sqlalchemy 链接数据库使用数据库连接池技术,原理是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的链接,而是从链接池中取出一个已建立的空闲链接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而链接的建立,断开都由链接池来管理,同时,还可以通过设置链接池的参数来控制链接池中的初始链接数,链接的上下限数以及每个链接的最大使用次数,最大空闲时间等。
1. 安装
安装sqlalchemy
pip install sqlalchemy
安装mysql
pip install pymysql
2. 创建数据库引擎
示例:
from sqlalchemy import create_engine engine = create_engine(mysql_url, echo=true, pool_size=5, max_overflow=4, pool_recycle=7200, pool_timeout=30)
echo=true: 这表示在执行 sql 查询时会输出所有 sql 语句及其参数到控制台,方便调试。
pool_size=5: 这设置了数据库连接池的大小为 5,表示在连接池中最多可以保持 5 个连接。
max_overflow=4: 这允许在需要时,连接池外再创建最多 4 个额外的连接,超出连接池大小的部分会在使用后关闭。
pool_recycle=7200: 这表示连接在 7200 秒(2 小时)后会被回收,避免因长时间连接而导致的问题(例如,mysql 的“互动超时”)。
pool_timeout=30: 这是连接池的超时时间,表示如果在 30 秒内没有获取到可用的连接,将会抛出异常。
3. 新建表,增删改查demo
配置文件:
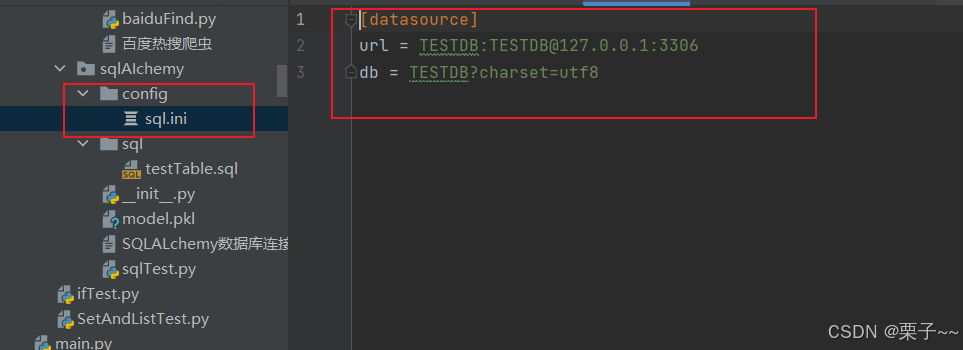
sql.ini:
[datasource] url = testdb:testdb@127.0.0.1:3306 db = testdb?charset=utf8
python demo:
from sqlalchemy import create_engine, column, string, integer, datetime, index, text
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import pathlib
import configparser
# 设置配置文件
current_dir = pathlib.path(__file__).parent
config_file = current_dir / 'config' / 'sql.ini'
config = configparser.configparser()
with open(config_file, 'r', encoding='utf-8') as f:
config.read_file(f)
url = config['datasource']['url']
db = config['datasource']['db']
mysql_url = f'mysql+pymysql://{url}/{db}'
# 创建数据库引擎
"""
echo=true: 这表示在执行 sql 查询时会输出所有 sql 语句及其参数到控制台,方便调试。
pool_size=5: 这设置了数据库连接池的大小为 5,表示在连接池中最多可以保持 5 个连接。
max_overflow=4: 这允许在需要时,连接池外再创建最多 4 个额外的连接,超出连接池大小的部分会在使用后关闭。
pool_recycle=7200: 这表示连接在 7200 秒(2 小时)后会被回收,避免因长时间连接而导致的问题(例如,mysql 的“互动超时”)。
pool_timeout=30: 这是连接池的超时时间,表示如果在 30 秒内没有获取到可用的连接,将会抛出异常。
"""
engine = create_engine(mysql_url, echo=true, pool_size=5, max_overflow=4, pool_recycle=7200, pool_timeout=30)
base = declarative_base()
# 设置会话
session = sessionmaker(bind=engine)
session = session()
# 表结构
class yzytest(base):
__tablename__ = 't_yzy_test'
sequence_no = column(integer, primary_key=true, autoincrement=true, comment='序列号')
