redis pipeline 详解
redis 无 pipeline 耗时情况 :
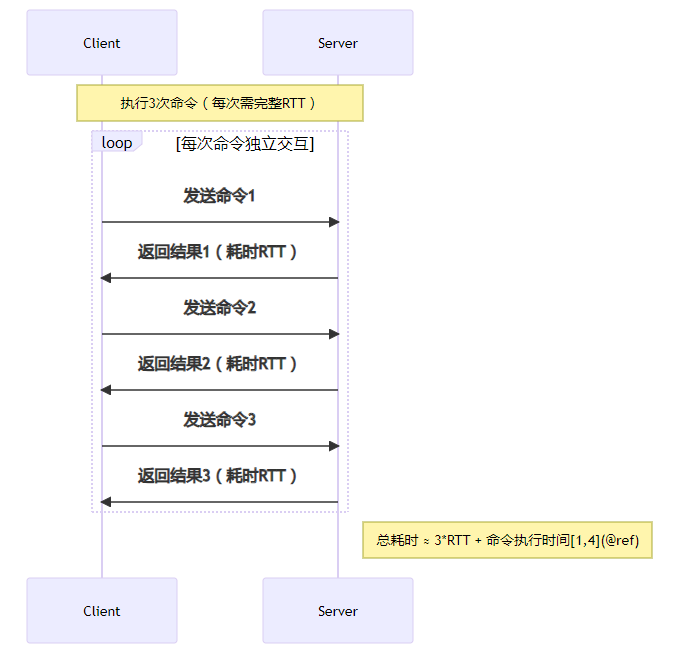
使用 pipeline 的耗时 :

1. pipeline 的核心概念
pipeline(管道) 是 redis 提供的一种批量执行命令的机制,通过将多个命令一次性发送到服务器并统一接收响应,减少网络往返次数(rtt) ,显著提升执行效率。其工作原理类似于快递打包运输:多个命令“打包”成一个网络包发送,而非逐条传输。
2. 工作原理与性能提升
- 传统模式:每条命令需经历 发送→排队→执行→返回 的完整流程,多次 rtt 导致高延迟(如跨机房场景下 rtt 达 13ms,每秒仅能处理约 80 条命令)。
- pipeline 模式:
- 批量发送:客户端缓存多个命令后一次性发送。
- 顺序执行:服务端依次执行命令并缓存结果,最后统一返回。
- 性能对比:假设 1 万次操作,单次 rtt 5ms,pipeline 耗时约 1.5 秒(传统模式需 51 秒)。
3. 核心优势
- 降低网络延迟:减少 rtt 次数,尤其在高延迟网络中效果显著。
- 提升吞吐量:单次网络 i/o 处理大量命令,减少用户态/内核态切换开销。
- 简化代码逻辑:避免重复建立连接和逐条处理响应。
4. 适用场景
- 批量数据操作:如批量插入/查询键值(如
set、hgetall)。 - 高并发读写:日志处理、实时统计等需快速执行大量命令的场景。
- 数据迁移与备份:结合
dump 命令批量导出数据。 - 非原子性批处理:允许部分失败(如短信群发,失败后补偿)。
5. 注意事项与限制
- 非原子性:pipeline 中的命令独立执行,不保证原子性(需原子性时用
multi/exec 事务)。 - 错误处理复杂:单个命令失败不影响后续执行,需客户端逐条检查结果。
- 命令数量限制:单次 pipeline 不宜过大(建议 100-1000 条),避免内存压力和网络阻塞。
- 集群限制:pipeline 所有命令需作用于同一 redis 节点,跨节点会报错。
6. 与原生批命令(mget/mset)的区别
| 特性 | 原生批命令 | pipeline |
|---|---|---|
| 原子性 | 支持(如mget整体成功/失败) | 不支持,命令逐个执行 |
| 命令类型 | 单一命令多键操作(如mget) | 支持多类型命令混合 |
| 实现层级 | 服务端实现 | 客户端与服务端协作 |
7. 代码示例(java)
python 语言:
with r.pipeline() as pipe:
pipe.set('key1', 'value1')
pipe.set('key2', 'value2')
results = pipe.execute() # 返回 [true, true]java(jedis) :
pipeline pipeline = jedis.pipelined();
pipeline.set("k1", "v1");
pipeline.set("k2", "v2");
list<object> responses = pipeline.syncandreturnall(); // 获取所有结果8. 最佳实践
- 合理分批次:超大量命令拆分为多个 pipeline 执行。
- 避免滥用:少量命令时直接执行可能更高效。
- 监控内存:服务端需监控 pipeline 队列内存占用。
9 .redis pipeline 与原生批量操作命令
原子性
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| 原子性 | 非原子,命令逐个执行 | 原子性,所有键操作视为整体 |
| 错误处理 | 单个命令失败不影响后续命令 | 语法错误导致全体失败,运行时错误部分执行(如类型错误) |
命令类型与灵活性
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| 支持命令类型 | 可混合不同类型命令(如set+hget) | 仅支持特定单一命令(如mget仅用于获取多个键值) |
| 应用范围 | 任意命令组合 | 仅限特定批量命令(如mget、mset、hmset等) |
性能与网络开销
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| 网络往返次数(rtt) | 单次 rtt(批量发送所有命令) | 单次 rtt(原生命令本身是单个请求) |
| 性能瓶颈 | 网络延迟越大,提升越显著(如跨机房场景) | 单次请求已优化,性能稳定但受限于命令类型 |
集群兼容性
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| redis cluster 支持 | 需确保所有命令的 key 位于同一哈希槽,否则报错 | 需手动拆分跨槽命令,或依赖客户端自动重定向 |
| 数据一致性 | 无额外保障 | 需自行维护 key 与槽的映射关系(如crc16计算) |
内存与错误处理
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| 内存占用 | 命令队列占用服务端内存,需控制批量大小(建议 100-1000 条) | 单次请求内存消耗较低,直接执行无缓存 |
| 错误响应 | 需逐个检查结果列表中的错误 | 直接返回整体结果或错误信息 |
适用场景对比
| 特性 | pipeline | 原生批量命令(mget/mset等) |
|---|---|---|
| 内存占用 | 命令队列占用服务端内存,需控制批量大小(建议 100-1000 条) | 单次请求内存消耗较低,直接执行无缓存 |
| 错误响应 | 需逐个检查结果列表中的错误 | 直接返回整体结果或错误信息 |
总结
- pipeline 优势:灵活、高吞吐、适合非原子性批量操作,尤其在高延迟网络中效果显著。
- 原生批量命令优势:原子性、语法简洁、适合简单跨键操作。
- 混合使用建议:在事务中结合 pipeline 减少网络开销(如
multi/exec 包裹 pipeline)。
到此这篇关于redis pipeline(管道) 详解的文章就介绍到这了,更多相关redis pipeline 详解内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论