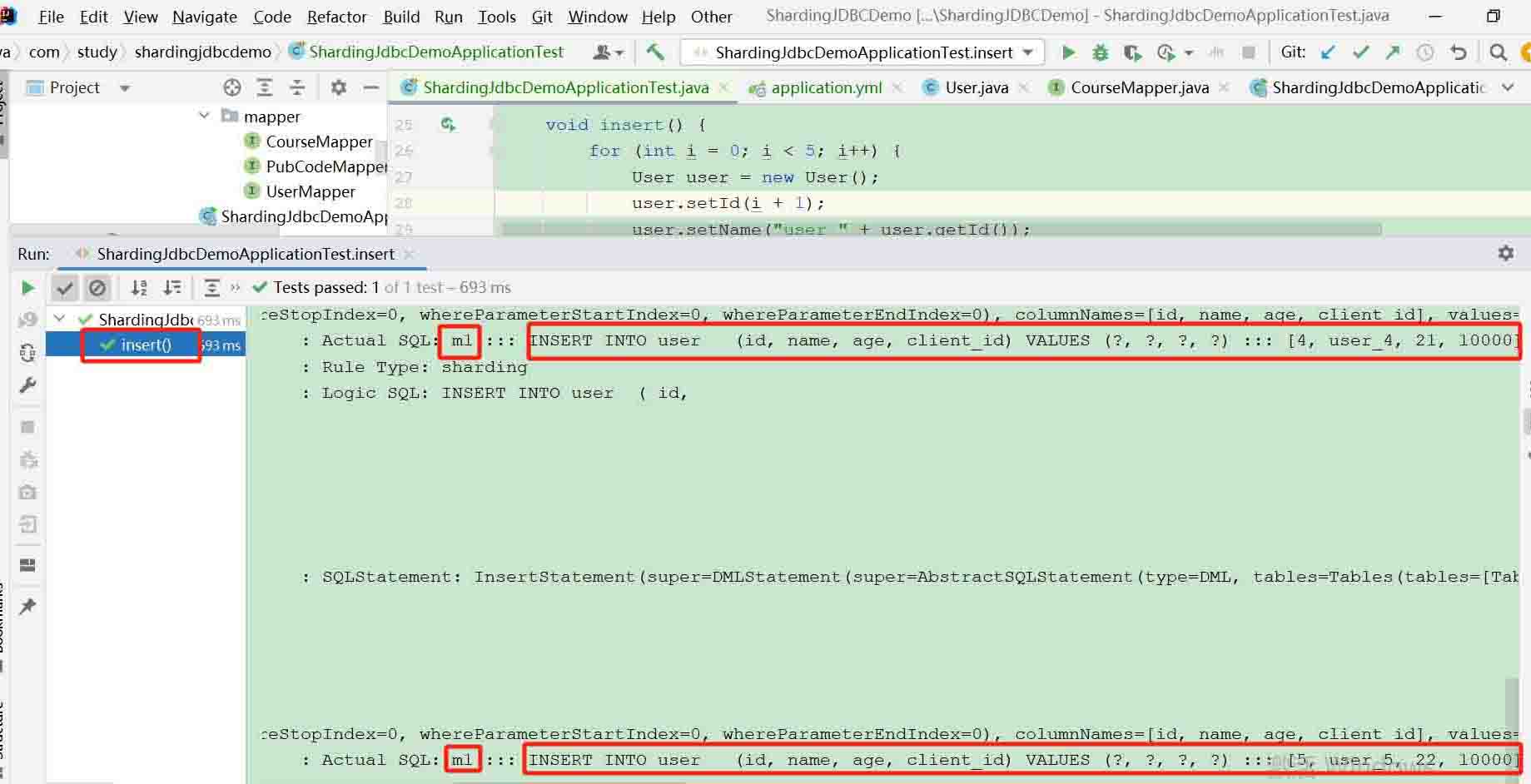
新增测试
- 测试类代码
@test
void insert() {
for (int i = 0; i < 5; i++) {
user user = new user();
user.setid(i + 1);