pk_std_point_ai_relation = column(string(36), unique=true, nullable=false, comment='id')
fk_std_audit_point = column(string(36), nullable=false, comment='审核标准id')
fk_ai_std = column(string(36), nullable=false, comment='aiid')
channel_tag = column(string(45), nullable=false, comment='渠道')
fk_user_create = column(string(36), nullable=true, comment='创建人id')
user_name_create = column(string(64), nullable=true, comment='创建人姓名')
create_time = column(datetime, default=text('current_timestamp'), nullable=false, comment='创建时间')
__table_args__ = (
index('u_t_yzy_test_01', 'fk_std_audit_point', 'fk_ai_std', 'channel_tag', unique=true),
)
# 创建表
def create_table():
base.metadata.create_all(engine)
# 查询数据
def query():
return session.query(yzytest).all()
# 插入数据
def save(param):
session.add(param)
session.commit()
# 更新数据
def update(param_id, updated_data):
param = session.query(yzytest).filter(yzytest.pk_std_point_ai_relation == param_id).first()
if param:
for key, value in updated_data.items():
setattr(param, key, value)
session.commit()
# 删除数据
def delete(param_id):
param = session.query(yzytest).filter(yzytest.pk_std_point_ai_relation == param_id).first()
if param:
session.delete(param)
session.commit()
if __name__ == '__main__':
create_table()
# 示例用法:
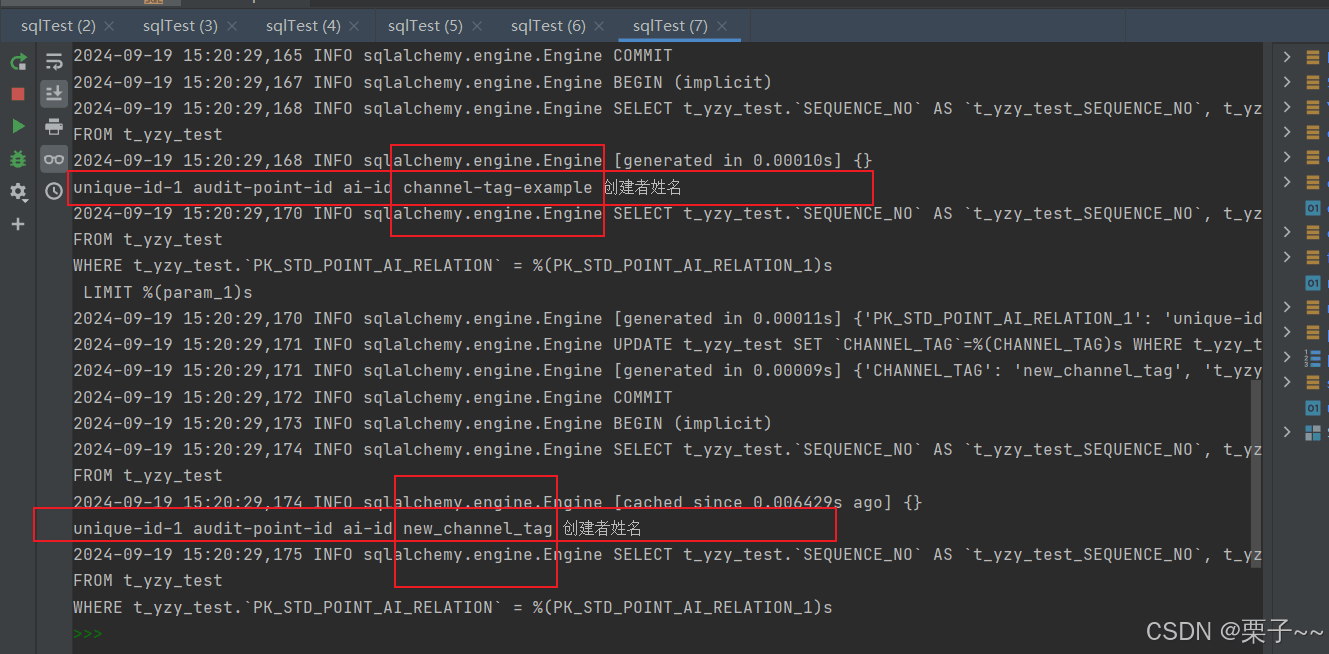
new_param = yzytest(
pk_std_point_ai_relation='unique-id-1',
fk_std_audit_point='audit-point-id',
fk_ai_std='ai-id',
channel_tag='channel-tag-example',
user_name_create='创建者姓名'
)
save(new_param)
params = query()
for param in params:
print(param.pk_std_point_ai_relation, param.fk_std_audit_point, param.fk_ai_std, param.channel_tag, param.user_name_create)
update('unique-id-1', {'channel_tag': 'new_channel_tag'})
params = query()
for param in params:
print(param.pk_std_point_ai_relation, param.fk_std_audit_point, param.fk_ai_std, param.channel_tag, param.user_name_create)
delete('unique-id-1')
测试:

到此这篇关于python sqlalchemy 数据库连接池的实现的文章就介绍到这了,更多相关python sqlalchemy连接池内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论