所需工具:
- idea
- spire.ocr for java - java ocr组件,支持识别多种语言、字体,可读取jpg、png、gif、bmp 和 tiff 等常用图片中的文本信息。
产品包下载链接:下载 | spire.ocr for java
或从maven仓库导入:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupid>e-iceblue</groupid>
<artifactid>spire.ocr</artifactid>
<version>1.9.0</version>
</dependency>
</dependencies>- 其余依赖文件。按操作系统下载对应文件后,解压缩至指定的文件路径。
提取码:nw77
java ocr识别图片文本的实现步骤
1. 在idea中新建一个项目并导入spire.ocr.jar。
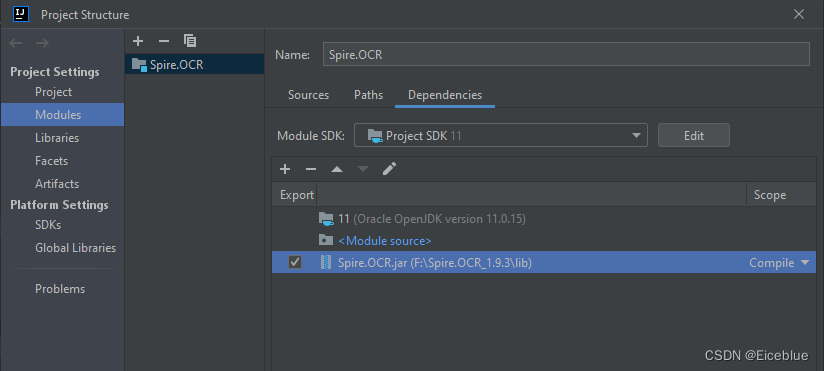
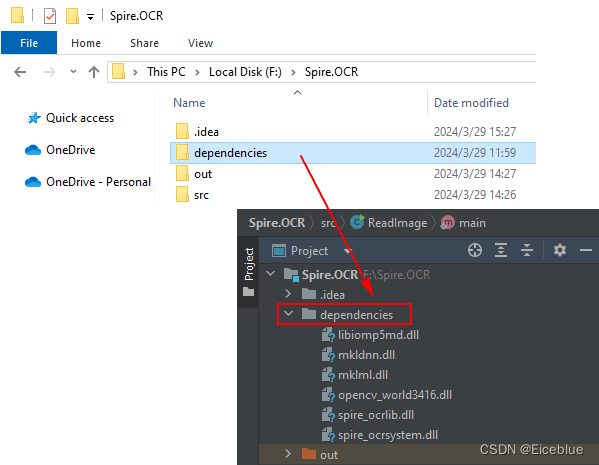
2. 将刚才下载解压缩后的 “dependencies” 文件夹复制到idea项目目录下。
3.确保导入以上所需依赖后,运行以下代码实现扫描读取图片中的文本。
import com.spire.ocr.ocrscanner;
import java.io.*;
public class readimage {
public static void main(string[] args) throws exception {
//指定依赖文件的路径
string dependencies = "f:\\dependencies\\";
//指定要需要扫描的图片的路径
string imagefile = "图片.png";
//指定输出文件的路径
string outputfile = "读取图片.txt";
//创建ocrscanner对象,并设置其依赖文件路径
ocrscanner scanner = new ocrscanner();
scanner.setdependencies(dependencies);
//扫描指定的图像文件
scanner.scan(imagefile);
//获取扫描的文本内容
string scannedtext = scanner.gettext().tostring();
//创建输出文件对象
file output = new file(outputfile);
//如果输出文件已经存在,则将其删除
if (output.exists()) {
output.delete();
}
//创建bufferedwriter对象来将扫描的文本内容写入输出文件
bufferedwriter writer = new bufferedwriter(new filewriter(outputfile));
writer.write(scannedtext);
writer.close();
}
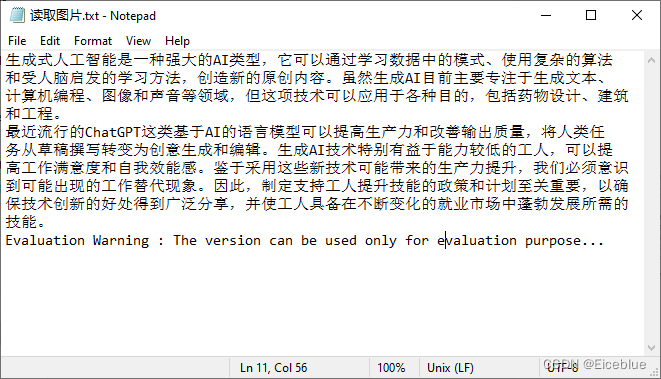
}示例图片:

ocr图片扫描结果:
ocr识别流程
概括
传统的ocr基于图像处理(二值化、连通域分析、投影分析等)和统计机器学习(adaboost、svm),过去20年间在印刷体和扫描文档上取得了不错的效果。传统的印刷体ocr解决方案整体流程如图。