user.setname("user_" + user.getid());
user.setclientid(10000);
user.setage(18 + i);
usermapper.insert(user);
}
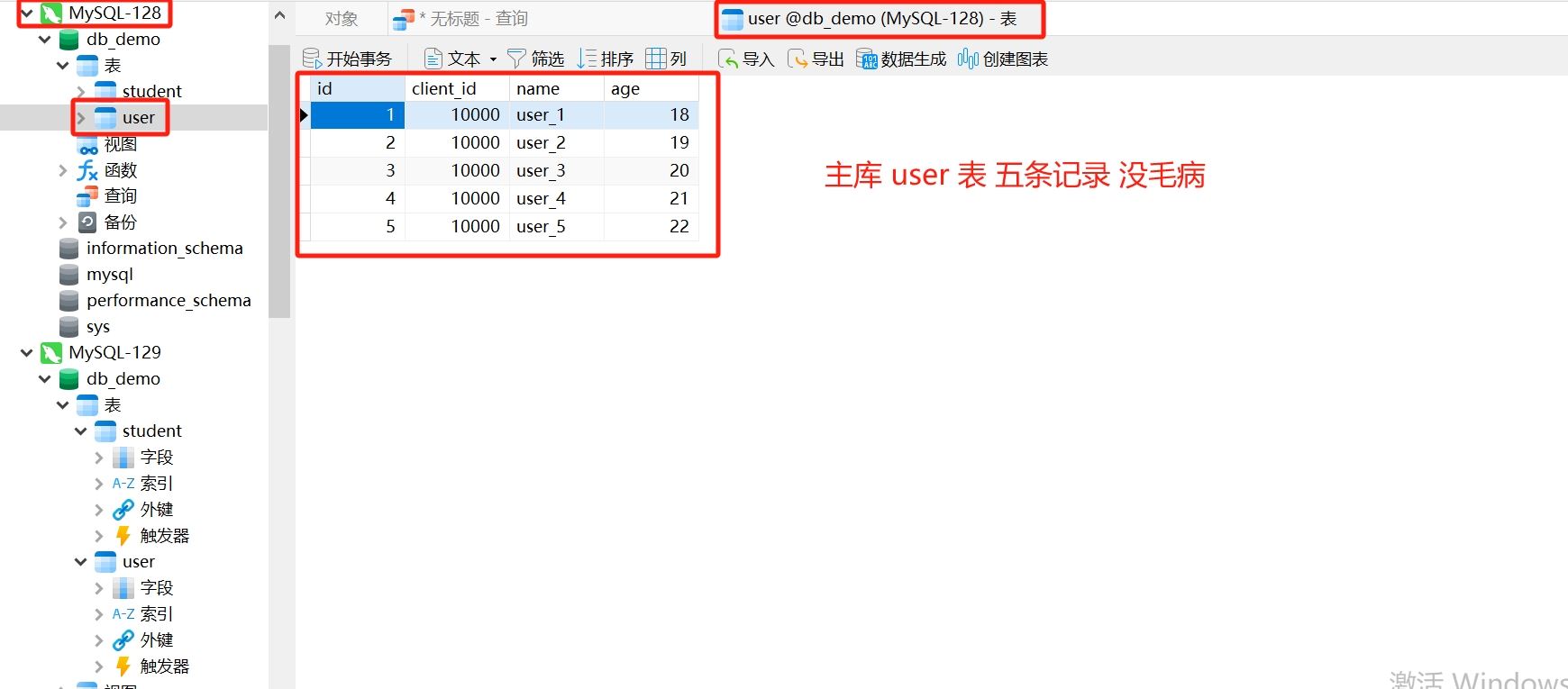
}- 运行结果
操作的必须是主库 对应的数据源 m1
