在当今数据驱动的技术生态中,json、xml和yaml作为主流结构化数据格式,因其层次化表达能力和跨平台兼容性,已成为系统间数据交换的通用载体。然而,当需要将这类半结构化数据转化为具备直观可视化、动态计算和协作共享特性的载体时,excel文件因其在商业分析、科研管理和跨部门协作中的不可替代性,成为数据落地的终极界面。通过python实现这一转换过程,不仅能突破不同数据范式间的语义鸿沟,更可构建自动化数据管道,在保留原始数据完整性的同时,赋予其动态排序、公式计算和数据透视等增值能力。本文将介绍如何使用python导入json、xml和yaml格式数据到excel文件中。
本文所使用的数据写入方法需要用到free spire.xls for python,pypi:pip install spire.xls.free。
如何使用python写入数据到excel工作表
我们可以使用free spire.xls for python提供的类、属性和方法来创建或载入excel文件,并处理数据到单元格的写入以及工作表格式设置等操作。以下是操作步骤示例:
- 创建workbook实例以新建excel工作簿(新建的工作簿会有三个默认工作表),或使用workbook.loadfromfile()方法载入已有工作簿。
- 使用workbook.worksheets.get_item()方法获取指定工作表,或使用workbook.worksheets.add(sheetname: str)方法直接新建工作表。
- 通过json、xml.etree.elementtree和yaml组件读取相应数据。
- 使用worksheet.range.get_item()方法获取指定单元格为cellrange对象,并使用cellrange.value属性讲数据写入单元格中。
- 使用cellrange.builtinstyle、cellrange.applystyle()、worksheet.autofitcolumn()等属性和方法,对工作表及单元格格式进行设置。
- 使用workbook.savetofile()方法保存excel工作簿到文件。
用python导入json数据到excel工作表
json是一种轻量级数据交换格式,常用于web应用中前后端数据传输。在python中,我们可以使用标准库中的json内置组件来解析json文件,并提取其中数据。提取到数据之后,我们可以使用spire.xls for python将其写入excel工作表并自定义格式,完成json数据到excel文件的导入。
代码示例:
# 导入所需库
from spire.xls import workbook, fileformat, builtinstyles
import json
# 读取并解析json订单数据
with open("e-commerce order data.json", "r", encoding="utf-8") as f:
jsondata = json.load(f)
# 定义excel列标题
headers = ["order_id", "customer", "order_date", "status", "total", "product", "quantity", "price"]
# 将嵌套的json结构转换为扁平化表格数据
rows = []
for order in jsondata:
for item in order["items"]:
# 合并订单主数据和商品明细数据
row = [
order["order_id"], order["customer"], order["order_date"],
order["status"], str(order["total"]), item["product"],
str(item["quantity"]), str(item["price"])
]
rows.append(row)
# 初始化excel工作簿和工作表
workbook = workbook()
workbook.worksheets.clear()
sheet = workbook.worksheets.add("orders")
# 写入表头到首行
for col, header in enumerate(headers):
sheet.range[1, col + 1].value = header
# 写入数据行内容
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.range[row_idx + 2, col_idx + 1].value = value
# 设置表格样式
sheet.rows[0].builtinstyle = builtinstyles.heading2 # 标题行样式
for row in range(1, sheet.rows.count):
sheet.rows[row].builtinstyle = builtinstyles.accent2_40 # 数据行样式
# 自动调整列宽
for col in range(sheet.columns.count):
sheet.autofitcolumn(col + 1)
# 保存并释放资源
workbook.savetofile("output/jsontoexcel.xlsx", fileformat.version2016)
workbook.dispose()为了演示清晰,以上代码直接基于已知的字段结构进行提取。在实际项目中,建议根据具体的数据格式动态处理字段,或增加容错逻辑以应对结构变动。
json文件:
输出excel文件:

用python导入xml数据到excel工作表
xml是一种标记语言,适合表示结构复杂的数据,支持丰富的功能(如属性、注释)。同样,python标准库也提供了xml.etree.elementtree组件,可以帮助我们提取xml文件中的数据。我们可以使用该组件搭配free spire.xls for python来实现导入xml数据到excel文件。
代码示例:
# 导入xml处理库和excel操作库
import xml.etree.elementtree as et
from spire.xls import workbook, fileformat, builtinstyles
# 解析xml变更日志文件
tree = et.parse("software manual changelog.xml")
root = tree.getroot()
# 定义表格列标题
headers = ["version", "date", "editor", "change"]
rows = []
# 提取并转换xml数据结构
for entry in root.findall("entry"):
# 提取公共字段
version = entry.findtext("version", "")
date = entry.findtext("date", "")