从输入图像到给出识别结果经历了图像预处理、文字行提取和文字行识别三个阶段。
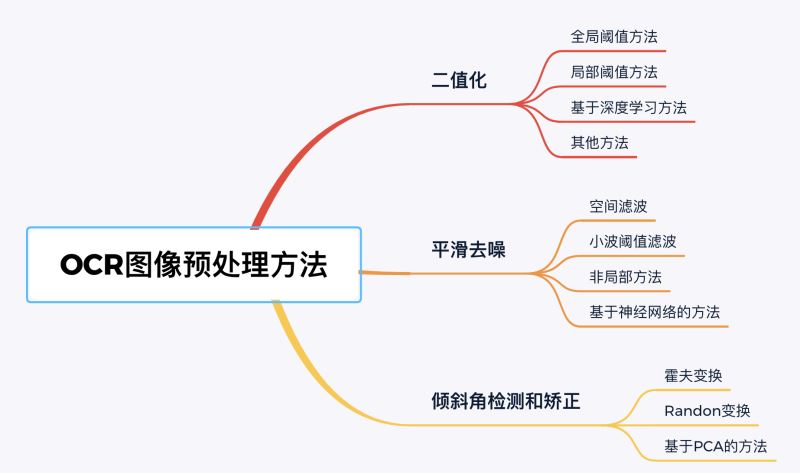
图像预处理
- 二值化:由于彩色图像所含信息量过于巨大,在对图像中印刷体字符进行识别处理前,需要对图像进行二值化处理,使图像只包含黑色的前景信息和白色的背景信息,提升识别处理的效率和精确度
- 图像降噪:由于待识别图像的品质受限于输入设备、环境、以及文档的印刷质量,在对图像中印刷体字符进行识别处理前,需要根据噪声的特征对待识别图像进行去噪处理,提升识别处理的精确度
- 倾斜校正:由于扫描和拍摄过程涉及人工操作,输入计算机的待识别图像或多或少都会存在一些倾斜,在对图像中印刷体字符进行识别处理前,就需要进行图像方向检测,并校正图像方向。
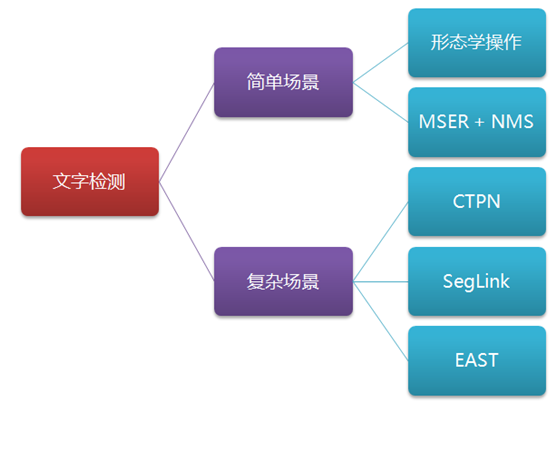
文字检测
文字检测主要有两条线,两步法和一步法。
- 两步法:faster-rcnn.
- 一步法:yolo。相比于两步法,一步法速度更快,但是accuracy有损失。
文字检测按照文字的角度分。
- 水平文字检测:四个自由度,类似于物体检测。水平文字检测比较好的算法是ctpn。
- 倾斜文字检测:文本框是不规则的四边形,八个自由度。倾斜文字检测个人比较喜欢的方法是cvpr的east和seglink。
文本识别
在以前的ocr任务中,识别过程分为两步:单字切割和分类任务。
现今基于深度学习的端到端ocr技术有两大主流技术:crnn ocr和attention ocr。
其实这两大方法主要区别在于最后的输出层(翻译层),即怎么将网络学习到的序列特征信息转化为最终的识别结果。
这两大主流技术在其特征学习阶段都采用了cnn+rnn的网络结构,crnn ocr在对齐时采取的方式是ctc算法,而attention ocr采取的方式则是attention机制。

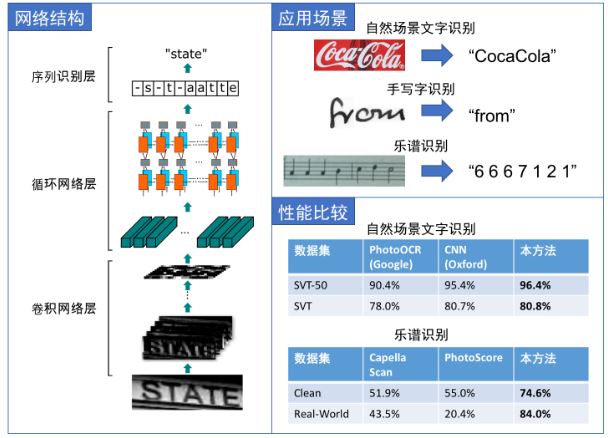
网络结构包含三部分,从下到上依次为:
- 卷积层,使用cnn,作用是从输入图像中提取特征序列;
- 循环层,使用rnn,作用是预测从卷积层获取的特征序列的标签(真实值)分布;
- 转录层,使用ctc,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;
到此这篇关于java中实现ocr识别读取图片中的文字的文章就介绍到这了,更多相关java ocr识别内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论