脚本文件取名keras报错
keras已经被pip安装好了,但是仍然无法继续使用,尝试添加函数, 重新安装keras都没能成功,最后看到一篇文章上写的是脚本命名问题,经过尝试后,解决好了这个问题。
具体报错记录如下:
no module named 'keras.datasets'; 'keras' is not a package
解决办法:
(1).修改项目脚本中的命名,脚本不能叫keras,否则报错。
(2).重新下载keras的包
pip install keras tensorflow==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/ --default-timeout=100
使用过程找不到对应包模块
使用pip list 发现对应模块和安装包都在,但是无法调用该模块
思考过是该包缺少什么函数或是缺少什么依赖
后在网上找到说是包的版本过高
兼容性问题导致,因此将该包进行了升级
解决了该包模块无法找到的问题
attributeerror: module 'tensorflow' has no attribute 'get_default_graph'
解决办法:
将包卸载,找keras和tensorflow匹配版本的包,这里我是将keras的包进行了升级解决
tensorflow-gpu安装
之前使用过cpu的tensorflow,这次的目的是使用gpu版本的,并要对tensorflow的可视化进行一个新的展示,完成自己之前在tensorflow的bp和卷积神经网络的验证。
tensorflow的gpu版本安装,我先卸载了cpu的tensorflow,理由是网上说如果不删除,python程序将默认使用cpu的tensorflow进行,在安装过程中尝试了30分钟
最终安装的解决方法如下:
使用安装命令为:
pip install tensorflow-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple/ --default-timeout=100
d:\python\python_data2_project>pip install tensorflow-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple/ --default-timeout=100
tensorflow和keras的案例运行
下面代码是摘自网络,成功运行如下:
import numpy as np
import os
import tensorflow
from keras.models import sequential
from keras.layers import dense
# 随机生成一组数据
data = np.random.random((1000,100))
# 随机生成标签
labels = np.random.randint(2,size=(1000,1))
model = sequential()
# 添加一层神经网络
model.add(dense(32,
activation='relu',
input_dim=100))
# 添加激活函数(activate function)
model.add(dense(1, activation='sigmoid'))
# 构建模型,定义优化器及损失函数
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 模型与数据一键fit
model.fit(data,labels,epochs=10,batch_size=32)
predictions = model.predict(data)
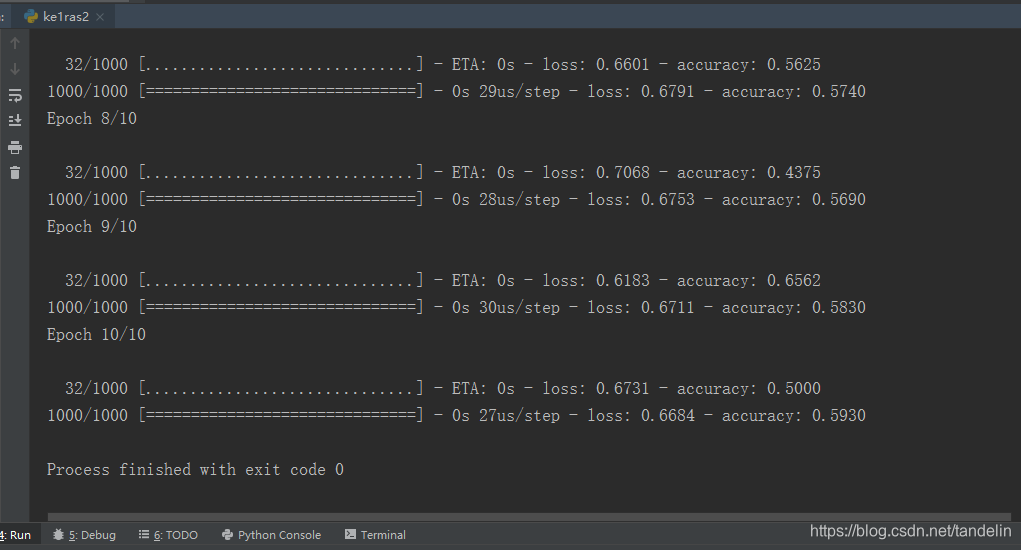
通过上面的损失函数的最终结果,可以看出模型的效果并不是很好。
tensorflow的gpu设置运行
电脑显卡类型不支持,暂时未进行验证,后续持续验证
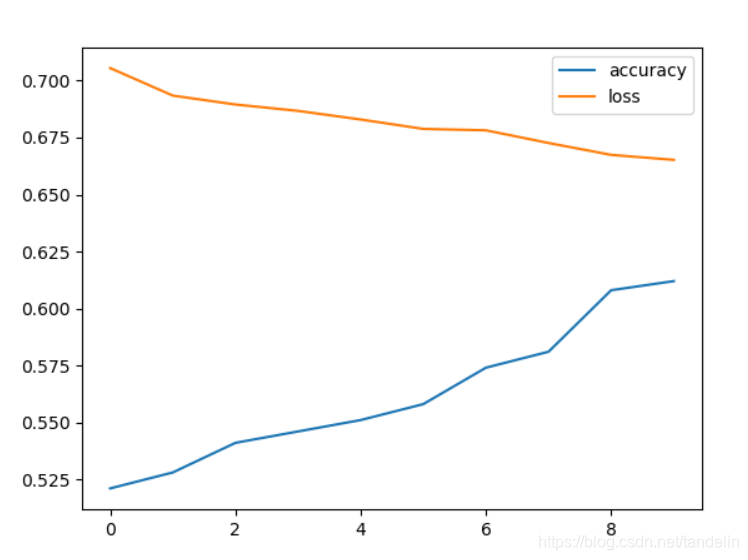
绘制损失函数
hist=model.fit(data,labels,epochs=10,batch_size=32) plt.plot(hist.history['accuracy'],label="accuracy") plt.plot(hist.history['loss'],label="loss") plt.legend(loc=0, ncol=1) # 参数:loc设置显示的位置,0是自适应;ncol设置显示的列数 plt.show()
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论