主库查看
从库查看
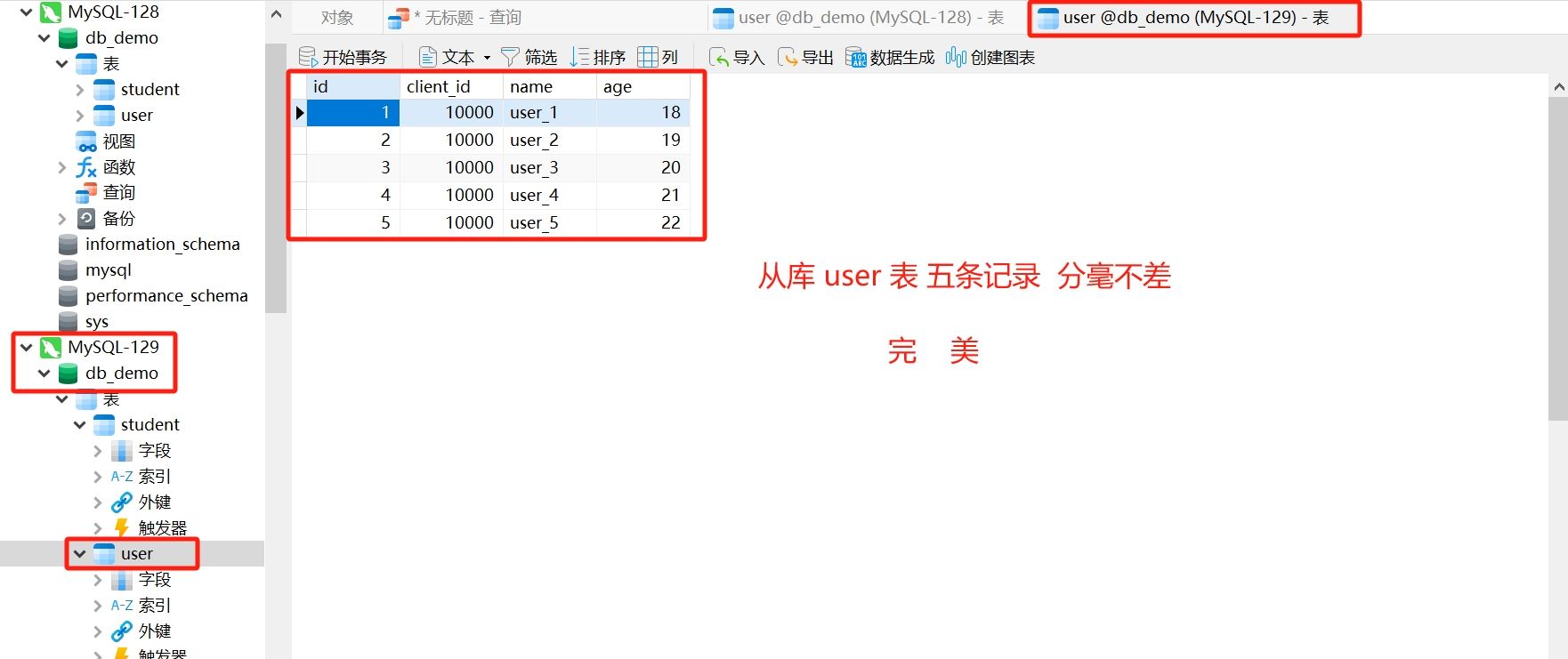
更新测试修改前
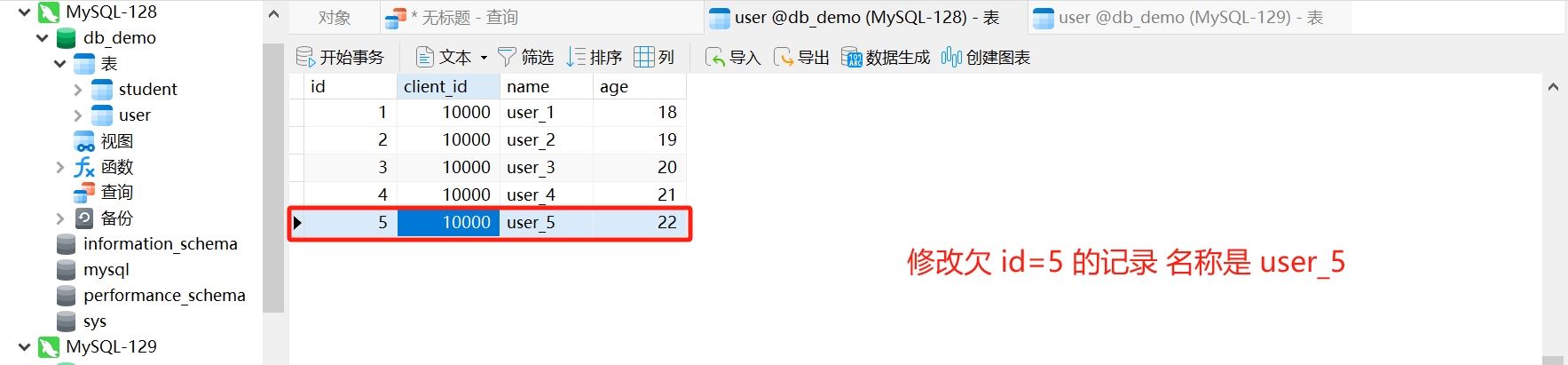
- 测试类代码
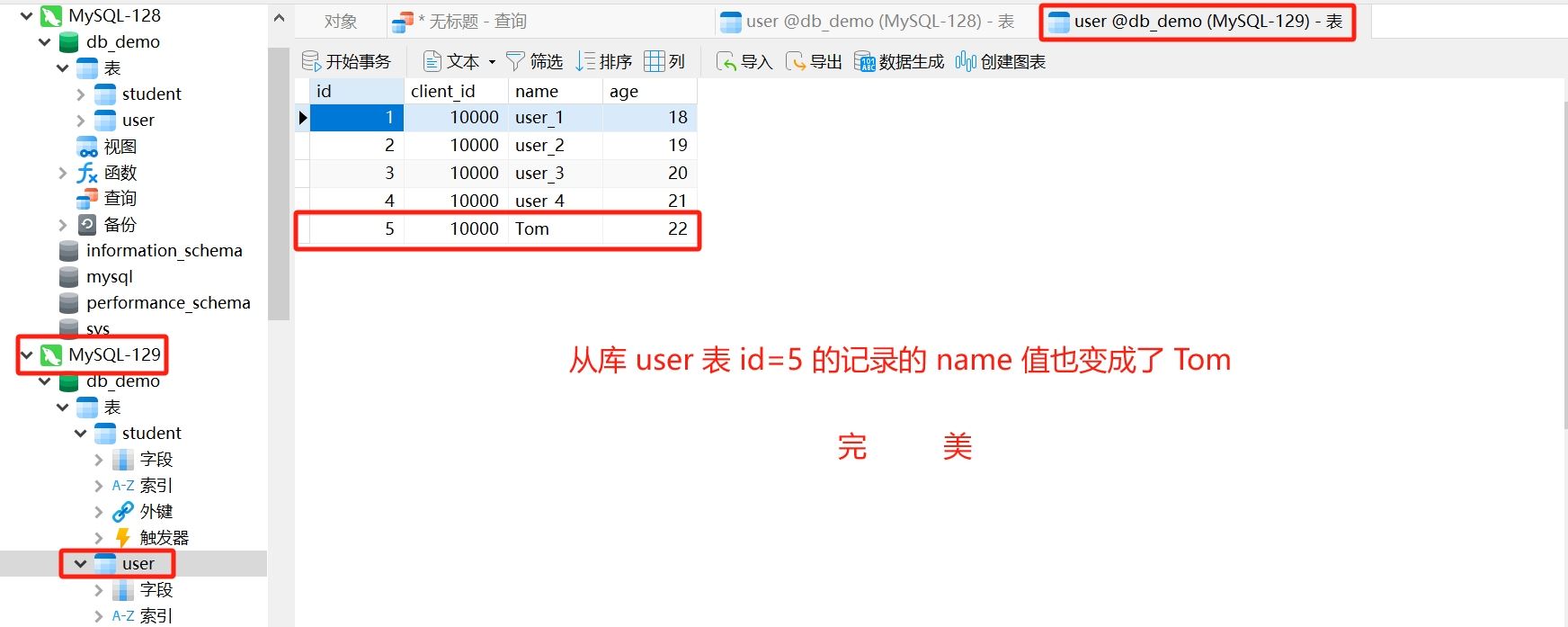
修改 id=5 的记录的 name, user_5 => tom
