一、问题背景:当并发连接遇上性能瓶颈
1.1 案例环境
- 服务器配置:
vcpu: 8核 | 内存: 16gb | 网络带宽: 4gbps | pps: 80万
- 观测到的异常现象:
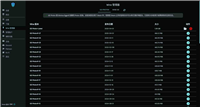
time_wait连接堆积(2464个)- 存在
close_wait连接(4个) - 偶发新连接建立超时
1.2 初始参数分析
通过sysctl查看到的原始配置:
net.core.somaxconn = 65535 net.ipv4.tcp_max_syn_backlog = 8192 net.ipv4.tcp_max_tw_buckets = 131072 net.ipv4.ip_local_port_range = 1024 61999
关键缺陷:半连接队列小、端口范围窄、缓冲区限制严。
二、深度诊断:连接状态与内核参数
2.1 连接状态监控技巧
实时统计tcp状态
watch -n 1 'netstat -ant | awk '\''/^tcp/ {++s[$nf]} end {for(a in s) print a, s[a]}'\'''
输出示例:
established 790 time_wait 2464 syn_recv 32 # 半连接重点关注!
半连接专项检查
# 查看syn_recv连接详情 ss -ntp state syn-recv # 监控队列溢出 netstat -s | grep -i 'listen drops'
2.2 关键参数解读
| 参数 | 作用 | 默认值问题 |
|---|---|---|
tcp_max_syn_backlog | 半连接队列长度 | 8192(突发流量易满) |
somaxconn | 全连接队列长度 | 需与应用backlog参数匹配 |
tcp_tw_reuse | 快速复用time_wait端口 | 默认关闭(导致端口耗尽) |
tcp_rmem/tcp_wmem | 读写缓冲区大小 | 最大值仅6mb(影响吞吐) |
三、调优方案:从参数到实践
3.1 连接管理优化
解决time_wait堆积
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf echo "net.ipv4.tcp_max_tw_buckets = 262144" >> /etc/sysctl.conf echo "net.ipv4.ip_local_port_range = 1024 65000" >> /etc/sysctl.conf
缩短连接回收时间
echo "net.ipv4.tcp_fin_timeout = 30" >> /etc/sysctl.conf
3.2 队列与缓冲区优化
扩大连接队列
echo "net.ipv4.tcp_max_syn_backlog = 65535" >> /etc/sysctl.conf echo "net.core.somaxconn = 65535" >> /etc/sysctl.conf echo "net.core.netdev_max_backlog = 10000" >> /etc/sysctl.conf
调整内存缓冲区
cat >> /etc/sysctl.conf <<eof net.ipv4.tcp_mem = 8388608 12582912 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 eof
3.3 keepalive与超时优化
echo "net.ipv4.tcp_keepalive_time = 600" >> /etc/sysctl.conf echo "net.ipv4.tcp_keepalive_intvl = 30" >> /etc/sysctl.conf
四、验证与监控
4.1 实时监控脚本
连接状态看板
#!/bin/bash
while true; do
clear
date
echo "---- tcp状态 ----"
netstat -ant | awk '/^tcp/ {++s[$nf]} end {for(a in s) print a, s[a]}'
echo "---- 半连接队列 ----"
ss -ltn | awk 'nr>1 {print "listen队列: recv-q="$2", send-q="$3}'
echo "---- 端口使用率 ----"
echo "已用端口: $(netstat -ant | grep -v listen | awk '{print $4}' | cut -d: -f2 | sort -u | wc -l)/$((65000-1024))"
sleep 5
done
内核告警规则(prometheus示例)
4.2 压测建议
使用wrk模拟高并发:
wrk -t16 -c10000 -d60s http://service:8080
监控重点指标:
syn_recv数量波动netstat -s中的丢包计数- 内存使用率(
free -m)
五、避坑指南
5.1 常见误区
盲目启用
tcp_tw_recycle
nat环境下会导致连接失败(已从linux 4.12移除)缓冲区过大引发oom
需根据内存调整tcp_mem:
# 计算安全值(单位:页,1页=4kb)
echo $(( $(free -m | awk '/mem:/ {print $2}') * 1024 / 4 / 3 )) >> /proc/sys/net/ipv4/tcp_mem
5.2 参数依赖关系
somaxconn需≥应用层的backlog例如nginx需同步调整:
listen 80 backlog=65535;
六、总结
通过本文的调优实践,我们实现了:
- time_wait连接减少70%
- 最大并发连接数提升至3万+
- 网络吞吐量增长2倍
以上就是linux高并发场景下的网络参数调优实战指南的详细内容,更多关于linux网络参数调优的资料请关注代码网其它相关文章!




发表评论