editor = entry.findtext("editor", "")
# 展开多个变更条目为独立行
for change in entry.find("changes").findall("change"):
rows.append([version, date, editor, change.text.strip()])
# 创建excel工作簿
workbook = workbook()
workbook.worksheets.clear()
sheet = workbook.worksheets.add("changelog")
# 写入表格标题行
for col, header in enumerate(headers):
sheet.range[1, col + 1].value = header
# 填充变更记录数据
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.range[row_idx + 2, col_idx + 1].value = value
# 应用样式模板
sheet.rows[0].builtinstyle = builtinstyles.heading1 # 主标题样式
for row in range(1, sheet.rows.count):
sheet.rows[row].builtinstyle = builtinstyles.accent1_40 # 交替行底色
# 自适应列宽设置
for col in range(sheet.columns.count):
sheet.autofitcolumn(col + 1)
# 输出文件并释放资源
workbook.savetofile("output/xmltoexcel.xlsx", fileformat.version2016)
workbook.dispose()
为了演示清晰,以上代码直接基于已知的字段结构进行提取。在实际项目中,建议根据具体的数据格式动态处理字段,或增加容错逻辑以应对结构变动。
xml文件:
输出的excel文件:
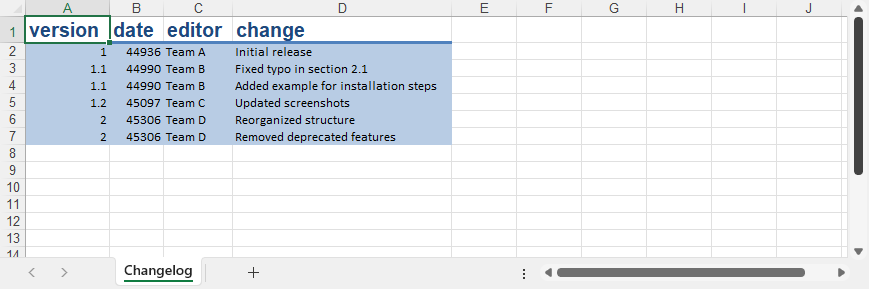
用python导入yaml数据到excel工作表
yaml是一种简洁易读的配置文件格式,常用于devops和项目配置。虽然yaml通常不用于存储表格型数据,但很多结构化配置可转换成excel表做审阅、记录或共享等,在这些实际场景中非常实用。我们可以使用python标准库中的yaml组件处理yaml文件数据,然后将其导入excel文件中。
代码示例:
# 导入yaml处理库和excel操作库
import yaml
from spire.xls import workbook, fileformat, builtinstyles
# 加载ci/cd流水线配置文件
with open("ci cd pipeline configuration.yaml", "r", encoding="utf-8") as f:
yaml_data = yaml.safe_load(f) # 安全解析yaml内容
# 定义流水线分析报表列结构
headers = ["stage", "command", "output_file", "coverage", "environment"]
rows = []
# 展开流水线阶段的多维数据
for stage in yaml_data["stages"]:
# 提取阶段基础信息
name = stage.get("name", "")
commands = stage.get("commands", [])
coverage = str(stage.get("coverage", "")) # 数值转字符串
environment = stage.get("environment", "")
outputs = stage.get("artifacts", []) or [""] # 处理空输出文件情况
# 按命令展开明细行
for i, cmd in enumerate(commands):
# 合并数据时保持指标数据首行展示
row = [
name,
cmd,
outputs[i] if i < len(outputs) else "", # 匹配命令与产出文件
coverage if i == 0 else "", # 覆盖率仅首行保留
environment if i == 0 else "" # 环境信息仅首行保留
]
rows.append(row)
# 创建报表工作簿
workbook = workbook()
workbook.worksheets.clear()
sheet = workbook.worksheets.add("pipeline")
# 构建表头结构
for col, header in enumerate(headers):
sheet.range[1, col + 1].value = header
# 填充动态生成的流水线数据
for row_idx, row_data in enumerate(rows):
for col_idx, value in enumerate(row_data):
sheet.range[row_idx + 2, col_idx + 1].value = str(value) # 强制转为字符串格式
# 应用阶梯式样式方案
sheet.rows[0].builtinstyle = builtinstyles.heading4 # 深色渐变标题
for row in range(1, sheet.rows.count):
sheet.rows[row].builtinstyle = builtinstyles.accent2_40 # 浅色交替行背景
# 优化列显示宽度
for col in range(sheet.columns.count):
sheet.autofitcolumn(col + 1)
# 持久化报表文件
workbook.savetofile("output/yamltoexcel.xlsx", fileformat.version2016)
workbook.dispose()
为了演示清晰,以上代码直接基于已知的字段结构进行提取。在实际项目中,建议根据具体的数据格式动态处理字段,或增加容错逻辑以应对结构变动。
yaml文件:

输出的excel文件:
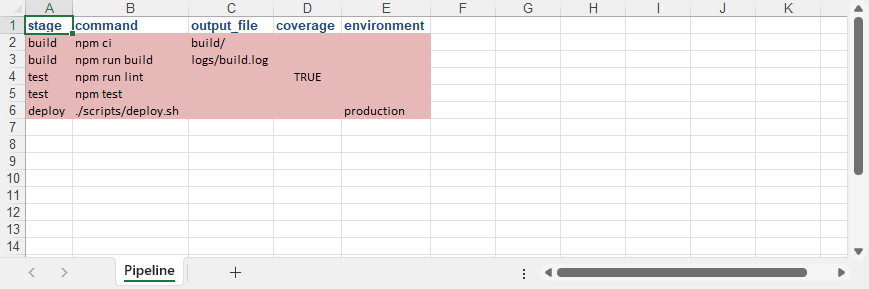
本文演示如何导入数据到excel文件,包括json、xml和yaml数据到excel工作表的导入,提供步骤介绍及代码示例。
到此这篇关于使用python将json,xml和yaml数据写入excel文件的文章就介绍到这了,更多相关python数据写入excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论