@test
void update() {
user user = new user();
user.setid(5);
user.setname("tom");
usermapper.updatebyid(user);
}- 运行结果
操作的必须是主库 对应的数据源 m1
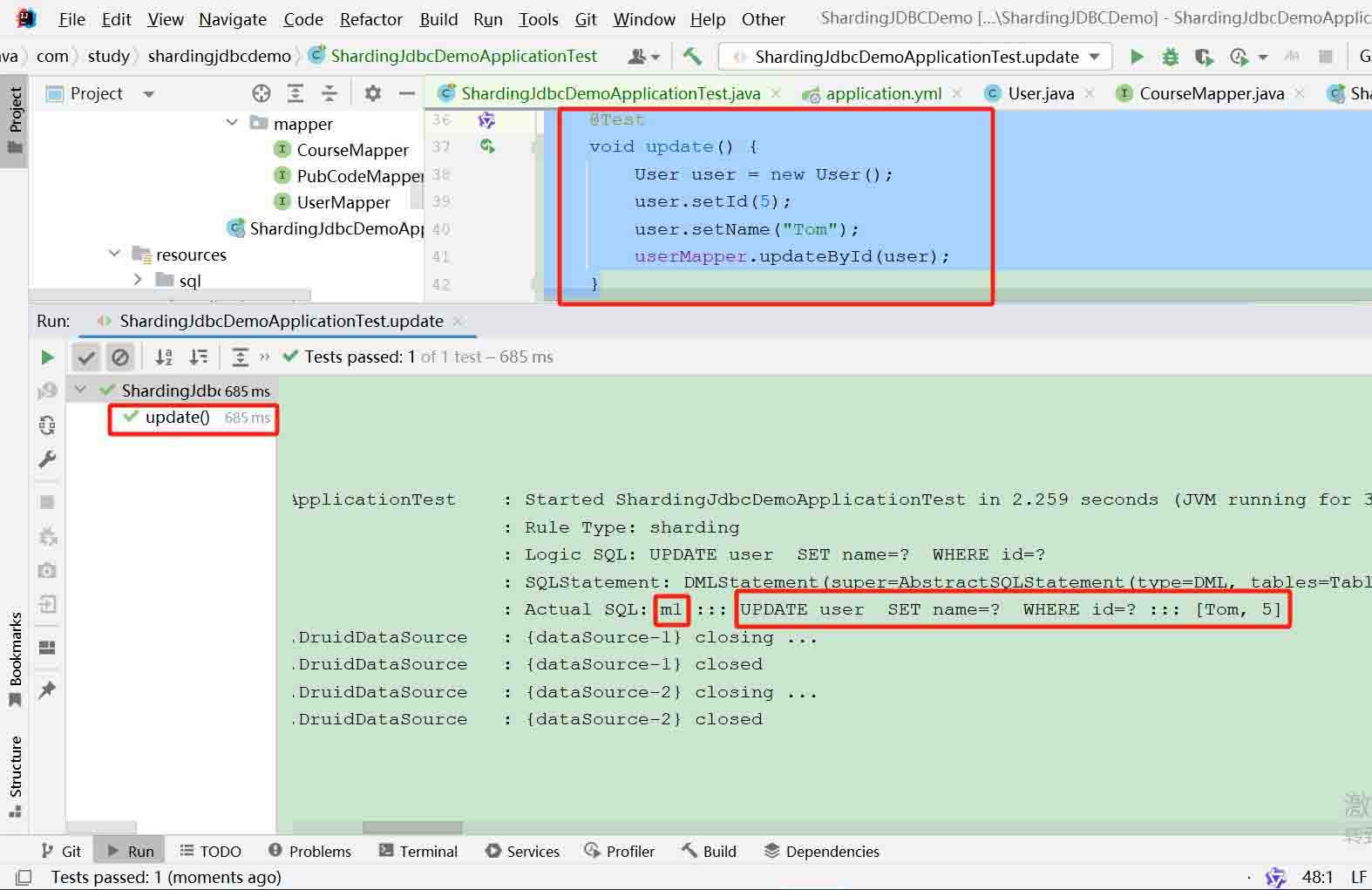
查看主库
查看从库
删除测试
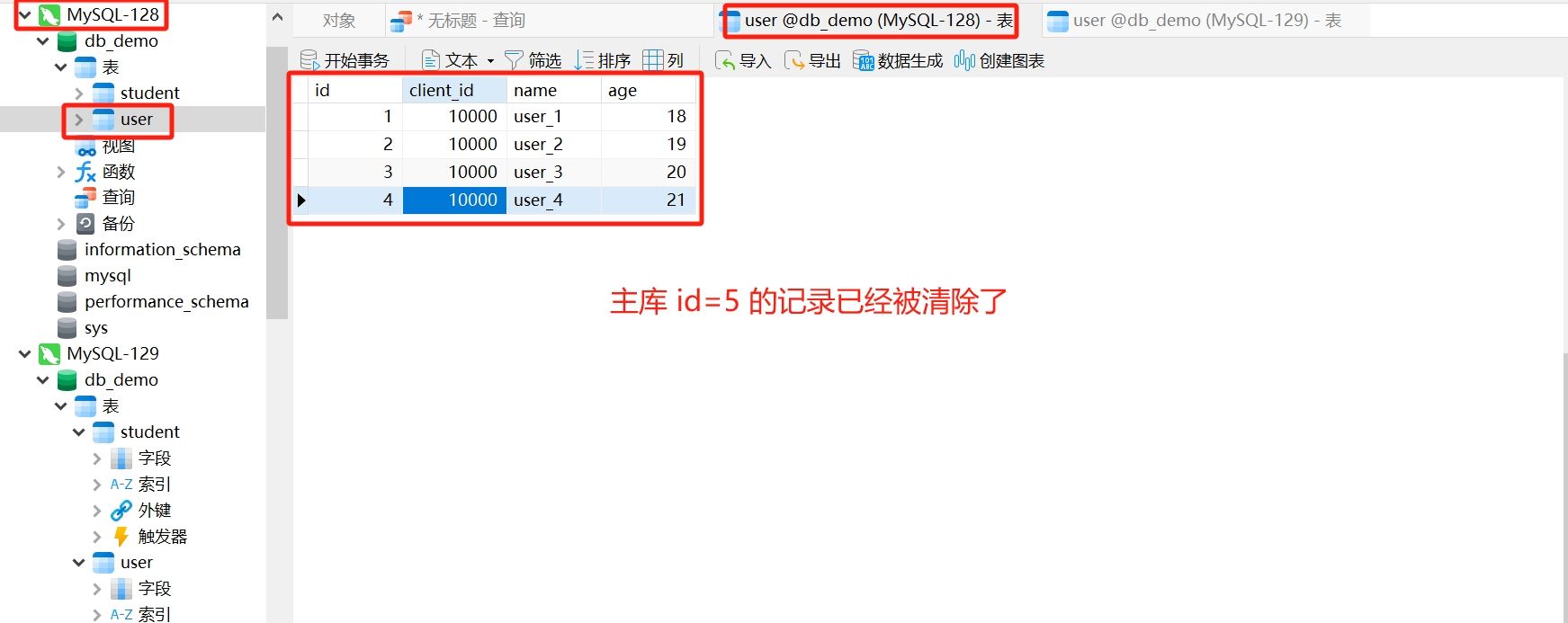
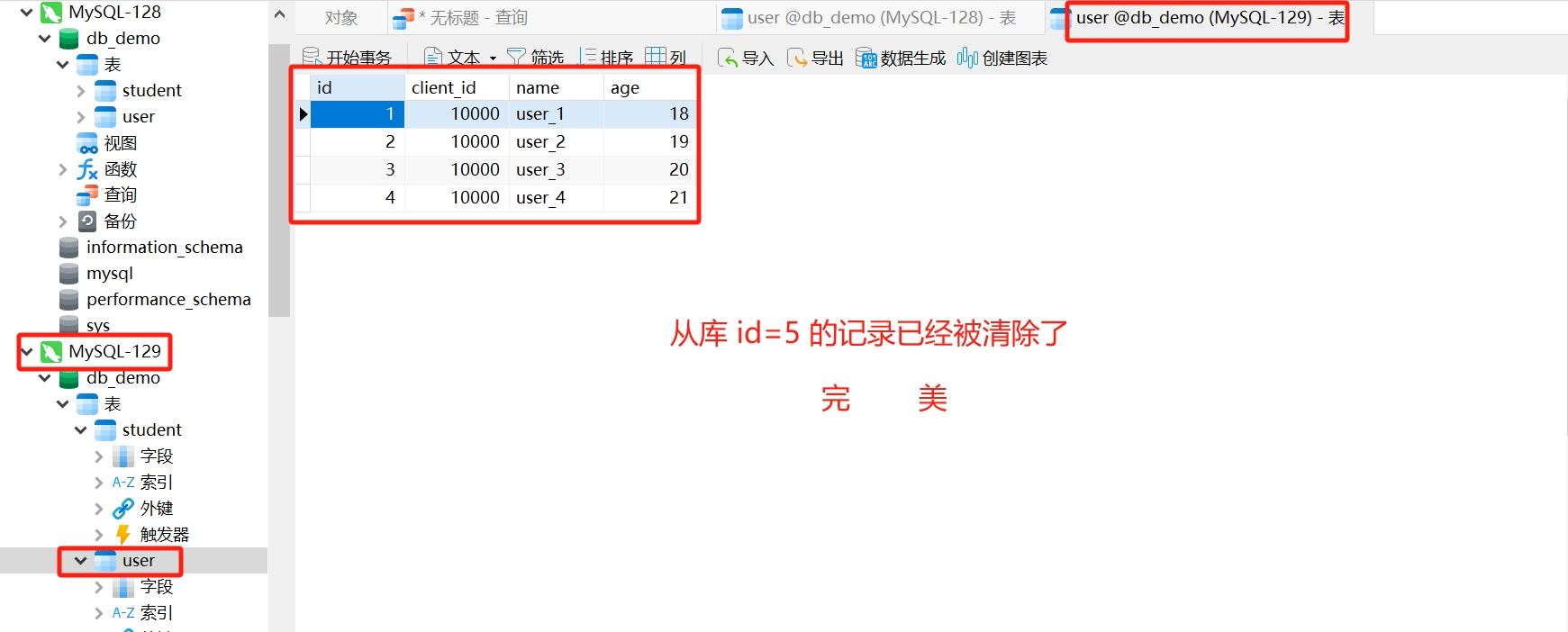
删除 id=5 的记录
- 测试代码
@test
void delete() {
