- 站内搜索
前言python的os模块(operating system)是提供给用户来与操作系统进行交互的内置库,可以用来进行文件和目录的管理操作。它提供了一系列函数,允许你创建、删除、重命…


前言如果你下载玩完python之后对python对它有了一定的了解,想要下载一些有趣的或者要用到的库比如pygame,pymysql等,那么就避免不了要使用python的自带的包下…
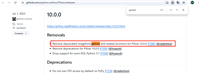
Pillow 移除或更改了 FreeTypeFont.getsize() 方法及问题解决方案

版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。
发表评论