usermapper.deletebyid(5);
}- 运行结果
操作的必须是主库 对应的数据源
m1
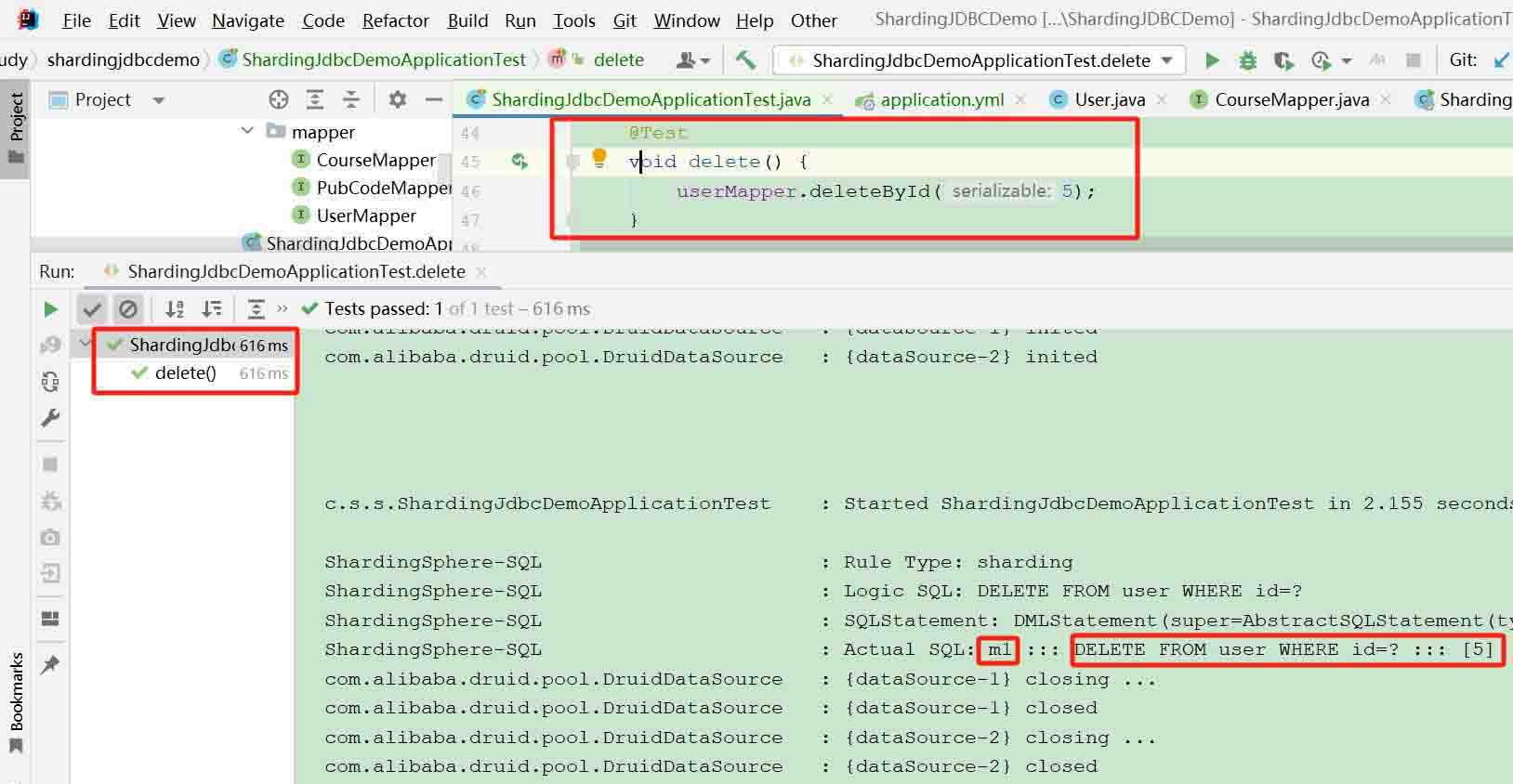
查看主库
查看从库
查询测试
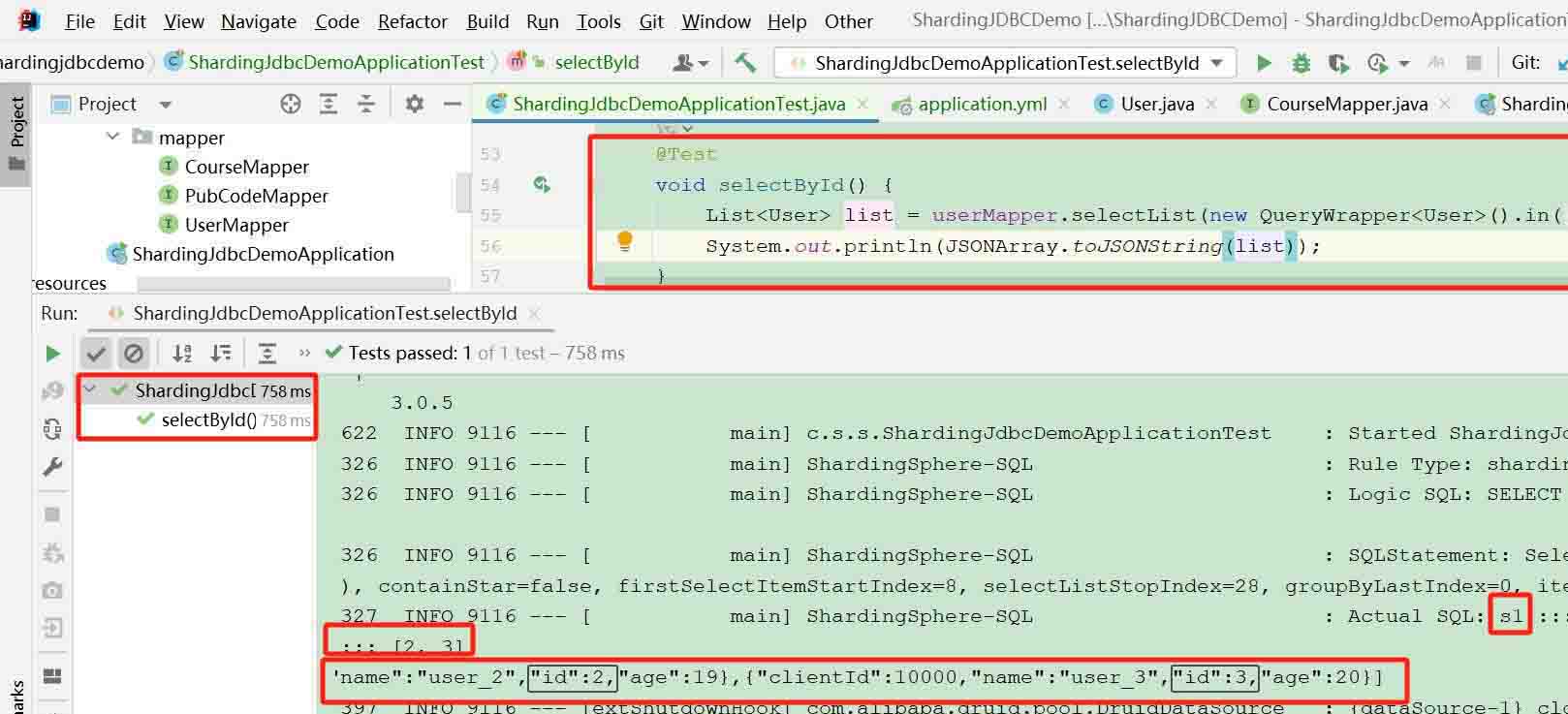
指定id查询,查找id为 2、3 的记录
- 测试代码
@test
void selectbyid() {
list<user> list = usermapper.selectlist(new querywrapper<user>().in("id", 2, 3));
system.out.println(jsonarray.tojsonstring(list));
}- 运行结果
操作的必须是从库 对应的数据源 s1
总结
- 完美的诠释了 读写分离
- 验证了 mysql主从集群的正确性
- 新增、更新、删除 都 操作主库 且 同步到从库
- 查询 只能操作 从库
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论